
## 一、概述
```
nginx.conf
```
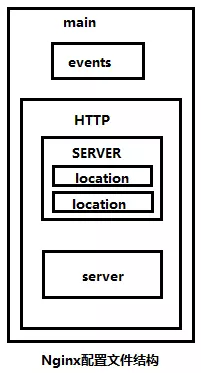
配置文件主要由四部分组成:main(全区设置),server(主机配置),upstream(负载均衡服务器设置),和location(URL匹配特定位置设置)。
## 二、反向代理部署
后端的web应用部署在tomcat中,假定访问地址:
```
http://192.168.3.149:8080
```
首先配置上游服务器(http{}段):
```
upstream backend {
server www.ray.org:8099;
}
```
server 中配置(server{}段):
```
location / {
root html;
index index.html index.htm;
proxy_pass http://backend;
}
location ~ .* {
proxy_pass http://backend;
proxy_set_header Host $http_host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Fonwarded-For $proxy_add_x_forwarded_for;
}
```
即可实现在浏览器输入:`http://localhost/`,转发到地址`http://www.ray.org:8099`
## 三、前后端分离部署
前端部署在nginx,后端部署在tomcat等服务容器的情形;
与反向代理部署类似:
首先配置上游服务器(http{}段):
```
upstream backend {
server www.ray.org:8090; //假定后端服务部署的端口为8090
}
```
server 中增加配置(server{}段):
```
location /api {
proxy_pass http://backend/api;
}
```
- 前言
- 01、系统平台
- 术语字典
- 技术术语
- 业务术语
- 系统管理
- 组织类型
- 单位管理
- 基本功能
- SAAS功能
- 组织管理
- 角色管理
- 人员管理
- 账号管理
- 账户体系
- 账号绑定
- 账号锁定
- 团队管理
- 模板管理
- 补丁管理
- 字段管理
- 静态字典
- 动态字典
- 系统配置
- 菜单配置
- 路由配置
- 编码规则
- 访问控制
- 系统参数
- 字典配置
- 参数定义
- 参数配置
- 属性定义
- 属性设置
- 树形定义
- 树形设置
- 系统监控
- 业务维护
- 工作监控
- 调度监控
- 导入监控
- 日志管理
- 在线监控
- 附件管理
- 附件监控
- 附件应用
- 附件授权
- 上传监控
- 字段监控
- 系统提醒
- 场景配置
- 事件监控
- 提醒记录
- 事件历史
- 日期设置
- 节假日期
- 工作时间
- 日历编制
- 工作日历
- 开放平台
- 微信应用
- 配置信息
- 更新菜单
- 钉钉应用
- 配置信息
- 开放服务
- 应用设置
- 服务管理
- 请求监控
- 请求跟踪
- 移动应用
- 发布管理
- 导航菜单
- 个人管理
- 个人资料
- 内部消息
- 短信中心
- 流程管理
- 流程定义
- 流程环节
- 处理人
- 流程提醒
- 流程签收
- 流程目录
- 流程微调
- 转移动作
- 定义校验
- 流程绑定
- 流程实体设定
- 单业务多流程
- 动态表单绑定
- 环节字段设定
- 转移路由设定
- 流程监控
- 流程催办
- 流程会话
- 流程启动
- 通用待办
- 流程驱动
- 通用已办
- 示范实例
- 流程启动
- 流程待办
- 流程已办
- 常见问题
- 表单管理
- 预留字段
- 字段定义
- 业务应用
- 动态辅表
- 辅表定义
- 辅表应用
- 辅表监控
- 动态主表
- 主表定义
- 业务定义
- 元数据
- 产生机制
- 应用场景
- 技术平台
- 02、基础模块
- 基础设置
- 物料类型
- 仓库管理
- 汇率管理
- 公司设置
- 账期设置
- 单据打印
- 单据导出
- 基础资料
- 物料管理
- 初始库存导入
- 成本
- 副产品
- 工艺
- 单位
- 供应商
- 客户
- 二维码
- 条码
- 注销
- 删除
- 客户管理
- 供应商管理
- 03、通用规则
- 单据业务
- 审批流程
- 锁定规则
- 静态字典
- 04、物料清单
- 清单编制
- 分类清单
- 分层清单
- 清单启用
- 清单审核
- 清单启用
- 清单查询
- 历史清单
- 分阶查询
- 清单维护
- 替代公式
- 批量维护
- 05、库存模块
- 库存操作
- 入库管理
- 新增入库
- 修改入库
- 入库审核
- 出库管理
- 新增出库
- 修改出库
- 出库审核
- 盘点管理
- 新增盘点
- 修改盘点
- 盘点审核
- 调拨管理
- 新增调拨
- 修改调拨
- 调拨审核
- 库存查询
- 明细查询
- 汇总查询
- 按库查询
- 按批查询
- 单据查询
- 入库查询
- 出库查询
- 盘点查询
- 调拨查询
- 库存检测
- 库存检测
- 检测历史
- 动态库存
- 06、销售模块
- 销售订单
- 订单管理
- 新增订单
- 修改订单
- 订单审核
- 订单查询
- 订单监控
- 订单修正
- 销货管理
- 销货开单
- 基于订单销货
- 基于客户销货
- 销货管理
- 销货修改
- 查看打印
- 销货审批
- 销货查询
- 退货管理
- 退货开单
- 退货管理
- 修改退货
- 查看打印
- 退货审批
- 退货查询
- 业务规则
- 标记设定
- 07、采购模块
- 采购计划
- 计划管理
- 依请购新增
- 依订单新增
- 计划审核
- 计划采购
- 计划监控
- 采购订单
- 订单管理
- 手动发起
- 采购计划
- 订单审核
- 订单查询
- 订单监控
- 订单修正
- 到货管理
- 采购到货
- 发起采购单到货
- 发起供应商到货
- 到货管理
- 到货审核
- 到货查询
- 退货管理
- 采购退货
- 退货管理
- 退货审核
- 退货查询
- 业务规则
- 超到逻辑
- 标记设定
- 08、生产管理
- 工序管理
- 工序定义
- 路线定义
- 工序看板
- 工单管理
- 生产类型
- 核心算法
- 工单编制
- 订单需求创建
- 手工直接创建
- 工单审核
- 工单查询
- 制料查询
- 工单监控
- 生产领料
- 新增领料
- 领料管理
- 领料审核
- 领料查询
- 生产退料
- 新增退料
- 退料管理
- 退料审核
- 退料查询
- 生产转移
- 启动转移
- 转移处理
- 转移日志
- 工单跟踪
- 条码监控
- 生产入库
- 相关算法
- 新增入库
- 入库管理
- 入库审核
- 入库查询
- 生产退回
- 新增退回
- 退回管理
- 退回审核
- 退回查询
- 09、质量管理
- 检验管理
- 检验发起
- 新增检验
- 编辑检验
- 结果录入
- 检验审核
- 检验查询
- 10、批次模块
- 批号管理
- 批号生成
- 应用场景
- 批次库存
- 11、财务模块
- 应收管理
- 对账管理
- 基于订单
- 手工新增
- 对账审核
- 对账监控
- 收款管理
- 对账收款
- 收款管理
- 收款审核
- 对账开票
- 发票管理
- 发票审核
- 应付管理
- 对账管理
- 基于订单
- 手工新增
- 对账审核
- 对账监控
- 付款管理
- 对账支付
- 支付管理
- 支付审核
- 对账收票
- 发票管理
- 发票审核
- 成本核算
- 物料成本
- 生产成本
- 12、任务管理
- 任务发起
- 项目管理
- 我的任务
- 任务调度
- 任务监控
- 任务查询
- 任务维护
- 任务执行
- 我的待办
- 我的已办
- 13、人力资源
- 基础资料
- 社会保险
- 公积金
- 人事管理
- 人员档案
- 转正管理
- 转正待办
- 离职管理
- 离职待办
- 奖惩管理
- 奖惩待办
- 变动管理
- 变动待办
- 考勤管理
- 班次设定
- 打卡管理
- 薪资管理
- 工资项目
- 工资方案
- 工资造表
- 工资结果
- 招聘管理
- 简历管理
- 面试管理
- 福利管理
- 社保方案
- 公积金方案
- 商业保险
- 培训管理
- 培训教材
- 培训机构
- 培训讲师
- 培训申请
- 人事关系
- 保险理赔
- 14、协同办公
- 记事管理
- 记事本
- 历史记事
- 备忘管理
- 备忘录
- 我的备忘
- 历史备忘
- 日程管理
- 我的日程
- 组织日程
- 信息管理
- 信息采编
- 信息管理
- 信息查看
- 文件管理
- 文件分组
- 文件查询
- 文件浏览
- 财务流程
- 借款申请
- 借款待办
- 报销申请
- 报销待办
- 核销申请
- 核销待办
- 付款申请
- 付款待办
- 发票申请
- 发票待办
- 行政流程
- 请假申请
- 请假待办
- 出差申请
- 出差待办
- 工作报告
- 我的报告
- 报告查询
- 15、无线呼叫
- 硬件配置
- 工位设备
- 服务定义
- 报文管理
- 呼叫器报文
- 呼叫应答报文
- 应答器报文
- 应答反馈报文
- 业务处理
- 呼叫待办
- 呼叫管理
- 业务查询
- 呼叫看板
- 呼叫查询
- 16、条码管理
- 条码设置
- 相关设置
- 生成规则
- 条码生成
- 条码管理
- 条码资料
- 条码监控
- 条码查询
- 条码操作
- 扫码关联
- 条码关联
- 条码盘转
- 二维码
- 溯源系统
- 17、客户关系
- 销售漏斗
- 名单收集
- 名单分配
- 名单跟踪
- 我的名单
- 我的历史
- 名单筛选
- 历史名单
- 客户管理
- 客户公海
- 客户资料
- 转正式
- 人员
- 项目
- 评价
- 我的客户
- 团队客户
- 分享客户
- 分配管理
- 客户分配
- 团队分配
- 分配记录
- 跟进管理
- 客户跟进
- 跟进批示
- 我的批示
- 跟进记录
- 销售日报
- 我的日报
- 团队日报
- 批示日报
- 日报查询
- 客户评价
- 指标定义
- 评价查询
- 18、外勤模块
- 考勤管理
- 考勤时间
- 考勤打卡
- 拜访管理
- 拜访计划
- 拜访记录
- 活动管理
- 活动记录
- 19、外贸模块
- 报关管理
- 报关商品
- 报关要素
- 报关发起
- 报关审核
- 报关管理
- 20、合同模块
- 预报价单
- 我的预报价
- 预报价审核
- 预报价查询
- 报价管理
- 客户报价
- 报价审核
- 报价管理
- 我的报价
- 合同签约
- 订金管理
- 合同签订
- 合同审核
- 财务复核
- 合同管理
- 合同收款
- 合同收款
- 收款复核
- 合同查询
- 合同查询
- 变更记录
- 21、项目管理
- 整体设计
- 核心业务
- 附件设计
- 相关配置
- 项目计划
- 项目模板
- 项目立项
- 项目计划
- 项目属性
- 任务属性
- 项目执行
- 立项审批
- 填报审核
- 任务执行
- 填报流程
- 我的已办
- 分解发布
- 项目监控
- 任务查询
- 项目查询
- 项目跟踪
- 项目干预
- 任务干预
- 项目文件
- 22、服务管理
- 服务定义
- 服务定义
- 服务运行
- 服务目录
- 服务待办
- 服务监控
- 服务已办
- 服务查询
- 我的服务
- 23、查询统计
- 人员范围
- 单据查询
- 报表查询
- 图表查询
- 24、业务监控
- 单据监控
- 清单监控
- 实体监控
- 价格历史
- 25、报表打印
- 简明指引
- 报表设计
- 技术教程
- 通用设计
- 单据设计
- 库存相关单据
- 采购相关单据
- 销售相关单据
- 生产相关单据
- 常见问题
- 26、手机应用
- 参数配置
- 技术平台
- 功能设计
- 系统功能
- 应用升级
- 业务模块
- 27、微信应用
- 参数配置
- 多公众号
- 技术平台
- 业务功能
- 平台功能
- 微信客服
- 微信公号
- 28、开放服务
- 接入示例
- 实施方案
- nginx安装
- nginx配置
- nginx运行
- nginx限流
- 实现方案
- 业务操作
- 代码示意
- 29、产品实施
- 简明指引
- 实施流程
- 实施过程
- 文档模板
- 表格模板
- 方案纲要
- 系统安装
- 部署方案
- 单独tomcat部署
- nginx+tomcat部署
- 安装过程
- 主体应用
- 调度服务器
- 工作服务器
- 自动备份
- 系统升级
- 主体应用
- 实施期升级
- 维护期升级
- 调度服务器
- 工作服务器
- 实施培训
- 实施风险
- 常见问题
- 30、产品发布
- 测试方案
- 发布方案
- 31、常见问题
- 性能优化
- 启动优化
- 解决方案
- 实体操作冲突
- 算法说明
- 检验算法
- 注意事项
- 浏览器
- 插件
- 邮箱配置
- 系统维护
- 维护日志
- 维护脚本
- 开发环境
- 32、版本记录
- 研发进程
- 更新日志
- 规划记录
- 33、版权信息
- 平台版权
- 产品版权
- 后记