
Prometheus的基本术语
一、时间序列
1.1 时间序列数据库
Prometheus会将所有采集到的样本数据以时间序列(time·series)的方式保存在内存数据库中,并且定时保存到硬盘上。
1.2 时间序列的概念
时间序列指在连续等间隔的时间点上获取的数据值,存储时间序列数据的数据库称为时间序列数据库Time Series Database(TSDB),时间序列数据库特点是写远大于读,并且写入平稳,基本不会涉及更新操作,
1.3 时间序列的主要名词
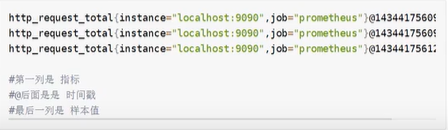
指标(metric):metric name和描述当前样本特征的labelsets;

时间戳(timestamp):一个精确到毫秒的时间截:
样本值(value):一个folat64的浮点型数据表示当前样本的值。
prometheus的metric的样例:
<hr>
二、指标Metrics的四种类型
Prometheus 客户端库主要提供四种主要的 指标metric 类型:
1.Counter(计数器):一种累加的metric,典型的应用如:请求的个数,结束的任务数,出现的错误数等等。

2.Gauge(仪表盘):一种常规的metric,仪表盘,类似折线图,典型的应用如:温度、内存使用率,运行的 goroutines 的个数,可以任意加减。

3.Histogram(直方图):可以理解为柱状图,典型的应用如:请求持续时间,响应大
小,可以对观察结果采样,分组及统计。
4.Summary(摘要):类似于Histogram,典型的应用如:请求持续时间,响应大小,提供观测值的 count 和 sum 功能,提供百分位的功能,即可以按百分比划分跟踪结果。
prometheus主要用于监控 web 应用一需要暴露 metrics 端点,也可以监控服务器
<hr>
三、监控的四个黄金指标
4个黄金指标可以在服务级别帮助衡量终端用户体验、服务中断、业务影响等层面的问题。主要关注与以下四种类型的指标:挺迟,通讯量,错误以及饱和度:
1.延迟:服务请求所需时间。
记录用户所有请求所需的时间,重点是要区分成功请求的延迟时间和失败请求的延迟时间。例如在数据库或者其他关键祸端服务异常触发HTTP500的情况下,用户也可能会很快得到请求失败的响应内容,如果不加区分计算这些请求的延迟,可能导致计算结果与实际结果产生巨大的差异。除此以外,在微服务中通常提“快速失败",开发人员需要特别注意这些延迟较大的错误,因为这些缓慢的错误会明显影响系统的性能,因此追踪这些错误的延迟也是非常重要的。
2.通讯量:监控当前系统的流量,用于衡量服务的容量需求。
申流量对于不同类型的系统而言可能代表不同的含义。例如,在HTTPRESTAPI中,流量通
常是每秒HTTP请求数;。错误:监控当前系统所有发生的错误请求,衡量当前系统错误发生的速率。对于失败而言有些是显式的(比如,HTTP 500错误),而有些是隐式(比如,HTTP响应200,单实际业务流程依然是失败的)。对于一些显式的错误如HTTP500可以通过在负载均衡器(如Nginx)上进行捕获,而对于一些系统内部的异常,则可能需要直接从服务中添加钩子统计并进行获取。
3.饱和度:衡量当前服务的饱和度。
主要强调最能影响服务状态的受限制的资源。例如,如果系统主要受内存影响,那就主要关注系统的内存状态,如果系统主要受限与磁盘I/0,那就主要观测磁盘I/0的状态。因为通常情况下,当这些资源达到饱和后,服务的性能会明显下降。同时还可以利用饱和度对系统做出预测,比如,“磁盘是否可能在4个小时候就满了”。
4.RED方法
RED方法是Weave Cloud在基于Google的“4个黄金指标”的原则下结合Prometheus以及容器实践,细化和总结的方法论,特别适合于云原生应用以及微服务架构应用的监控和度量。主要关注以下三种关键指标:
1.(请求)速率:服务每秒接收的请求数。
2.(请求)错误:每秒失败的请求数。
3.(请求)耗时:每个请求的耗时。
在“4大黄金信号”的原则下,RED方法可以有效的帮助用户衡量云原生以及微服务应用下
的用户体验问题
- Prometheus教程
- 一. dokcer 安装
- 二. 安装docker-compose
- 三. docker-compose安装Prometheus
- 四. 配置grafana的数据源
- 五. Prometheus的Exporter
- 六. Prometheus的基本术语
- 七. 监控Linux
- 八. 监控redis和mongodb
- 九. 监控mysql数据库
- 十. 监控go程序
- 十一. 监控nginx
- 十二. 监控消息队列
- 十三. 监控docker
- 十四. 监控进程
- 十五. 域名监控
- 十六. SNMP监控
- 十七. 黑盒监控
- 十八. 自定义监控
- 十九. go实现自定义监控
- 二十. 服务发现概述
- 二十一. 基于文件的服务发现
- 二十二. 基于Consul的服务发现
- 二十三. relabeling机制