
[TOC]
## 为什么docker会采取这种分层结构?
资源共享。采用分层机制实现基础层共享,从而减小docker仓库整体体积
基础:https://blog.csdn.net/m0_46090675/article/details/121597421
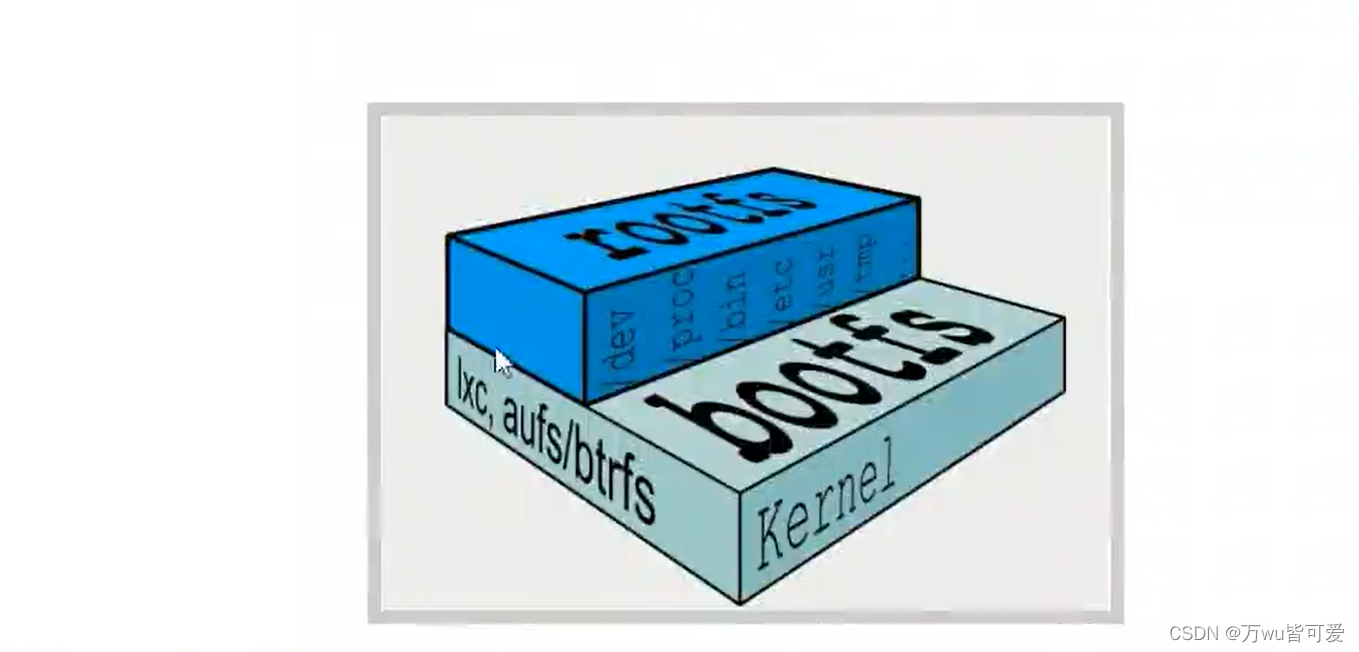
docker镜像的实质是由一层层文件系统组成
boots (boot file system)主要包含bootloader和kernel, bootloader主要是引导加载kernel, Linux刚启动时会加载boots文件系统。在docke镜像的最底层就是bootfs。这一层与Linux(Univx系统是一样的,包含boot加载器(bootoader)和内核(kermnel)。当boot加载完,后整个内核就都在内存中了,此时内存的使用权已由bootfs转交给内核,此时会卸载bootfs。
rootfs (root file system),在bootfs之上,包含的就是典型的linux系统中的/dev/proc,/bin,/etc等标准的目录和文件。rootfs就是各种不同的操作系统发行版,比如Ubuntu/Centos等等。
我们平时安装进虚拟机的centos都有1到几个GB,为什么docer这里才20OMB?对于一个精简的OS,roots可以很小,只需要包括最基本的命令,工具,和程序库就可以了,因为底层直接使用Host的Kernal,自己只需要提供rootfs就行了。由此可见不同的linux发行版,他们的bootfs是一致的,rootfs会有差别。因此不同的发行版可以共用bootfs。
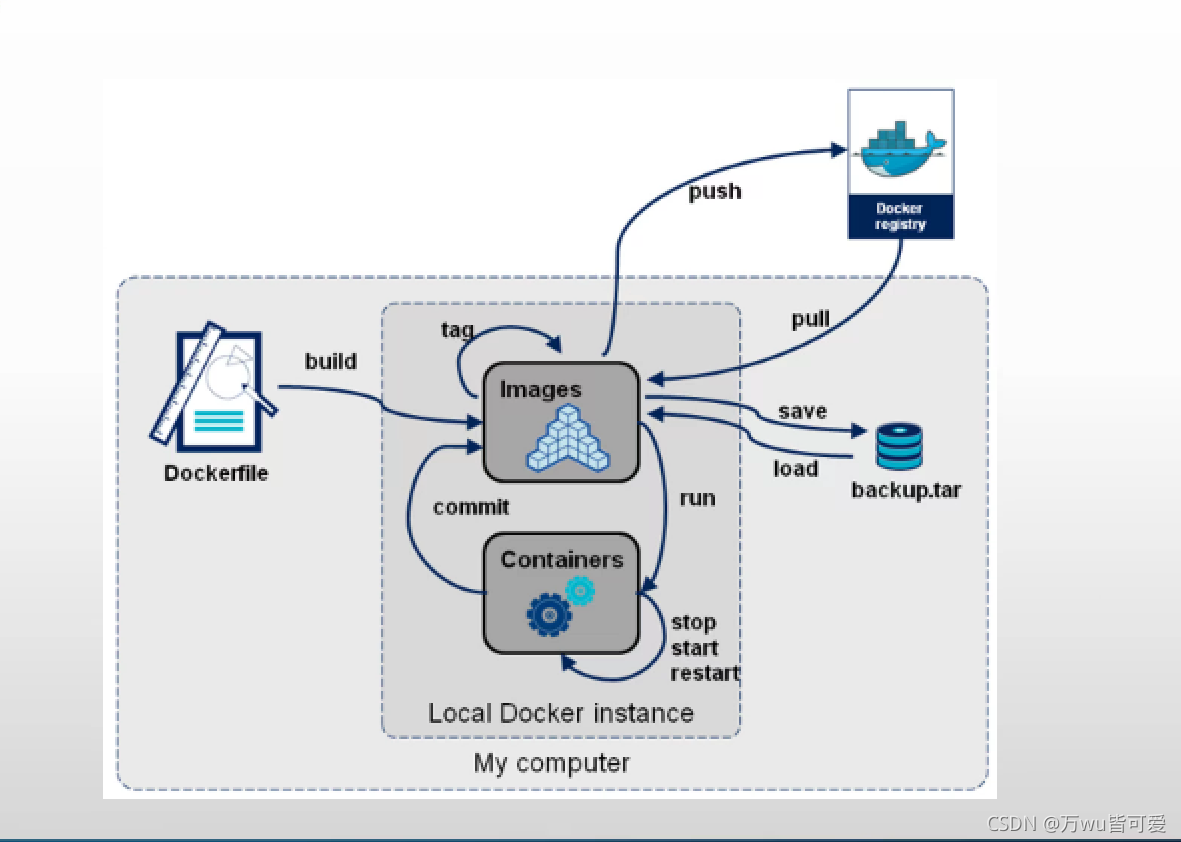
## 生命周期
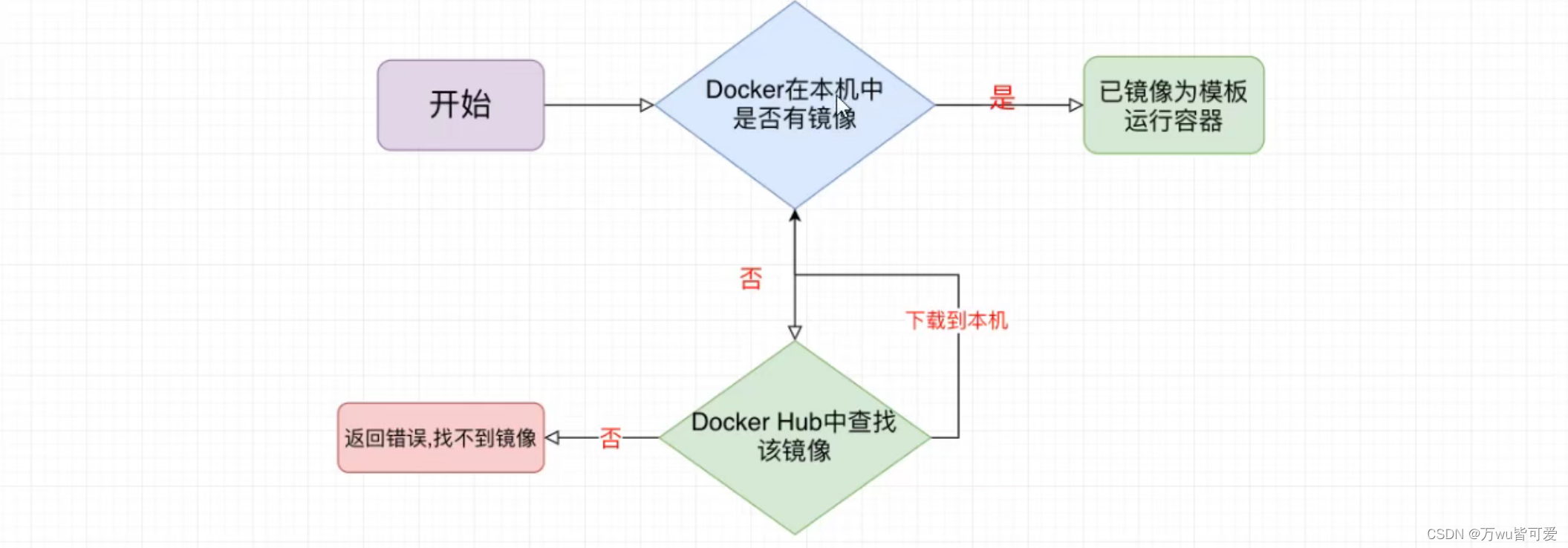
## docker镜像启动流程
## 基本命令
docker info 查看的是docker 服务的信息
### 镜像
|命令 | 解释 | eg|
| --- | --- |---|
| docker images | 列出属于镜像 | |
|docker images xxx | 镜像名字,根据名称列出镜像 ||
| docker images -q| 只列出镜像的id ||
| docker search xxx |查找镜像 ||
|docker rmi xxx | 删除镜像||
|docker image inspect xxx | 查看镜像信息||
|docker pull xxx | 下载镜像||
|docker push xxx | 推送镜像||
|docker image save xxx > /path/xxx.tgz| 导出某镜像| docker images save nginx|
|docker image load -i /path/xxx.tgz | 导出某镜像| docker images load -i /docker-test/nginx.tgz|
|docker cp 容器id:容器内路径 目的主机路径 | 拷贝容器的文件到主机中| |
|docker cp 目的主机路径 容器id:容器内路径 | 拷贝宿主机的文件到容器中| |
### 容器
|命令 | 解释 | eg|
| --- | --- |---|
|docker run xxx|创建+启动,本地存在就直接启动,没有就先下载再启动 | |
|docker exec -it 容器id或者容器名 bash(命令行) | 交互式进入运行的容器||
|docker ps | 查看运行的容器||
|docker ps -a | 查看所有容器||
|docker stop xxx | 停止容器||
|docker container kill xxx |停止容器 ||
|docker rm xxx | 删除容器 ||
|docker rm -f `docker ps -aq |删除所有容器 ||
|docker run -d -p port(宿主机port):port(容器port) xxx| 运行容器,并映射端口||
|docker logs xxx| 查看日志||
|docker container inspect xxx | 查看镜像信息||
|docker port 容器id | 查看容器端口||
|docker commit xxx | 提交容器||
|docker export xxx > xxx.tar|导出容器| docker export nginx >nginx.tar|
|docker import xxx nnn | 导入 容器|docker import cnetos-8-vim.tgz cent-vin(镜像的名字) |
>随机端口 -P
>docker commit 容器的id docker账号/镜像名字
>docker run xxx 只会启动容器,并停止,只能通过docker ps -a查看,因为没有前台运行命令
eg:docker run nginx , 是错误的,只能 docker run -it -d nginx bash
>docker run -d -rm xxx 停止就删除
-- name xxx(名字)
### 其他命令
| 命令 | 解释 |
| --- | --- |
|docker logs -f 容器id | 跟踪容器日志 |
|docker logs -ft 容器id | 跟踪容器日志和时间戳 |
|docker top 容器id | 查看容器进程 |
|docker stats | 查看容器列表系统资源状态 |
## 数据卷
卷就是目录或文件,存在于一个或多个容器中,由Docker挂载到容器,但卷不属于联合文件系统(Union FileSystem),因此能够绕过联合文件系统提供一些用于持续存储或共享数据的特性。
数据卷的特性:
* 数据卷可以在容器之间或容器与宿主机之间共享和重用
* 对数据卷的修改会立马生效
* 对数据卷的更新,不会影响镜像
* 数据卷会一直存在,即使容器被删除
>自定义数据卷目录
~~~
docker run -it -v 主机目录(绝对路径):容器目录
例如
docker run --name tomcat02 -d -p 8082:8080 -v /soft/wabapps:/usr/local/tomcat/webapps tomcat:latest
~~~
>自动数据卷目录
~~~
docker run --name tomcat03 -d -p 8082:8080 -v aaa:/usr/local/tomcat/webapps tomcat:latest
注意:
1.aa代表一个数据卷名字,名称可以随便写, docker在不存在时自动创建这个数据卷同时自动映射宿主机中某个目录
2.同时在启动容器时会将aa对应容器目录中全部内容复制到aa映射目录中
~~~
> 列出所有数据卷
docker volume ls
> 查看具体的数据卷信息
docker volume inspect 卷名
>创建数据卷
docker volume create bb
启动容器时候,可以直接 -v bb:/var/lib/tomcat/webapps
>删除
docker volume rm bb
## Docker 网络
https://blog.csdn.net/lihongbao80/article/details/108019773
> 查看默认网络:docker network ls
### 自定义网桥
~~~
docker network create -d bridge --subnet 192.168.1.2/24 my_network
然后运行:docker run -d -p 80:8080 --name tomcat01 --network my_network
其中 --subnet 可以不指定
~~~
>查看网桥信息及网桥下活跃的容器 docker network inspect bridge
>删除网桥:docker network rm 网桥名称
删除未使用的网络:docker network prune #ps: -f 强制删除,不提供任何确认情况下删除.
将一个容器加入到一个网络中:docker network connect 网络名称 容器ID
从网络中断开一个容器的链接:docker network disconnect 网络名称 容器 ID # ps: -f 强制删除,不提供任何确认情况下删除.
注意:
一旦在启动容器时指定了自建网桥之后,日后可以在任何这个网桥关联的容器中使用容器名字进行与其他容器通信(将容器名字解析到容器DNS中)
### 创建网络
~~~
docker network create (appnet)名称 --subnet 10.224.0.0/16(网段)
~~~
启动容器,加入自己的网络
eg:
```
docker run --name alpine2 --rm --net appnet alpine:3.15 ifconfig
```
## docker网络模式
### bridge模式,--net=bridge(默认)
这是dokcer网络的默认设置,为容器创建独立的网络命名空间,容器具有独立的网卡等所有单独的网络栈,是最常用的使用方式。在docker run启动容器的时候,如果不加–net参数,就默认采用这种网络模式。安装完docker,系统会自动添加一个供docker使用的网桥docker0,我们创建一个新的容器时,容器通过DHCP获取一个与docker0同网段的IP地址,并默认连接到docker0网桥,以此实现容器与宿主机的网络互通。
### host模式,--net=host
Docker使用了Linux的Namespaces技术来进行资源隔离,如PID Namespace隔离进程,Mount Namespace隔离文件系统,Network Namespace隔离网络等。一个Network Namespace提供了一份独立的网络环境,包括网卡、路由、Iptable规则等都与其他的Network Namespace隔离。一个Docker容器一般会分配一个独立的Network Namespace。但如果启动容器的时候使用host模式,那么这个容器将不会获得一个独立的Network Namespace,而是和宿主机共用一个Network Namespace。容器将不会虚拟出自己的网卡,配置自己的IP等,而是使用宿主机的IP和端口。。
### none模式,--net=none
为容器创建独立网络命名空间,但不为它做任何网络配置,容器中只有lo,用户可以在此基础上,对容器网络做任意定制。这个模式下,dokcer不为容器进行任何网络配置。需要我们自己为容器添加网卡,配置IP。因此,若想使用pipework配置docker容器的ip地址,必须要在none模式下才可以。
### 其他容器模式(即container模式,join模式),--net=container:NAME_or_ID
与host模式类似,只是容器将与指定的容器共享网络命名空间。这个模式就是指定一个已有的容器,共享该容器的IP和端口。除了网络方面两个容器共享,其他的如文件系统,进程等还是隔离开的。
### 用户自定义
docker 1.9版本以后新增的特性,允许容器使用第三方的网络实现或者创建单独的bridge网络,提供网络隔离能力。
> 这些网络模式在相互网络通信方面的对比如下所示
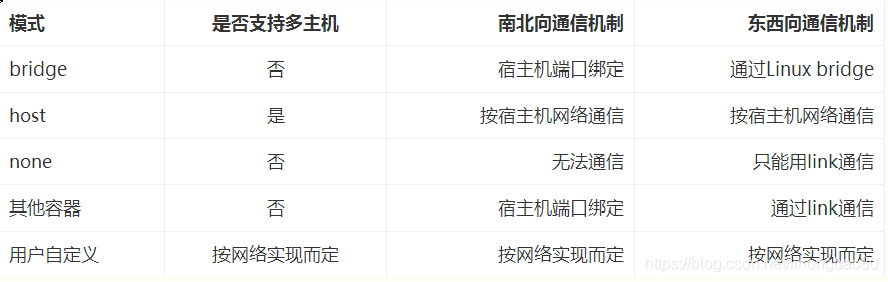
南北向通信指容器与宿主机外界的访问机制,东西向流量指同一宿主机上,与其他容器相互访问的机制。
**`1)host模式`**
由于容器和宿主机共享同一个网络命名空间,换言之,容器的IP地址即为宿主机的IP地址。所以容器可以和宿主机一样,使用宿主机的任意网卡,实现和外界的通信。网络模型可以参照下图
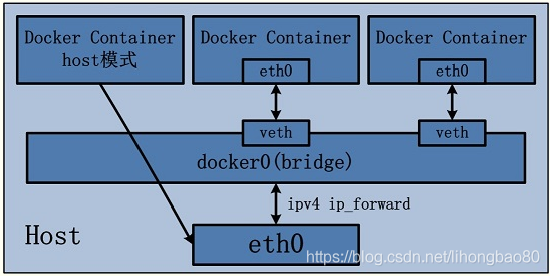
采用host模式的容器,可以直接使用宿主机的IP地址与外界进行通信,若宿主机具有公有IP,那么容器也拥有这个公有IP。同时容器内服务的端口也可以使用宿主机的端口,无需额外进行NAT转换,而且由于容器通信时,不再需要通过linuxbridge等方式转发或数据包的拆封,性能上有很大优势。当然,这种模式有优势,也就有劣势,主要包括以下几个方面:
1)最明显的就是容器不再拥有隔离、独立的网络栈。容器会与宿主机竞争网络栈的使用,并且容器的崩溃就可能导致宿主机崩溃,在生产环境中,这种问题可能是不被允许的。
2)容器内部将不再拥有所有的端口资源,因为一些端口已经被宿主机服务、bridge模式的容器端口绑定等其他服务占用掉了。
**`2)bridge模式`**
bridge模式是docker默认的。在这种模式下,docker为容器创建独立的网络栈,保证容器内的进程使用独立的网络环境,实现容器之间、容器与宿主机之间的网络栈隔离。同时,通过宿主机上的docker0网桥,容器可以与宿主机乃至外界进行网络通信。其网络模型可以参考下图:
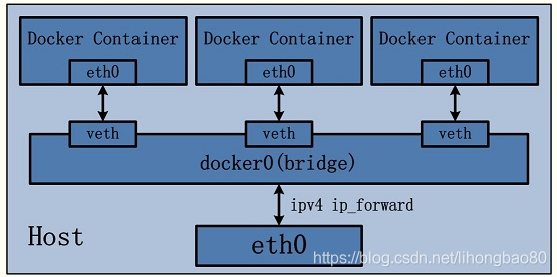
从上面的网络模型可以看出,容器从原理上是可以与宿主机乃至外界的其他机器通信的。同一宿主机上,容器之间都是连接掉docker0这个网桥上的,它可以作为虚拟交换机使容器可以相互通信。然而,由于宿主机的IP地址与容器veth pair的 IP地址均不在同一个网段,故仅仅依靠veth pair和namespace的技术,还不足以使宿主机以外的网络主动发现容器的存在。为了使外界可以方位容器中的进程,docker采用了端口绑定的方式,也就是通过iptables的NAT,将宿主机上的端口端口流量转发到容器内的端口上。举一个简单的例子,使用下面的命令创建容器,并将宿主机的3306端口绑定到容器的3306端口:
```
docker run -tid --name db -p 3306:3306 MySQL
```
在宿主机上,可以通过iptables -t nat -L -n,查到一条DNAT规则:
```
# DNAT tcp -- 0.0.0.0/0 0.0.0.0/0 tcp dpt:3306 to:172.17.0.5:3306
```
上面的172.17.0.5即为bridge模式下,创建的容器IP。
很明显,bridge模式的容器与外界通信时,必定会占用宿主机上的端口,从而与宿主机竞争端口资源,对宿主机端口的管理会是一个比较大的问题。同时,由于容器与外界通信是基于三层上iptables NAT,性能和效率上的损耗是可以预见的。
**`3)none模式`**
在这种模式下,容器有独立的网络栈,但不包含任何网络配置,只具有lo这个loopback网卡用于进程通信。也就是说,none模式为容器做了最少的网络设置,但是俗话说得好“少即是多”,在没有网络配置的情况下,通过第三方工具或者手工的方式,开发这任意定制容器的网络,提供了最高的灵活性
**`4)其他容器(container)模式`**
其他网络模式是docker中一种较为特别的网络的模式。在这个模式下的容器,会使用其他容器的网络命名空间,其网络隔离性会处于bridge桥接模式与host模式之间。当容器共享其他容器的网络命名空间,则在这两个容器之间不存在网络隔离,而她们又与宿主机以及除此之外其他的容器存在网络隔离。其网络模型可以参考下图:
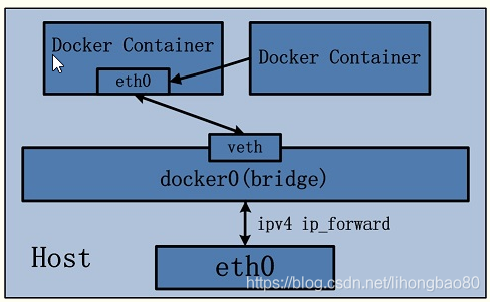
在这种模式下的容器可以通过localhost来同一网络命名空间下的其他容器,传输效率较高。而且这种模式还节约了一定数量的网络资源,但它并没有改变容器与外界通信的方式。在一些特殊的场景中非常有用,例如,kubernetes的pod,kubernetes为pod创建一个基础设施容器,同一pod下的其他容器都以其他容器模式共享这个基础设施容器的网络命名空间,相互之间以localhost访问,构成一个统一的整体。
**`5)用户定义网络模式`**
在用户定义网络模式下,开发者可以使用任何docker支持的第三方网络driver来定制容器的网络。并且,docker 1.9以上的版本默认自带了bridge和overlay两种类型的自定义网络driver。可以用于集成calico、weave、openvswitch等第三方厂商的网络实现。 除了docker自带的bridge driver,其他的几种driver都可以实现容器的跨主机通信。而基于bdrige driver的网络,docker会自动为其创建iptables规则,保证与其他网络之间、与docker0之间的网络隔离。 例如,使用下面的命令创建一个基于bridge driver的自定义网络:
```
docker network create bri1
```
则docker会自动生成如下的iptables规则,保证不同网络上的容器无法互相通信。
```
A DOCKER-ISOLATION -i br-8dba6df70456 -o docker0 -j DROP
A DOCKER-ISOLATION -i docker0 -o br-8dba6df70456 -j DROP
```
除此之外,bridge driver的所有行为都和默认的bridge模式完全一致。而overlay及其他driver,则可以实现容器的跨主机通信。
- Go准备工作
- 依赖管理
- Go基础
- 1、变量和常量
- 2、基本数据类型
- 3、运算符
- 4、流程控制
- 5、数组
- 数组声明和初始化
- 遍历
- 数组是值类型
- 6、切片
- 定义
- slice其他内容
- 7、map
- 8、函数
- 函数基础
- 函数进阶
- 9、指针
- 10、结构体
- 类型别名和自定义类型
- 结构体
- 11、接口
- 12、反射
- 13、并发
- 14、网络编程
- 15、单元测试
- Go常用库/包
- Context
- time
- strings/strconv
- file
- http
- Go常用第三方包
- Go优化
- Go问题排查
- Go框架
- 基础知识点的思考
- 面试题
- 八股文
- 操作系统
- 整理一份资料
- interface
- array
- slice
- map
- MUTEX
- RWMUTEX
- Channel
- waitGroup
- context
- reflect
- gc
- GMP和CSP
- Select
- Docker
- 基本命令
- dockerfile
- docker-compose
- rpc和grpc
- consul和etcd
- ETCD
- consul
- gin
- 一些小点
- 树
- K8s
- ES
- pprof
- mycat
- nginx
- 整理后的面试题
- 基础
- Map
- Chan
- GC
- GMP
- 并发
- 内存
- 算法
- docker