
文件结构

<hr>
1.创建基本目录结构
#切换到root用户
mkdir /data/docker-prometheusp
mkdir /data/docker-prometheus/{grafana,prometheus,alertmanager} -p
cd /data/docker-prometheus/
<hr>
2.创建alertmanager的配置文件
vi alertmanager/config.yml
global:
#163
smtp_smarthost: 'smtp.163.com:465'
#fa you jian de you xiang
smtp_from: 'sanyii31@163.com'
smtp_auth_username: 'sanyii31@163.com'
smtp_auth_password: '123456'
smtp_require_tls: false
route:
group_by: ['alertname']
group_wait: 10s
group_interval: 10s
repeat_interval: 10m
receiver: email
receivers:
- name: 'email'
email_configs:
- to: 'sanyii31@163.com'
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname','dev','instance']
<hr>
3.创建grafana的配置文件
vi grafana/config.monitoring
# admin登录密码为password
GF_SECURITY_ADMIN_PASSWORD:password
GF USERS ALLOW SIGN UP=false
<hr/>
4.创建prometheus的配置文件
vi prometheus/prometheus.yml
global:
scrape_interval: "15s" # 将搜刮时间改为15秒,默认一分钟
evaluation_interval: "15s" #每15秒评估一次规则,默认一分钟
alerting:
alertmanagers:
- static_configs:
- targets: ["alertmanager:9093"]
rule_files: #报警配置(触发器)
- "alert.yml"
scrape_configs: # 搜刮配置,一共创建5个Prometheus监控项
- job_name: "prometheus"
scrape_interval: "15s" #
static_configs:
- targets: ["localhost:9090"] # 修改为Prometheus自身的地址和端口
- job_name: "alertmanager"
scrape_interval: "15s"
static_configs:
- targets: ["alertmanager:9093"]
- job_name: "cadvisor"
scrape_interval: "15s"
static_configs:
- targets: ["cadvisor:8080"]
labels:
instance: "cadvisor-server" # 修改为更具体的实例名称
- job_name: "node-exporter"
scrape_interval: "15s"
static_configs:
- targets: ["node-exporter:9100"]
labels:
instance: "Prometheus服务器" # 修改为更具体的实例名称
<hr>
5 . 创建prometheus的告警文件
vi prometheus/alert.yml
groups:
- name:Prometheus alert
rules:
#对任何实例超过30秒无法联系的情况发出警报
- alert:服务告警
expr:up0
for:30s
labels:
severity: critical
annotations:
summary:“服务异常,实例:{{$labels.instance }}
description:"{{slabels.job }}服务已关用”
<hr>
6 .创建docker-compose.yaml文件
vi docker-compose.yaml
# 存储卷
volumes:
prometheus_data: {}
grafana_data: {}
networks:
monitoring:
driver: bridge
services:
prometheus:
image: registry.cn-hangzhou.aliyuncs.com/ldw520/prometheus:latest #镜像源
container_name: prometheus
restart: always
volumes:
- /etc/localtime:/etc/localtime:ro #本地时区挂载在镜像中
- ./prometheus/:/etc/prometheus/
- prometheus_data:/prometheus #数据存储位置
command :
- '--config.file=/etc/prometheus/prometheus.yml'
- '--storage.tsdb.path=/prometheus'
- '--web.console.libraries=/usr/share/prometheus/console_libraries'
- '--web.console.templates=/usr/share/prometheus/consoles' #控制台机
#热加戟配置
- '--web.enable-lifecycle'
#历史数据最大保窗时间,默认15天
- '--storage.tsdb.retention.time=30d'
networks:
- monitoring
links:
- alertmanager
- cadvisor
- node_exporter
expose:
- '9090'
ports:
- 9090:9090
depends_on:
- cadvisor #等待cadvisor日动完成后prometheu5再启动
alertmanager:
image: registry.cn-hangzhou.aliyuncs.com/ldw520/alertmanager:latest #镜像源
container_name: alertmanager
restart: always
volumes:
- /etc/localtime:/etc/localtime:ro
- ./alertmanager/:/etc/alertmanager/
command:
- '--config.file=/etc/alertmanager/config.yml'
- '--storage.path=/alertmanager'
networks:
- monitoring
expose:
- '9093'
ports:
- 9093:9093
# 监控容卻
cadvisor:
image: registry.cn-hangzhou.aliyuncs.com/ldw520/cadvisor:latest #镜像源
container_name: cadvisor
restart: always
volumes:
- /etc/localtime:/etc/localtime:ro
- /:/rootfs:ro
- /var/run:/var/run:rw
- /sys:/sys:ro
- /var/lib/docker/:/var/lib/docker:ro
networks:
- monitoring
expose:
- '8080'
node_exporter:
image: registry.cn-hangzhou.aliyuncs.com/ldw520/node-exporter:v1.8.0 #镜像源
container_name: node-exporter
restart: always
volumes:
- /etc/localtime:/etc/localtime:ro
- /proc:/host/proc:ro
- /sys:/host/sys:ro
- /:/rootfs:ro
command:
- '--path.procfs=/host/proc'
- '--path.sysfs=/host/sys'
- '--collector.filesystem.ignored-mount-points=^/(sys|proc|dev|host|etc)($$|/)'
networks:
- monitoring
ports:
- '9100:9100'
grafana:
image: registry.cn-hangzhou.aliyuncs.com/ldw520/grafana:9.3.16 #镜像源
container_name: grafana
restart: always
volumes:
- /etc/localtime:/etc/localtime:ro
- grafana_data:/var/lib/grafana
- ./grafana/provisioning/:/etc/grafana/provisioning/
env_file:
- ./grafana/config.monitoring
networks:
- monitoring
links:
- prometheus
ports:
- 3000:3000
depends_on:
- prometheus
<hr>
7.查看文件夹树
yum intall -y tree
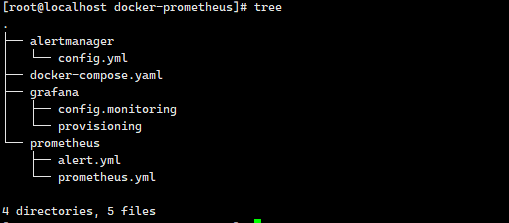
<hr>
8.运行docker-compose
cd /data/docker-compose
docker-compose up -d (-d后台运行)
<hr>
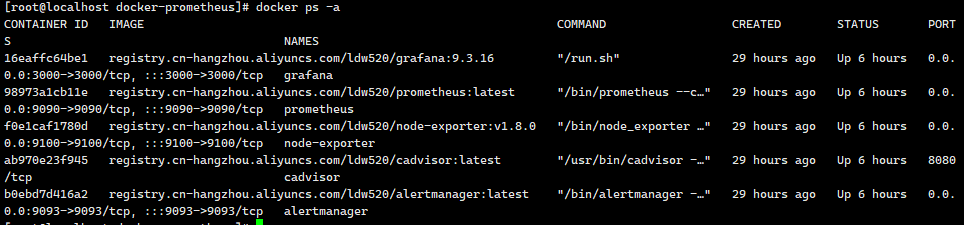
9.检查运行状态
docker images #查看镜像是否已下载
docker ps -a #发现5个镜像都处于 up运行状态
ss -lntp|egrep "3000|9090|9100|9093" #检查端口

<hr>
10.web访问地址
应用 | 访向地址 | 账号/密码
prometheus | http://centosip:9090/ | 无
grafana | http://centosip:3000/ | admin/password
alertmanager | http://centosip:9093/ | 无
node_exporter | http://centosip:9100 | 无
- Prometheus教程
- 一. dokcer 安装
- 二. 安装docker-compose
- 三. docker-compose安装Prometheus
- 四. 配置grafana的数据源
- 五. Prometheus的Exporter
- 六. Prometheus的基本术语
- 七. 监控Linux
- 八. 监控redis和mongodb
- 九. 监控mysql数据库
- 十. 监控go程序
- 十一. 监控nginx
- 十二. 监控消息队列
- 十三. 监控docker
- 十四. 监控进程
- 十五. 域名监控
- 十六. SNMP监控
- 十七. 黑盒监控
- 十八. 自定义监控
- 十九. go实现自定义监控
- 二十. 服务发现概述
- 二十一. 基于文件的服务发现
- 二十二. 基于Consul的服务发现
- 二十三. relabeling机制