
丰富的过滤器插件是 logstash威力如此强大的重要因素,过滤器插件主要处理流经当前Logstash的事件信息,可以添加字段、移除字段、转换字段类型,通过正则表达式切分数据等,也可以根据条件判断来进行不同的数据处理方式。
[TOC]
## A grok正则捕获插件
[Logstash简单介绍](https://blog.csdn.net/chenleiking/article/details/73563930)
[grokdebug在线调试grok](http://grokdebug.herokuapp.com/)
[grok预装正则表达式](https://www.cnblogs.com/stozen/p/5638369.html)
[github上的预装正则表达式](https://github.com/logstash-plugins/logstash-patterns-core/tree/master/patterns)
grok插件是一个十分耗费资源的插件,是Logstash中将非结构化数据解析成结构化数据以便于查询的最好工具,非常适合解析syslog logs,apache log, mysql log,以及一些其他的web log
### **预定义表达式调用**
Logstash提供120个常用正则表达式可供安装使用,安装之后你可以通过名称调用它们,语法如下:
```sh
%{SYNTAX:SEMANTIC}
SYNTAX:表示已经安装的正则表达式的名称
SEMANTIC:表示给Event中匹配到的内容指定什么名称
```
>例如:Event的内容为`“[debug] 127.0.0.1 - test log content”`,匹配`%{IP:client}`将获得`“client: 127.0.0.1”`的结果;
如果想对捕获的数据进行数据类型转换,可以使用`%{NUMBER:num:int}`这种语法
默认返回结果都是string类型,且当前Logstash所支持的转换类型仅有“int”和“float”;
### **grok匹配事例:**
```sh
#日志内容:55.3.244.1 GET /index.html 15824 0.043
filter {
grok {
match => {"message" => "%{IP:client} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER:duration}"}
}
}
```
**输出结果:**
~~~sh
client: 55.3.244.1
method: GET
request: /index.html
bytes: 15824
duration: 0.043
~~~
### 自定义表达式
* 自定义表达式语法
语法:`(?<field_name>the_pattern)`
举例:捕获10或11和长度的十六进制`queue_id`
可以使用表达式`(?<queue_id>[0-9A-F]{10,11})`
* 安装自定义表达式
可以将自定义的表达式配置到Logstash中,就可以像于定义的表达式一样使用;
1. 在Logstash根目录下创建文件夹`patterns`
2. 在`patterns`文件夹中创建文件`extra`(文件名自定义)
3. 在文件“extra”中添加表达式,格式:`patternName regexp`
4. 如:`POSTFIX_QUEUEID [0-9A-F]{10,11}`
5. 使用自定义的表达式时需要指定“patterns_dir”变量举例如下:
```
filter {
grok {
patterns_dir => "/path/to/your/own/patterns"
match => { "message" => ........" }
}
}
```
## B date时间处理插件
这里需要合前面的grok插件剥离出来的值logdate配合使用。可以格式化为需要的样子。
**为什什么要格式化?**
日志产生的时间肯定早于日志在logstash中处理的时间,如果不修改,保存进ES的时间(@timestamp)就是logstash当前处理数据的时间,时间就会不一致
格式化以后,可以通过target属性来指定到@timestamp,这样数据的时间就会是准确的,对以后图表的建设来说万分重要。
最后,顺手删除logdate这个字段已无用的字段。
~~~
filter{
date{
match=>["logdate","dd/MMM/yyyy:HH:mm:ss Z"]
target=>"@timestamp"
remove_field => 'logdate'
}
}
~~~
>需要强调的是,@timestamp字段的值,不可以随便修改,最好就按照数据的某一个时间点来使用
如果是日志,就使用grok把时间抠出来,如果是数据库,就指定一个字段的值来格式化
如果没有这个字段的话,千万不要试着去修改它。
## C mutate插件
mutate 插件是 Logstash另一个重要插件。提供了丰富的基础类型数据处理能力。可以重命名,删除,替换和修改事件中的字段。
~~~
filter {
mutate {
#接收一个数组,其形式为value,type
convert => [
#把request_time的值转换为浮点型,把costTime的值转换为整型
"request_time", "float",
"costTime", "integer"
]
}
}
~~~
* convert 字段转换
将指定字段转换为指定类型,字段内容是数组,则转换所有数组元素,如果字段内容是hash,则不做任何处理
目前支持的转换类型包括:integer,float, string, and boolean.
例如: convert=> { “fieldname” => “integer” }
* rename 字段重命名
修改一个或者多个字段的名称。
例如: ` rename=> { “HOSTORIP” => “client_ip” }`
* replace 值替换
使用新值完整的替换掉指定字段的原内容,支持变量引用。
例如: 使用字段“source_host”的内容拼接上字符串“: My new message”之后的结果替换“message”的值:
`replace=> { “message” => “%{source_host}: My new message” }`
* gsub 字符串替换
类似replace方法,但是只针对字符串类型有效
例如:`[ “fieldname”, “/”, “:“, “fieldname2”, “[\\?#-]”, “.”]`,
解释:使用`:`替换掉`fieldname`中的所有`/`,使用“.”替换掉“fieldname2”中的所有`\ ? # 和-`
* update 更新字段
更新现有字段的内容,
例如: 将“sample”字段的内容更新为“Mynew message”:
`update=> { “sample” => “My new message” }`
* join 连接数组字段
使用指定的符号将array字段的每个元素连接起来,对非array字段无效。
例如: 使用`,`将array字段`fieldname`的每一个元素连接成一个字符串:
`join=> { “fieldname” => “,” }
`
* merge 合并数组
合并两个array或者hash,将一个array和一个hash合并。
例如: 将”added_field”合并到”dest_field”:
`merge=> { “dest_field” => “added_field” }`
* split 字段分割
按照自定的分隔符将字符串字段拆分成array字段,只能作用于string类型的字段。
例如: 将“fieldname”的内容按照`,`拆分成数组:
`split=> { “fieldname” => “,” }
`
* strip 去掉空格
去掉字段内容两头的空白字符。例如: `strip=> [“field1”, “field2”]`
* uppercase 大写转换
将指定的字段值转换为大写
* lowercase 小写转换
将指定的字段值转换为小写
## D ruby插件
ruby插件可以使用任何的ruby语法,无论是逻辑判断,条件语句,循环语句,对字符串的操作,或是对EVENT对象的操作
**ruby插件有两个属性,一个init 还有一个code**
init属性是用来初始化字段的,这个字段只是在ruby{}作用域里面生效。
code属性使用两个冒号进行标识,所有ruby语法都可以在里面进行。
~~~
filter {
ruby {
init => [field={}]
code => "
array=event.get('message').split('|')
array.each do |value|
if value.include? 'MD5_VALUE'
then
require 'digest/md5'
md5=Digest::MD5.hexdigest(value)
event.set('md5',md5)
end
if value.include? 'DEFAULT_VALUE'
then
event.set('value',value)
end
end
remove_field=>"message"
"
}
}
#首先,把message字段里面的值拿到,并按照“|”分割为数组
#第二步,循环数组判断其值是否是我需要的数据(ruby条件语法、循环结构)
#第三步,把需要的字段添加进入EVEVT对象。
##event就是Logstash对象,可以在ruby插件的code属性里面操作,可以添加属性字段,删除,修改,数值运算。
#第四步,选取一个值,进行MD5加密或其他操作,最后把冗余的message字段去除。
~~~
## E json插件
JSON插件用于解码JSON格式的字符串,一般是一堆日志信息中,部分是JSON格式,部分不是的情况下,会将json格式部分的数据解析出来放到单独的字段中
和input中的codec插件的json区别在于,input中的插件,解析json格式后,会替代message中的数据,而filter中的json插件,解析出的字段是单独的,不会覆盖message的数据
~~~
filter{
#source指定你的哪个值是json数据。
json {
source => "value"
}
}
~~~
>如果你的json数据是多层的,那么解析出来的数据在多层结里是一个数组,你可以使用ruby语法对他进行操作,最终把所有数据都转换为平级的。
json插件还是需要注意一下使用的方法的,下图就是多层结构的弊端:
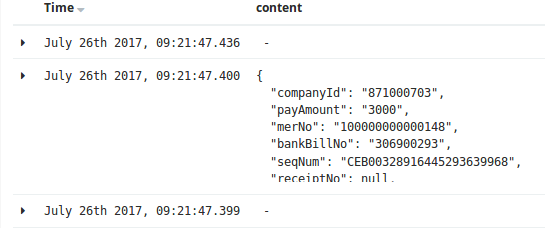
对应的解决方案为:
~~~ruby
ruby{
code=>"
kv=event.get('content')[0]
kv.each do |k,v|
event.set(k,v)
end"
remove_field => ['content','value','receiptNo','channelId','status']
}
~~~
- shell编程
- 变量1-规范-环境变量-普通变量
- 变量2-位置-状态-特殊变量
- 变量3-变量子串
- 变量4-变量赋值三种方法
- 变量5-数组相关
- 计算1-数值计算命令和案例
- 计算2-expr命令举例
- 计算3-条件表达式和各种操作符
- 计算4-条件表达式和操作符案例
- 循环1-函数的概念与作用
- 循环2-if与case语法
- 循环3-while语法
- 循环4-for循环
- 其他1-判断传入的参数为0或整数的多种思路
- 其他2-while+read按行读取文件
- 其他3-给输出内容加颜色
- 其他4-shell脚本后台运行知识
- 其他5-6种产生随机数的方法
- 其他6-break,continue,exit,return区别
- if语法案例
- case语法案例
- 函数语法案例
- WEB服务软件
- nginx相关
- 01-简介与对比
- 02-日志说明
- 03-配置文件和虚拟主机
- 04-location模块和访问控制
- 05-status状态模块
- 06-rewrite重写模块
- 07-负载均衡和反向代理
- 08-反向代理监控虚拟IP地址
- nginx与https自签发证书
- php-nginx-mysql联动
- Nginx编译安装[1.12.2]
- 案例
- 不同客户端显示不同信息
- 上传和访问资源池分离
- 配置文件
- nginx转发解决跨域问题
- 反向代理典型配置
- php相关
- C6编译安装php.5.5.32
- C7编译php5
- C6/7yum安装PHP指定版本
- tomcxat相关
- 01-jkd与tomcat部署
- 02-目录-日志-配置文件介绍
- 03-tomcat配置文件详解
- 04-tomcat多实例和集群
- 05-tomcat监控和调优
- 06-Tomcat安全管理规范
- show-busy-java-threads脚本
- LVS与keepalived
- keepalived
- keepalived介绍和部署
- keepalived脑裂控制
- keepalived与nginx联动-监控
- keepalived与nginx联动-双主
- LVS负载均衡
- 01-LVS相关概念
- 02-LVS部署实践-ipvsadm
- 03-LVS+keepalived部署实践
- 04-LVS的一些问题和思路
- mysql数据库
- 配置和脚本
- 5.6基础my.cnf
- 5.7基础my.cnf
- 多种安装方式
- 详细用法和命令
- 高可用和读写分离
- 优化和压测
- docker与k8s
- docker容器技术
- 1-容器和docker基础知识
- 2-docker软件部署
- 3-docker基础操作命令
- 4-数据的持久化和共享互连
- 5-docker镜像构建
- 6-docker镜像仓库和标签tag
- 7-docker容器的网络通信
- 9-企业级私有仓库harbor
- docker单机编排技术
- 1-docker-compose快速入门
- 2-compose命令和yaml模板
- 3-docker-compose命令
- 4-compose/stack/swarm集群
- 5-命令补全和资源限制
- k8s容器编排工具
- mvn的dockerfile打包插件
- openstack与KVM
- kvm虚拟化
- 1-KVM基础与快速部署
- 2-KVM日常管理命令
- 3-磁盘格式-快照和克隆
- 4-桥接网络-热添加与热迁移
- openstack云平台
- 1-openstack基础知识
- 2-搭建环境准备
- 3-keystone认证服务部署
- 4-glance镜像服务部署
- 5-nova计算服务部署
- 6-neutron网络服务部署
- 7-horizon仪表盘服务部署
- 8-启动openstack实例
- 9-添加计算节点流程
- 10-迁移glance镜像服务
- 11-cinder块存储服务部署
- 12-cinder服务支持NFS存储
- 13-新增一个网络类型
- 14-云主机冷迁移前提设置
- 15-VXALN网络类型配置
- 未分类杂项
- 部署环境准备
- 监控
- https证书
- python3.6编译安装
- 编译安装curl[7.59.0]
- 修改Redhat7默认yum源为阿里云
- 升级glibc至2.17
- rabbitmq安装和启动
- rabbitmq多实例部署[命令方式]
- mysql5.6基础my.cnf
- centos6[upstart]/7[systemd]创建守护进程
- Java启动参数详解
- 权限控制方案
- app发包仓库
- 版本发布流程
- elk日志系统
- rsyslog日志统一收集系统
- ELK系统介绍及YUM源
- 快速安装部署ELK
- Filebeat模块讲解
- logstash的in/output模块
- logstash的filter模块
- Elasticsearch相关操作
- ES6.X集群及head插件
- elk收集nginx日志(json格式)
- kibana说明-汉化-安全
- ES安装IK分词器
- zabbix监控
- zabbix自动注册模板实现监控项自动注册
- hadoop大数据集群
- hadoop部署
- https证书
- certbot网站
- jenkins与CI/CD
- 01-Jenkins部署和初始化
- 02-Jenkins三种插件安装方式
- 03-Jenkins目录说明和备份
- 04-git与gitlab项目准备
- 05-构建自由风格项目和相关知识
- 06-构建html静态网页项目
- 07-gitlab自动触发项目构建
- 08-pipelinel流水线构建项目
- 09-用maven构建java项目
- iptables
- 01-知识概念
- 02-常规命令实战
- 03-企业应用模板
- 04-企业应用模板[1键脚本]
- 05-企业案例-共享上网和端口映射
- SSH与VPN
- 常用VPN
- VPN概念和常用软件
- VPN之PPTP部署[6.x][7.x]
- 使用docker部署softether vpn
- softEther-vpn静态路由表推送
- SSH服务
- SSH介绍和部署
- SSH批量分发脚本
- 开启sftp日志并限制sftp访问目录
- sftp账号权限分离-开发平台
- ssh配置文件最佳实践
- git-github-gitlab
- git安装部署
- git详细用法
- github使用说明
- gitlab部署和使用
- 缓存数据库
- zookeeper草稿
- mongodb数据库系列
- mongodb基本使用
- mongodb常用命令
- MongoDB配置文件详解
- mongodb用户认证管理
- mongodb备份与恢复
- mongodb复制集群
- mongodb分片集群
- docker部署mongodb
- memcached
- memcached基本概念
- memcached部署[6.x][7.x]
- memcached参数和命令
- memcached状态和监控
- 会话共享和集群-优化-持久化
- memcached客户端-web端
- PHP测试代码
- redis
- 1安装和使用
- 2持久化-事务-锁
- 3数据类型和发布订阅
- 4主从复制和高可用
- 5redis集群
- 6工具-安全-pythonl连接
- redis配置文件详解
- 磁盘管理和存储
- Glusterfs分布式存储
- GlusterFS 4.1 版本选择和部署
- Glusterfs常用命令整理
- GlusterFS 4.1 深入使用
- NFS文件存储
- NFS操作和部署
- NFS文件系统-挂载和优化
- sersync与inotify
- rsync同步服务
- rsyncd.conf
- rsync操作和部署文档
- rsync常见错误处理
- inotify+sersync同步服务
- inotify安装部署
- inotify最佳脚本
- sersync安装部署
- 时间服务ntp和chrony
- 时间服务器部署
- 修改utc时间为cst时间
- 批量操作与自动化
- cobbler与kickstart
- KS+COBBLER文件
- cobbler部署[7.x]
- kickstart部署[7.x]
- kickstar-KS文件和语法解析
- kickstart-PXE配置文件解析
- 自动化之ansible
- ansible部署和实践
- ansible剧本编写规范
- 配置文件示例
- 内网DNS服务
- 压力测试
- 压测工具-qpefr测试带宽和延时