
[TOC]
# <span style="font-size:15px">1、查看文件内容或者合并文件:cat [-AbeEnstTuv] [--help] [--version] fileName</span>
> * -n 或 --number:由 1 开始对所有输出的行数编号。
> * -b 或 --number-nonblank:和 -n 相似,只不过对于空白行不编号。
> * -s 或 --squeeze-blank:当遇到有连续两行以上的空白行,就代换为一行的空白行。
> * -v 或 --show-nonprinting:使用 ^ 和 M- 符号,除了 LFD 和 TAB 之外。
> * -E 或 --show-ends: 在每行结束处显示 $。
> * -T 或 --show-tabs: 将 TAB 字符显示为 ^I。
> * -A, --show-all:等价于 -vET。
> * -e:等价于"-vE"选项;
> * -t:等价于"-vT"选项;
| 命令 | 注释 |
| --- | --- |
| cat textfile |把textfile的文档内容输出打印出来 |
| cat -n textfile1 > textfile2 | 把 textfile1 的文档内容加上行号后输入 textfile2 这个文档里 |
| cat -b textfile1 textfile2 > textfile3 | 把 textfile1 和 textfile2 的文档内容加上行号(空白行不加)之后将内容附加到 textfile3 文档里 |
| cat /dev/null > textfile2 | 清空textfile2文档内容|
# <span style="font-size:15px">2、显示文件的详细信息:stat [option] filename</span>
> * -f :不显示文件本身的信息,显示文件所在文件系统的信息
> * -t:以更简洁的方式输出,只显示摘要信息
> * -c:格式化输出。如 stat -c 格式代码 filename
|-c:格式化输出参数 |注释|
| ---| ---|
|%A| 用文件权限代码表示,如-rw-r--r-- |
|%a| 用八进制数字表示文件权限 |
|%b| 占用的区块数量 |
|%B| 用%b计算区块数量时,每一区块的大小,预设是512bytes |
|%D| 用16进制表示设备编号 |
|%d| 用10进制表示设备编号 |
|%F|显示文件形态,即文件类型|
|%f|raw mode以16进制表示|
|%G| 文件拥有者的组名|
|%g|文件拥有着的群组编号|
|%h|硬链接的数量|
|%i|inode编号|
|%N|将符号链接的文件明和其指向的文件的文件名,用引号包含,'1.sh'->'h.sh'|
|$n|文件名|
|%o|IO区块的大小,预设是4096bytes|
|%s|文件大小|
|%T|16进制表示Minor次要设备代码|
|%t|16进制表示Major主要设备代码|
|%U|文件拥有者的使用者名称|
|%u|文件拥有者的使用者编号|
|%X|访问时间,时间戳显示|
|%x|访问时间|
|%Y|修改时间,时间戳显示|
|%y|修改时间|
|%Z|最近改动时间,时间戳显示|
|%z|最近改动时间|
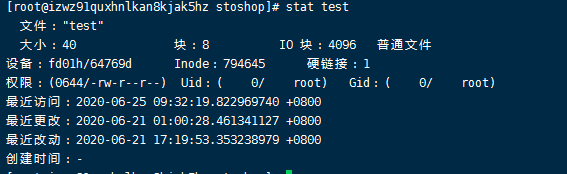
简单的介绍一下stat命令显示出来的文件其他信息:
File:显示文件名,Size:显示文件大小,Blocks:文件使用的数据块总数,IO Block:IO块大小,regular file:文件类型(常规文件),Device:设备编号,Inode:Inode号,Links:链接数,Access:文件的权限,Gid、Uid:文件所有权的Gid和Uid,以及linux下的三个时间:
1、 Access Time(访问时间):简写为atime,表示文件的访问时间。当文件内容被访问时,更新这个时间
2、Modify Time(修改时间):简写为mtime,表示文件内容的修改时间,当文件的数据内容被修改时,更新这个时间。
3、 Change Time(最近改动时间):简写为ctime,表示文件的状态时间,当文件的状态被修改时,更新这个时间,例如文件的链接数,大小,权限,Blocks数。
> 1、当读取文件时,access time会发生改变,modify、change time会发生改变
> 2、当修改文件时,acces、modify、change time都会发生改变
> 3、当修改属性时,change time会发生改变,access、modify time不会发生改变
> 4、more、less、cat、tail 等命令会改变 access time,ls、stat命令不会改变access time
> 5、通过 chown、chmod修改文件属性时,会更新change time,touch命令会同时更新这三个时间
|命令|注释|
| ---| ---|
|stat test.txt| 显示文件的详细信息|
|stat -c %a%A test.txt | 644-rw-r--r\-\- |
|ls -lc test.txt | 查看文件的最近改动时间(change time) |
|ls -lu test.txt | 查看文件的最近访问时间(access time) |
|ls -l test.txt | 查看文件的最近修改时间(modify time) |
# <span style="font-size:15px">3、只查看文件的开头部分的内容:head [option] [文件]</span>
> * -q 隐藏文件名
> * -v 显示文件名
> * -c 显示的字节数。
> * -n 显示的行数。默认为 10,即显示 10 行的内容。
| 命令 | 注释 |
| --- | --- |
| head -c 20 text.txt |显示文件前 20 个字节 |
| head -n 20 text.txt |显示文件前 20 行 |
# <span style="font-size:15px">4、查看文件最尾部的内容:tail [option] [文件]</span>
> * -f 循环读取
> * -q 不显示处理信息
> * -v 显示详细的处理信息
> * -c 显示的字节数
> * -n 显示文件的尾部 n 行内容
> * --pid=PID 与-f合用,表示在进程ID,PID死掉之后结束
> * -q, --quiet, --silent 从不输出给出文件名的首部
> * -s, --sleep-interval=S 与-f合用,表示在每次反复的间隔休眠S秒
| 命令 | 注释 |
| --- | --- |
| tail -f filename |把 filename 文件里的最尾部的内容显示在屏幕上,并且不断刷新,只要 filename 更新就可以看到最新的文件内容 |
| tail notes.log |显示 notes.log 文件的最后 10 行 |
|tail -c 10 notes.log|显示文件 notes.log 的最后 10 个字符|
# <span style="font-size:15px">5、显示文件属性:lsattr [-adlRvV][文件或目录...]</span>
>* -a 显示所有文件和目录,包括以"."为名称开头字符的额外内建,现行目录"."与上层目录".."。
>* -d 显示,目录名称,而非其内容。
>* -l 此参数目前没有任何作用。
>* -R 递归处理,将指定目录下的所有文件及子目录一并处理。
>* -v 显示文件或目录版本。
>* -V 显示版本信息。
| 命令 | 注释 |
| --- | --- |
| lsattr test | 显示test文件的文件属性 |
# <span style="font-size:15px">6、改变文件属性:chattr [-RV][-v<版本编号>][+-=<属性>][文件或目录...]</span>
> 这项指令可改变存放在ext2文件系统上的文件或目录属性,这些属性共有以下8种模式:
> 1. a:让文件或目录仅供附加用途。
> 2. b:不更新文件或目录的最后存取时间。
> 3. c:将文件或目录压缩后存放。
> 4. d:将文件或目录排除在倾倒操作之外。
> 5. i:不得任意更动文件或目录。
> 6. s:保密性删除文件或目录。
> 7. S:即时更新文件或目录。
> 8. u:预防意外删除。
>
> 参数:
>* -R 递归处理,将指定目录下的所有文件及子目录一并处理。
>* -v 设置文件或目录版本。
>* -V 显示指令执行过程。
>* +开启文件或目录的该项属性。
>* -关闭文件或目录的该项属性。
>* = 指定文件或目录的该项属性。
| 命令 | 注释 |
| --- | --- |
| chattr +i test.txt | 用chattr命令防止系统中某个关键文件被修改。此时使用lsattr命令查看属性:----i--------e-- test.txt |
| chattr +a text.txt | 让某个文件只能往里面追加数据,但不能删除,适用于各种日志文件。此时使用lsattr命令查看属性:----a--------e-- test.txt |
# <span style="font-size:15px">7、统计文件的字数:wc [-clw][文件]</span>
> * \-c或--bytes或--chars 只显示Bytes数。
>* \-l或--lines 只显示行数。
>* \-w或--words 只显示字数。
| 命令 | 注释 |
| --- | --- |
| wc test.log | 默认的情况下,wc将计算指定文件的行数、字数,以及字节数 |
|cat /proc/cpuinfo \| grep 'core id' \| sort -u\| wc -l | 与grep配合使用,统计文件内某字符的行数,此命令为查询cpu核数|
# <span style="font-size:15px">8、查看文本汇总的重复列:uniq [-cdu][-f<栏位>][-s<字符位置>][-w<字符位置>][输入文件][输出文件]</span>
> 注意:该命令是用于去掉文件中相邻数据重复的行,经常与sort命令配合使用
>* \-c 在每列旁边显示该行重复出现的次数。
>* \-d 仅显示重复出现的行列。
>* \-f 忽略比较指定的栏位。
>* \-s 忽略比较指定的字符。
>* \-u 仅显示出一次的行列。
>* \-w 指定要比较的字符。
>* \[输入文件\] 指定已排序好的文本文件。如果不指定此项,则从标准读取数据;
>* \[输出文件\] 指定输出的文件。如果不指定此选项,则将内容显示到标准输出设备(显示终端)
| 命令 | 注释 |
| --- | --- |
|uniq test.log| 打印删除重复行之后的结果|
|uniq -u test.log| 打印出文本中仅出现一次的行|
|uniq -c test.log test1.log| 检查文件并删除文件中重复出现的行,并在行首显示该行重复出现的次数,并将结果输入至test1.log文件中|
|sort test.log \| uniq| 如果文件内重复行并不相邻,uniq 命令是不起作用的,需要先用sort进行排序,再使用uniq命令|
# <span style="font-size:15px">9、排序文本内容:sort [-bcdfimMnr][-o<输出文件>][-t<分隔字符>][+<起始栏位>-<结束栏位>][文件]</span>
>* \-b 忽略每行前面开始出的空格字符。
>* \-c 检查文件是否已经按照顺序排序。
>* \-d 排序时,处理英文字母、数字及空格字符外,忽略其他的字符。
>* \-f 排序时,将小写字母视为大写字母。
>* -h 按照文件大小倒叙显
>* \-i 排序时,除了040至176之间的ASCII字符外,忽略其他的字符。
>* \-m 将几个排序好的文件进行合并。
>* \-M 将前面3个字母依照月份的缩写进行排序,比如JAN小于FEB。
>* \-n 依照数值的大小排序。
>* \-u 去重排序。
>* \-o 将排序后的结果存入指定的文件。
>* \-r 降序排序,默认的排序方式是升序。
>* \-t 指定排序时所用的栏位分隔字符
>* -k 定义排序键值字段,当出现多个-k选项时候,会先从第一个键值开始排序,找出匹配该键值的记录后,再进行第二个键值字段的排序,以此类推
| 命令 | 注释 |
| --- | --- |
|sort test.log|默认情况下,将文本内容的第一列以ASCII 码的次序排列|
|sort -o test1.log -u test.log | 去重排序test.log内容,并将结果保存至test1.log |
```
// -t与-k参数使用实例
[root@izwz91quxhnlkan8kjak5hz ~]# cat test
google:150:2000
baidu:100:3000
sougou:90:4000
sohu:100:4500
[root@izwz91quxhnlkan8kjak5hz ~]# sort -t : -k 2n test // 以冒号隔开的第二个字段以整数类型进行排序
sougou:90:4000
baidu:100:3000
sohu:100:4500
google:150:2000
[root@izwz91quxhnlkan8kjak5hz ~]# sort -t : -k2n -k3nr test // 以冒号隔开的第二个字段进行排序,当数值相等时,以第三个字段进行排序
sougou:90:4000
sohu:100:4500
baidu:100:3000
google:150:2000
[root@izwz91quxhnlkan8kjak5hz ~]# sort -t : -k1.1 test // 以冒号隔开的第一个字段的第一个字母进行排序
baidu:100:3000
google:150:2000
sohu:100:4500
sougou:90:4000
```
# <span style="font-size:15px">10、显示每行从开头算起 num1 到 num2 的文字:cut [option] 文件</span>
>* \-b :以字节为单位进行分割。这些字节位置将忽略多字节字符边界,除非也指定了 -n 标志。
>* \-c :以字符为单位进行分割(适用于中文)。
>* \-d :自定义分隔符,默认为制表符。
>* \-f :与-d一起使用,指定显示哪个区域。
> * -n :
> * n:只有第n项
> * n-:从第n项一直到行尾
> * n-m:从第n项到第m项(包括m)
> * -m:从一行的开始到第m项(包括m)
> * -:从一行的开始到结束的所有项
| 命令 | 注释 |
| --- | --- |
| head -5 /etc/passwd \| cut -d : -f 1,3-5| 以冒号隔开的passwd文件前五行内容,显示第一、第三至五项字段 |
| head -5 /etc/passwd \| cut -b 1-3| 取每行的第1-3字字节 |
# <span style="font-size:15px">11、文本处理文件:awk '{[pattern] action}' {filenames}</span>
> option:
> * \-F fs or --field-separator fs:指定输入文件折分隔符,fs是一个字符串或者是一个正则表达式,如-F:
> * \-v var=value or --asign var=value:赋值一个用户定义变量
> * \-f scripfile or --file scriptfile:从脚本文件中读取awk命令
>
> 脚本关键字:
> * BEGIN{ 这里面放的是执行前的语句 }
> * END {这里面放的是处理完所有的行后要执行的语句 }
> * {这里面放的是处理每一行时要执行的语句}
>
> 内建变量:
> * $n:当前记录的第n个字段,字段间由FS分隔
> * $0:完整的输入记录
> * ARGC:命令行参数的数目
> * ARGIND:命令行中当前文件的位置(从0开始算)
> * ARGV:包含命令行参数的数组
> * CONVFMT:数字转换格式(默认值为%.6g)ENVIRON环境变量关联数组
> * ERRNO:最后一个系统错误的描述
> * FIELDWIDTHS:字段宽度列表(用空格键分隔)
> * FILENAME:当前文件名
> * FNR:各文件分别计数的行号
> * FS:字段分隔符(默认是任何空格)
> * IGNORECASE:如果为真,则进行忽略大小写的匹配
> * NF:一条记录的字段的数目
> * NR:已经读出的记录数,就是行号,从1开始
> * OFMT:数字的输出格式(默认值是%.6g)
> * OFS:输出记录分隔符(输出换行符),输出时用指定的符号代替换行符
> * ORS:输出记录分隔符(默认值是一个换行符)
> * RLENGTH:由match函数所匹配的字符串的长度
> * RS:记录分隔符(默认是一个换行符)
> * RSTART:由match函数所匹配的字符串的第一个位置
> * SUBSEP:数组下标分隔符(默认值是/034)
| 命令实例 | 注释 |
| --- | --- |
|cat test.txt \| awk -F/ '{print $1}'| 读取test.txt文件,按 \/分割,并输出第一段内容。'{print $NF}':最后一列;'{print $NF-1}':倒数第二列 |
| awk '{if(NR<=4 && NR>=2) print $1}' score.txt|输出第二行到第四行的第一列|
|awk '/mall/' test.txt<br>效果同:sed -n '/mall/p' url.txt|显示文件中含有mall的行|
| awk -F/ '{print $1,$3}' OFS="$" test.txt | 按 \/分割,并输出第一段,第三段内容,并指定分隔符“$” |
| awk 'BEGIN{IGNORECASE=1} /this/' test.txt | 忽略大小写,匹配this字符 |
|awk 'BEGIN{printf "%.2f%\n",('5'/'20')*100}'|计算百分比|
| cat test.txt \| awk NF \| wc -l| 过滤空行后,统计文件总行数 |
|awk -f cal.awk score.txt|从脚本文件中读取awk命令|
|awk '{sum+=$3} END {print sum}' score.txt | 计算score.txt文件第三列的总和|
| cat transit\_log\_elapsed.txt \| awk '{print $1,$2,$(NF-3),$(NF-2),$(NF-1),$NF}'|获取第一二列和最后的几列|
|cat transit_log_elapsed.txt \| awk 'NR==1 {print $0} END {print $0}' | 获取第一行和最后一行 |
| cat transit_log_elapsed.txt \| awk -F= '$3>50{print $0}' | 只获取某一列的数字大于指定数值的行|
```
// 只获取文件内elapsed的值大于50的行
SIS3.0.58.0 ~ # cat transit_log_elapsed.txt | awk -F= '$3>50{print $0}'
time="2021-05-07T10:13:25+08:00" elapsed=95.835122
time="2021-05-07T10:13:27+08:00" elapsed=54.939698
time="2021-05-07T10:13:29+08:00" elapsed=51.889203
time="2021-05-07T10:13:32+08:00" elapsed=63.37284
time="2021-05-07T10:13:43+08:00" elapsed=3030.551248
time="2021-05-07T10:13:46+08:00" elapsed=51.853267
time="2021-05-07T10:13:47+08:00" elapsed=80.545366
time="2021-05-07T10:13:47+08:00" elapsed=97.63666
time="2021-05-07T10:13:49+08:00" elapsed=57.14669
```
# <span style="font-size:15px">12、匹配文本中的字符串: grep [option] [pattern] [filename] </span>
> 正则表达式参数:
> * -E, --extended-regexp:PATTERN 是一个可扩展的正则表达式(缩写为 ERE)
> * -F, --fixed-strings:PATTERN 是一组由断行符分隔的定长字符串。
> * -G, --basic-regexp:PATTERN 是一个基本正则表达式(缩写为 BRE)
> * -P, --perl-regexp:PATTERN 是一个 Perl 正则表达式
> * -e, --regexp=PATTERN:用 PATTERN 来进行匹配操作
> * -f, --file=FILE:从 FILE 中取得 PATTERN
> * -i, --ignore-case:忽略大小写
> * -w, --word-regexp:强制 PATTERN 仅完全匹配字词
> * -x, --line-regexp:强制 PATTERN 仅完全匹配一行
> * -z, --null-data:一个 0 字节的数据行,但不是空行
> 输出控制:
> * -m, --max-count=NUM:NUM 次匹配后停止
> * -b, --byte-offset:输出的同时打印字节偏移
> * -n, --line-number:输出的同时打印行号
--line-buffered:每行输出清空
> * -H, --with-filename:为每一匹配项打印文件名
> * -h, --no-filename:输出时不显示文件名前缀
--label=LABEL:将LABEL 作为标准输入文件名前缀
> * -o, --only-matching:只显示匹配PATTERN 部分
> * -q, --quiet, --silent:不显示任何信息
> * -a, --text:不要忽略二进制的数据
> * -I:列出文件内容符合指定的样式的文件名称
> * -d, --directories=ACTION:当指定要查找的是目录而非文件时,必须使用这项参数,否则grep指令将回报信息并停止动作,ACTION is 'read', 'recurse', or 'skip'
> * -D, --devices=ACTION: how to handle devices, FIFOs and sockets;ACTION is 'read' or 'skip'
> * -r, --recursive:此参数的效果和指定"-d recurse"参数相同
> * -L, --files-without-match :只打印不匹配的文件名
> * -c, --count:仅打印每个 FILE 匹配行的计数
> * -T, --initial-tab:标签对齐
>
> 文件控制:
> * -B, --before-context=NUM:显示文件里匹配行以及前NUM行
> * -A, --after-context=NUM:显示文件里匹配行以及后NUM行
> * -C, --context=NUM:显示文件里匹配行以及上下NUM行
> * --group-separator=SEP use SEP as a group separator
> * --no-group-separator use empty string as a group separator
> * --colour[=WHEN]:使用标记突出显示匹配的字符串;WHEN is 'always', 'never', or 'auto'
- PHP
- PHP基础
- PHP介绍
- 如何理解PHP是弱类型语言
- 超全局变量
- $_SERVER详解
- 字符串处理函数
- 常用数组函数
- 文件处理函数
- 常用时间函数
- 日历函数
- 常用url处理函数
- 易混淆函数区别(面试题常见)
- 时间戳
- PHP进阶
- PSR规范
- RESTFUL规范
- 面向对象
- 三大基本特征和五大基本原则
- 访问权限
- static关键字
- static关键字
- 静态变量与普通变量
- 静态方法与普通方法
- const关键字
- final关键字
- abstract关键字
- self、$this、parent::关键字
- 接口(interface)
- trait关键字
- instanceof关键字
- 魔术方法
- 构造函数和析构函数
- 私有属性的设置获取
- __toString()方法
- __clone()方法
- __call()方法
- 类的自动加载
- 设计模式详解
- 关于设计模式的一些建议
- 工厂模式
- 简单工厂模式
- 工厂方法模式
- 抽象工厂模式
- 区别和适用范围
- 策略模式
- 单例模式
- HTTP
- 定义
- 特点
- 工作过程
- request
- response
- HTTP状态码
- URL
- GET和POST的区别
- HTTPS
- session与cookie
- 排序算法
- 冒泡排序算法
- 二分查找算法
- 直接插入排序算法
- 希尔排序算法
- 选择排序算法
- 快速排序算法
- 循环算法
- 递归与尾递归
- 迭代
- 日期相关的类
- DateTimeInterface接口
- DateTime类
- DateTimeImmutable类
- DateInterval类
- DateTimeZone类
- DatePeriod类
- format参数格式
- DateInterval的format格式化参数
- 预定义接口
- ArrayAccess(数组式访问)接口
- Serializable (序列化)接口
- Traversable(遍历)接口
- Closure类
- Iterator(迭代器)接口
- IteratorAggregate(聚合迭代器) 接口
- Generator (生成器)接口
- composer
- composer安装与使用
- python
- python3执行tarfile解压文件报错:tarfile.ReadError:file could not be opened successfully
- golang
- 单元测试
- 单元测试框架
- Golang内置testing包
- GoConvey库
- testify库
- 打桩与mock
- GoMock框架
- Gomonkey框架
- HTTP Mock
- httpMock
- mux库/httptest
- 数据库
- MYSQL
- SQL语言的分类
- 事务(重点)
- 索引
- 存储过程
- 触发器
- 视图
- 导入导出数据库
- 优化mysql数据库的方法
- MyISAM与InnoDB区别
- 外连接、内连接的区别
- 物理文件结构
- PostgreSQL
- 编译安装
- pgsql常用命令
- pgsql应用目录(bin目录)文件结构解析
- pg_ctl
- initdb
- psql
- clusterdb
- cluster命令
- createdb
- dropdb
- createuser
- dropuser
- pg_config
- pg_controldata
- pg_checksums
- pgbench
- pg_basebackup
- pg_dump
- pg_dumpall
- pg_isready
- pg_receivewal
- pg_recvlogical
- pg_resetwal
- pg_restore
- pg_rewind
- pg_test_fsync
- pg_test_timing
- pg_upgrade
- pg_verifybackup
- pg_archivecleanup
- pg_waldump
- postgres
- reindexdb
- vacuumdb
- ecpg
- pgsql数据目录文件结构解析
- pgsql数据目录文件结构解析
- postgresql.conf解析
- pgsql系统配置参数说明
- pgsql索引类型
- 四种索引类型解析
- 索引之ctid解析
- 索引相关操作
- pgsql函数解析
- pgsql系统函数解析
- pgsql窗口函数解析
- pgsql聚合函数解析
- pgsql系统表解析
- pg_stat_all_indexes
- pg_stat_all_tables
- pg_statio_all_indexes
- pg_statio_all_tables
- pg_stat_database
- pg_stat_statements
- pg_extension
- pg_available_extensions
- pg_available_extension_versions
- pgsql基本原理
- 进程和内存结构
- 存储结构
- 数据文件的内部结构
- 垃圾回收机制VACUUM
- 事务日志WAL
- 并发控制
- 介绍
- 事务ID-txid
- 元组结构-Tuple Structure
- 事务状态记录-Commit Log (clog)
- 事务快照-Transaction Snapshot
- 事务快照实例
- 事务隔离
- 事务隔离级别
- 读已提交-Read committed
- 可重复读-Repeatable read
- 可序列化-Serializable
- 读未提交-Read uncommitted
- 锁机制
- 扩展机制解析
- 扩展的定义
- 扩展的安装方式
- 自定义创建扩展
- 扩展的管理
- 扩展使用实例
- 在pgsql中使用last、first聚合函数
- pgsql模糊查询不走索引的解决方案
- pgsql的pg_trgm扩展解析与验证
- 高可用
- LNMP
- LNMP环境搭建
- 一键安装包
- 搭建方法
- 配置文件目录
- 服务器管理系统
- 宝塔(Linux)
- 安装与使用
- 开放API
- 自定义apache日志
- 一键安装包LNMP1.5
- LNMP1.5:添加、删除站点
- LNMP1.5:php多版本切换
- LNMP1.5 部署 thinkphp项目
- Operation not permitted解决方法
- Nginx
- Nginx的产生
- 正向代理和反向代理
- 负载均衡
- Linux常用命令
- 目录与文件相关命令
- 目录操作命令
- 文件编辑命令
- 文件查看命令
- 文件查找命令
- 文件权限命令
- 文件上传下载命令
- 用户和群组相关命令
- 用户与用户组的关系
- 用户相关的系统配置文件
- 用户相关命令
- 用户组相关命令
- 压缩与解压相关命令
- .zip格式
- .tar.gz格式
- .gz格式
- .bz2格式
- 查看系统版本
- cpuinfo详解
- meminfo详解
- getconf获取系统信息
- 磁盘空间相关命令
- 查看系统负载情况
- 系统环境变量
- 网络相关命令
- ip命令详解
- ip命令格式详解
- ip address命令详解
- ip link命令详解
- ip rule命令详解
- ip route命令详解
- nslookup命令详解
- traceroute命令详解
- netstat命令详解
- route命令详解
- tcpdump命令详解
- 系统进程相关命令
- ps命令详解
- pstree命令详解
- kill命令详解
- 守护进程-supervisord
- 性能监控相关命令
- top命令详解
- iostat命令详解
- pidstat命令详解
- iotop命令详解
- mpstat命令详解
- vmstat命令详解
- ifstat命令详解
- sar命令详解
- iftop命令详解
- 定时任务相关命令
- ssh登录远程主机
- ssh口令登录
- ssh公钥登录
- ssh带密码登录
- ssh端口映射
- ssh配置文件
- ssh安全设置
- 历史纪录
- history命令详解
- linux开启操作日志记录
- 拓展
- git
- git初始化本地仓库-https
- git初始化仓库-ssh
- git-查看和设置config配置
- docker
- 概念
- docker原理
- docker镜像原理
- docker Overlay2 文件系统原理
- docker日志原理
- docker日志驱动
- docker容器日志管理
- 原理论证
- 验证容器的启动是作为Docker Daemon的子进程
- 验证syslog类型日志驱动
- 验证journald类型日志驱动
- 验证local类型日志驱动
- 修改容器的hostname
- 修改容器的hosts
- 验证联合挂载技术
- 验证启动多个容器对于磁盘的占用情况
- 验证写时复制原理
- 验证docker内容寻址原理
- docker存储目录
- /var/lib/docker目录
- image目录
- overlay2目录
- 数据卷
- 具名挂载和匿名挂载
- 数据卷容器
- Dockerfile详解
- dockerfile指令详解
- 实例:构造centos
- 实例:CMD和ENTRYPOINT的区别
- docker网络详解
- docker-compose
- 缓存
- redis
- redis的数据类型和应用场景
- redis持久化
- RDB持久化
- AOF持久化
- redis缓存穿透、缓存击穿、缓存雪崩
- 常见网络攻击类型
- CSRF攻击
- XSS攻击
- SQL注入
- Cookie攻击
- 历史项目经验
- 图片上传项目实例
- 原生php上传方法实例
- base64图片流
- tp5的上传方法封装实例
- 多级关系的递归查询
- 数组转树结构
- thinkphp5.1+ajax实现导出Excel
- JS 删除数组的某一项
- 判断是否为索引数组
- ip操作