
### 数据分布
分布式数据库首先要解决把整个数据集按照分区规则映射到多个节点的问题,即把数据集划分到多个节点上,每个节点负责整体数据的一个子集。
### 数据分布有两种方式
#### 1 顺序分区
顺序分布就是把一整块数据分散到很多机器中,如下图所示。
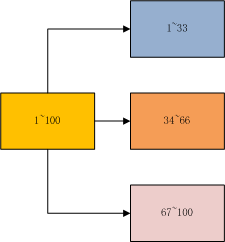
正常顺序分区是按照平均分配的规则,当然也可以根据不同机器分配,内存大一点的可以多分配一些。
#### 2.哈希分区。
如下图所示,1~100这整块数字,通过 hash 的函数,取余产生的数。这样可以保证这串数字充分的打散,也保证了均匀的分配到各台机器上。
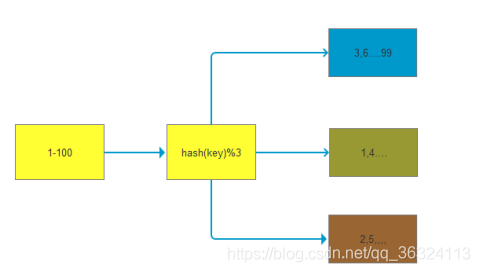
哈希分布和顺序分布只是场景上的适用。哈希分布不能顺序访问,比如你想访问1~100,哈希分布只能遍历全部数据,同时哈希分布因为做了 hash 后导致与业务数据无关了。
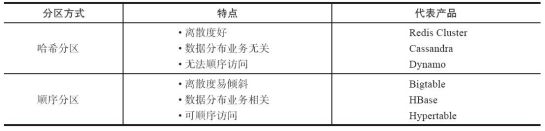
### 数据倾斜与数据迁移跟节点伸缩
顺序分布是会导致数据倾斜的,主要是访问的倾斜。每次点击会重点访问某台机器,这就导致最后数据都到这台机器上了,这就是顺序分布最大的缺点。
但哈希分布其实是有个问题的,当我们要扩容机器的时候,专业上称之为“节点伸缩”,这个时候,因为是哈希算法,会导致数据迁移。
### 哈希分区方式
#### 1、节点取余分区
使用特定的数据(包括redis的键或用户ID),再根据节点数量N,使用公式:hash(key)%N计算出一个0~(N-1)值,用来决定数据映射到哪一个节点上。即哈希值对节点总数取余。余数x,表示这条数据存放在第(x+1)个节点上。
缺点:当节点数量N变化时(扩容或者收缩),数据和节点之间的映射关系需要重新计算,这样的话,按照新的规则映射,要么之前存储的数据找不到,要么之前数据被重新映射到新的节点(导致以前存储的数据发生数据迁移)
实践:常用于数据库的分库分表规则,一般采用预分区的方式,提前根据数据量规划好分区数,比如划分为512或1024张表,保证可支撑未来一段时间的数据量,再根据负载情况将表迁移到其他数据库中。
#### 2、一致性哈希
一致性哈希分区(Distributed Hash Table)实现思路是为系统中每个节点分配一个 token,范围一般在0~232,这些 token 构成一个哈希环。数据读写执行节点查找操作时,先根据 key 计算 hash 值,然后顺时针找到第一个大于等于该哈希值的 token 节点
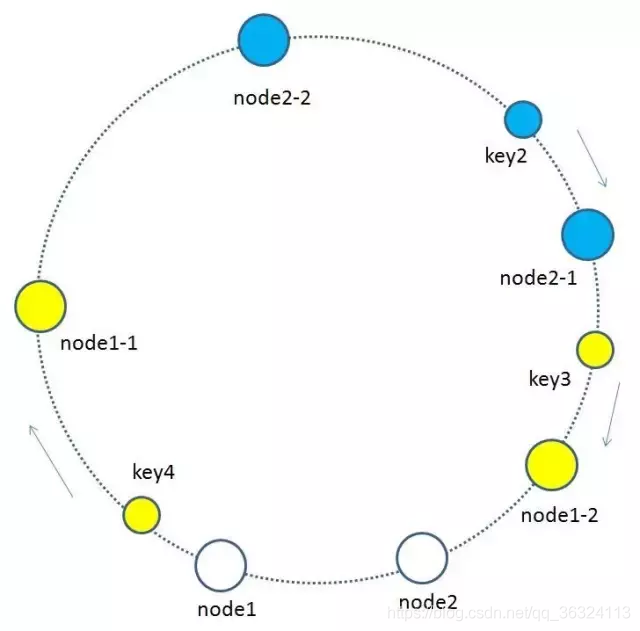
上图就是一个一致性哈希的原理解析
**图片来自**[什么是一致性哈希](https://www.jianshu.com/p/49e3fbf41b9b)。
假设我们有 n1~n4 这四台机器,我们对每一台机器分配一个唯一 token,每次有数据(图中黄色代表数据),一致性哈希算法规定每次都顺时针漂移数据,也就是图中黄色的数 据都指向 n3。
这个时候我们需要增加一个节点 n5,在 n2 和 n3 之间,数据还是会发生漂移(会偏移到大于等于的节点),但是这个时候你是否注意到,其实只有 n2~n3 这部分的数据被漂移,其他的数据都是不会变的,这种方式相比节点取余最大的好处在于加入和删除节点只影响哈希环中相邻的节点,对其他节点无影响
缺点:每个节点的负载不相同,因为每个节点的hash是根据key计算出来的,换句话说就是假设key足够多,被hash算法打散得非常均匀,但是节点过少,导致每个节点处理的key个数不太一样,甚至相差很大,这就会导致某些节点压力很大
实践:加减节点会造成哈希环中部分数据无法命中,需要手动处理或者忽略这部分数据,因此一致性哈希常用于缓存场景。
#### 3.虚拟槽分区
虚拟槽分区巧妙地使用了哈希空间,使用分散度良好的哈希函数把所有数据映射到一个固定范围的整数集合中,整数定义为槽(slot)。这个范围一般远远大于节点数,比如 Redis Cluster 槽范围是0~16383。槽是集群内数据管理和迁移的基本单位。采用大范围槽的主要目的是为了方便数据拆分和集群扩展。每个节点会负责一定数量的槽,下图所示。
当前集群有5个节点,每个节点平均大约负责3276个槽。由于采用高质量的哈希算法,每个槽所映射的数据通常比较均匀,将数据平均划分到5个节点进行数据分区。Redis Cluster 就是采用虚拟槽分区,下面就介绍 Redis 数据分区方法。
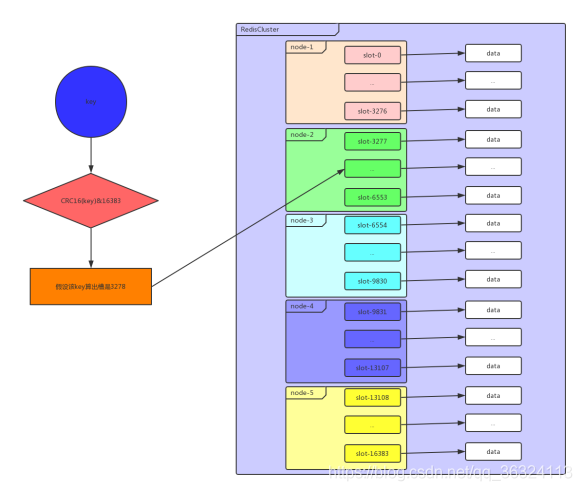
每当 key 访问过来,Redis Cluster 会计算哈希值是否在这个区间里。它们彼此都知道对应的槽在哪台机器上,这样就能做到平均分配了。
### redis-cluster的优势
#### 性能:
这是Redis赖以生存的看家本领,增加集群功能后当然不能对性能产生太大影响,所以Redis采取了P2P而非Proxy方式、异步复制、客户端重定向等设计,而牺牲了部分的一致性、使用性。
#### 水平扩展:
集群的最重要能力当然是扩展,文档中称可以线性扩展到1000结点。
#### 可用性:
在Cluster推出之前,可用性要靠Sentinel保证。有了集群之后也自动具有了Sentinel的监控和自动Failover能力。
### 搭建集群
#### 1、准备节点
Redis 集群一般由多个节点组成,节点数量至少为6个才能保证组成完整高可用的集群。每个节点需要开启配置 cluster-enabled yes,让 Redis 运行在集群模式下,上面的配置都相应的给到redis的配置文件当中并启动。
其他配置和单机模式一致即可,配置文件命名规则 redis-{port}.conf,准备好配置后启动所有节点,第一次启动时如果没有集群配置文件,它会自动创建一份,文件名称采用 cluster-config-file 参数项控制,建议采用 node-{port}.conf 格式定义,也就是说会有两份配置文件
当集群内节点信息发生变化,如添加节点、节点下线、故障转移等。节点会自动保存集群状态到配置文件中。需要注意的是,Redis 自动维护集群配置文件,不要手动修改,防止节点重启时产生集群信息错乱
每个节点需要开启配置 `cluster-enabled yes`,让 Redis 运行在集群模式下。集群相关配置如下:
#节点端口
port 6379
#开启集群模式
cluster-enabled yes
#节点超时时间,单位毫秒
cluster-node-timeout 15000
#集群内部配置文件
cluster-config-file "nodes-6379.conf"
配置文件信息如下:

文件内容记录了集群初始状态,这里最重要的是节点 ID,它是一个40位16进制字符串,用于唯一标识集群内一个节点,节点 ID 在集群初始化时只创建一次,节点重启时会加载集群配置文件进行重用,结合做相应的集群操作,而 Redis 的运行 ID 每次重启都会变化。
#### 2.节点握手
节点握手是指一批运行在集群模式下的节点通过 Gossip 协议彼此通信,达到感知对方的过程。节点握手是集群彼此通信的第一步,由客户端发起命令:`cluster meet{ip}{port}`
关于Gossip可以看看[文章的介绍](http://www.10tiao.com/html/681/201803/2651029463/1.html)
通过命令 `cluster meet 127.0.0.1 6380`让节点6379和6380节点进行握手通信。cluster meet 命令是一个异步命令,执行之后立刻返回。内部发起与目标节点进行握手通信
1)节点6379本地创建6380节点信息对象,并发送 meet 消息。
2)节点6380接受到 meet 消息后,保存6379节点信息并回复 pong 消息。
3)之后节点6379和6380彼此定期通过 `ping/pong` 消息进行正常的节点通信。
通过cluster nodes 命令确认6个节点都彼此感知并组成集群

注意:
1、每个Redis Cluster节点会占用两个TCP端口,一个监听客户端的请求,默认是6379,另外一个在前一个端口加上10000,比如16379,来监听数据的请求,节点和节点之间会监听第二个端口,用一套二进制协议来通信。
节点之间会通过套协议来进行失败检测,配置更新,failover认证等等。
为了保证节点之间正常的访问,需要注意防火墙的配置。
2、节点建立握手之后集群还不能正常工作,这时集群处于下线状态,所有的数据读写都被禁止
### 3.设置从节点
作为一个完整的集群,需要主从节点,保证当它出现故障时可以自动进行故障转移。集群模式下,Reids 节点角色分为主节点和从节点。
首次启动的节点和被分配槽的节点都是主节点,从节点负责复制主节点槽信息和相关的数据。
使用 `cluster replicate {nodeId}`命令让一个节点成为从节点。其中命令执行必须在对应的从节点上执行,将当前节点设置为 node_id 指定的节点的从节点
redis-cli -h 47.98.147.49 -p 6395 CLUSTER REPLICATE 0affa79edef47e10a0459832d279fe74467be98b
redis-cli -h 47.98.147.49 -p 6396 CLUSTER REPLICATE 1e30c186681638411f25f949f1b6ffded5f5d0a3
### 4.分配槽
Redis 集群把所有的数据映射到16384个槽中。每个 key 会映射为一个固定的槽,只有当节点分配了槽,才能响应和这些槽关联的键命令。通过 `cluster addslots` 命令为节点分配槽
利用 bash 特性批量设置槽(slots),命令如下
redis-cli -h 47.98.147.49 -p 6391 cluster addslots {0..5461}
redis-cli -h 47.98.147.49 -p 6392 cluster addslots {5462..10922}
redis-cli -h 47.98.147.49 -p 6393 cluster addslots {10923..16383}
我们依照 Redis 协议手动建立一个集群。它由6个节点构成,3个主节点负责处理槽和相关数据,3个从节点负责故障转移。手动搭建集群便于理解集群建立的流程和细节,但是我们从中发现集群搭建需要很多步骤,当集群节点众多时,必然会加大搭建集群的复杂度和运维成本。**因此 Redis 官方提供了 redis-trib.rb 工具方便我们快速搭建集群。**
4.操作集群
-c 集群模式

如果没有指定集群模式,那么会出现如下错误

所有命令:
`CLUSTER info`:打印集群的信息。
`CLUSTER nodes`:列出集群当前已知的所有节点(node)的相关信息。
`CLUSTER meet <ip> <port>`:将ip和port所指定的节点添加到集群当中。
`CLUSTER addslots <slot> [slot ...]`:将一个或多个槽(slot)指派(assign)给当前节点。
`CLUSTER delslots <slot> [slot ...]`:移除一个或多个槽对当前节点的指派。
`CLUSTER slots`:列出槽位、节点信息。
`CLUSTER slaves <node_id>`:列出指定节点下面的从节点信息。
`CLUSTER replicate <node_id>`:将当前节点设置为指定节点的从节点。
`CLUSTER saveconfig`:手动执行命令保存保存集群的配置文件,集群默认在配置修改的时候会自动保存配置文件。
`CLUSTER keyslot <key>`:列出key被放置在哪个槽上。
`CLUSTER flushslots`:移除指派给当前节点的所有槽,让当前节点变成一个没有指派任何槽的节点。
`CLUSTER countkeysinslot <slot>`:返回槽目前包含的键值对数量。
`CLUSTER getkeysinslot <slot> <count>`:返回count个槽中的键。
`CLUSTER setslot <slot> node <node_id>` :将槽指派给指定的节点,如果槽已经指派给另一个节点,那么先让另一个节点删除该槽,然后再进行指派。
`CLUSTER setslot <slot> migrating <node_id>` :将本节点的槽迁移到指定的节点中。
`CLUSTER setslot <slot> importing <node_id>` :从 node_id 指定的节点中导入槽 slot 到本节点。
`CLUSTER setslot <slot> stable` :取消对槽 slot 的导入(import)或者迁移(migrate)。
`CLUSTER failover`:手动进行故障转移。
`CLUSTER forget <node_id>`:从集群中移除指定的节点,这样就无法完成握手,过期时为60s,60s后两节点又会继续完成握手。
`CLUSTER reset [HARD|SOFT]`:重置集群信息,soft是清空其他节点的信息,但不修改自己的id,hard还会修改自己的id,不传该参数则使用soft方式。
`CLUSTER count-failure-reports <node_id>`:列出某个节点的故障报告的长度。
`CLUSTER SET-CONFIG-EPOCH`:设置节点epoch,只有在节点加入集群前才能设置。
- 微服务
- 服务器相关
- 操作系统
- 极客时间操作系统实战笔记
- 01 程序的运行过程:从代码到机器运行
- 02 几行汇编几行C:实现一个最简单的内核
- 03 黑盒之中有什么:内核结构与设计
- Rust
- 入门:Rust开发一个简单的web服务器
- Rust的引用和租借
- 函数与函数指针
- Rust中如何面向对象编程
- 构建单线程web服务器
- 在服务器中增加线程池提高吞吐
- Java
- 并发编程
- 并发基础
- 1.创建并启动线程
- 2.java线程生命周期以及start源码剖析
- 3.采用多线程模拟银行排队叫号
- 4.Runnable接口存在的必要性
- 5.策略模式在Thread和Runnable中的应用分析
- 6.Daemon线程的创建以及使用场景分析
- 7.线程ID,优先级
- 8.Thread的join方法
- 9.Thread中断Interrupt方法学习&采用优雅的方式结束线程生命周期
- 10.编写ThreadService实现暴力结束线程
- 11.线程同步问题以及synchronized的引入
- 12.同步代码块以及同步方法之间的区别和关系
- 13.通过实验分析This锁和Class锁的存在
- 14.多线程死锁分析以及案例介绍
- 15.线程间通信快速入门,使用wait和notify进行线程间的数据通信
- 16.多Product多Consumer之间的通讯导致出现程序假死的原因分析
- 17.使用notifyAll完善多线程下的生产者消费者模型
- 18.wait和sleep的本质区别
- 19.完善数据采集程序
- 20.如何实现一个自己的显式锁Lock
- 21.addShutdownHook给你的程序注入钩子
- 22.如何捕获线程运行期间的异常
- 23.ThreadGroup API介绍
- 24.线程池原理与自定义线程池一
- 25.给线程池增加拒绝策略以及停止方法
- 26.给线程池增加自动扩充,闲时自动回收线程的功能
- JVM
- C&C++
- GDB调试工具笔记
- C&C++基础
- 一个例子理解C语言数据类型的本质
- 字节顺序-大小端模式
- Php
- Php源码阅读笔记
- Swoole相关
- Swoole基础
- php的五种运行模式
- FPM模式的生命周期
- OSI网络七层图片速查
- IP/TCP/UPD/HTTP
- swoole源代码编译安装
- 安全相关
- MySql
- Mysql基础
- 1.事务与锁
- 2.事务隔离级别与IO的关系
- 3.mysql锁机制与结构
- 4.mysql结构与sql执行
- 5.mysql物理文件
- 6.mysql性能问题
- Docker&K8s
- Docker安装java8
- Redis
- 分布式部署相关
- Redis的主从复制
- Redis的哨兵
- redis-Cluster分区方案&应用场景
- redis-Cluster哈希虚拟槽&简单搭建
- redis-Cluster redis-trib.rb 搭建&原理
- redis-Cluster集群的伸缩调优
- 源码阅读笔记
- Mq
- ELK
- ElasticSearch
- Logstash
- Kibana
- 一些好玩的东西
- 一次折腾了几天的大华摄像头调试经历
- 搬砖实用代码
- python读取excel拼接sql
- mysql大批量插入数据四种方法
- composer好用的镜像源
- ab
- 环境搭建与配置
- face_recognition本地调试笔记
- 虚拟机配置静态ip
- Centos7 Init Shell
- 发布自己的Composer包
- git推送一直失败怎么办
- Beyond Compare过期解决办法
- 我的Navicat for Mysql
- 小错误解决办法
- CLoin报错CreateProcess error=216
- mysql error You must reset your password using ALTER USER statement before executing this statement.
- VM无法连接到虚拟机
- Jetbrains相关
- IntelliJ IDEA 笔记
- CLoin的配置与使用
- PhpStormDocker环境下配置Xdebug
- PhpStorm advanced metadata
- PhpStorm PHP_CodeSniffer