
[TOC]
> last、first聚合函数可以返聚合之后指定列的最后一个或第一条记录的值。
> 在如MongoDB的非关系型数据库中,是支持这两种聚合函数的。但是mysql、pgsql等这些关系型数据库中并没有直接提供last、first聚合函数,如果需要在这些关系型数据库中实现与last、first函数一样的效果,可以通过窗口函数或者其他方式实现。
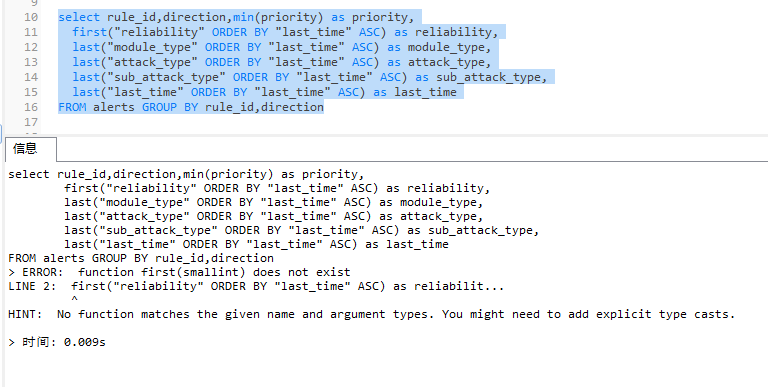
在mysql、pgsql中直接执行last、first聚合函数时会显示报错
首先,创建表结构如下,并随机生成20条数据,其中last_time时间递增。
```
postgres=# select id,rule_id,direction,priority,reliability,module_type,attack_type,sub_attack_type,last_time from alerts order by id
postgres-# \g
id | rule_id | direction | priority | reliability | module_type | attack_type | sub_attack_type | last_time
----+---------+-----------+----------+-------------+-------------+-------------+-----------------+------------
1 | 319 | 209 | 8 | 3 | 86 | 18 | 92 | 1614048983
2 | 319 | 209 | 9 | 6 | 54 | 72 | 79 | 1614048984
3 | 49 | 709 | 3 | 3 | 21 | 3 | 68 | 1614048985
4 | 144 | 508 | 3 | 5 | 37 | 11 | 89 | 1614048986
5 | 585 | 488 | 8 | 3 | 44 | 49 | 63 | 1614048987
6 | 675 | 396 | 5 | 5 | 32 | 27 | 36 | 1614048988
7 | 419 | 209 | 9 | 7 | 29 | 33 | 92 | 1614048989
8 | 903 | 877 | 3 | 6 | 35 | 79 | 81 | 1614048990
9 | 884 | 626 | 5 | 9 | 81 | 35 | 9 | 1614048991
10 | 916 | 574 | 9 | 9 | 71 | 54 | 43 | 1614048992
11 | 884 | 626 | 1 | 2 | 54 | 66 | 80 | 1614048993
12 | 35 | 332 | 8 | 2 | 57 | 24 | 57 | 1614048994
13 | 884 | 626 | 8 | 3 | 37 | 29 | 26 | 1614048995
14 | 825 | 294 | 4 | 8 | 54 | 5 | 42 | 1614048996
15 | 67 | 430 | 2 | 5 | 36 | 5 | 91 | 1614048997
16 | 409 | 134 | 4 | 4 | 78 | 65 | 51 | 1614048998
17 | 962 | 692 | 3 | 1 | 25 | 93 | 4 | 1614048999
18 | 765 | 807 | 4 | 6 | 78 | 83 | 77 | 1614049000
19 | 619 | 512 | 4 | 4 | 45 | 38 | 80 | 1614049001
20 | 619 | 512 | 8 | 1 | 60 | 75 | 45 | 1614049002
(20 rows)
```
需求:按照rule_id,direction字段聚合,priority字段取最小值,module_type、attack_type、sub_attack_type字段取聚合之后最后一条记录的值,reliability字段取最早的一条记录的值。
# <span style="font-size:15px">**第一种方式:通过pgsql的array_agg函数来实现** </span>
> pgsql 的ARRAY\_AGG函数可以将多个值合并到一个数组中,相当于MongoDB的addToSet,这里不做赘述。
> 利用array_agg函数,根据指定字段进行倒序或者升序排序之后,再取第一个值便可以实现。
```
// filter关键字为聚合指定字段时添加过滤,可加可不加,根据需求而定
SELECT "rule_id","direction",
min("priority") as "priority",
(array_agg("reliability" ORDER BY "last_time" ASC) FILTER (WHERE attack_ip = '1.1.1.1'))[1] as "reliability",
(array_agg("module_type" ORDER BY "last_time" DESC) FILTER (WHERE attack_ip = '1.1.1.1'))[1] as "module_type",
(array_agg("attack_type" ORDER BY "last_time" DESC) FILTER (WHERE attack_ip = '1.1.1.1'))[1] as "attack_type",
(array_agg("sub_attack_type" ORDER BY "last_time" DESC) FILTER (WHERE attack_ip = '1.1.1.1'))[1] as "sub_attack_type",
(array_agg("last_time" ORDER BY "last_time" DESC) FILTER (WHERE attack_ip = '1.1.1.1'))[1] as "last_time"
FROM alerts where attack_ip = '1.1.1.1' GROUP BY "rule_id","direction"
```
# <span style="font-size:15px">**第二种方式:通过pgsql 的窗口函数+join方式来实现** </span>
> pgsql提供了first_value、last_value的窗口函数,可以在查询时返回取分组内排序后,截止到当前行的第一个值或者最后一个值,详见 [pgsql窗口函数解析](http://docs.linchunyu.top/2280090)
```
// 先使用first_value、last_value窗口函数,获取指定列的第一个值或者最后一个值之后,再join关联聚合
// 因为外层是聚合,所以必须有聚合函数才可以获取到对应的字段。
// 此时字段已经取得第一个或者最后一个值,因为外层的select获取该字段时,采用min、max都是一样的。
SELECT b.rule_id,b.direction, min(priority) as priority,min(b.reliability) as reliability, min(b.module_type) as module_type,
min(b.attack_type) as attack_type,min(b.sub_attack_type) as sub_attack_type, min(b.last_time) as last_time
from alerts a INNER JOIN (
SELECT id,rule_id,direction,
FIRST_VALUE(reliability)over(partition by rule_id,direction order by last_time asc) as reliability,
FIRST_VALUE(module_type)over(partition by rule_id,direction order by last_time desc) as module_type,
FIRST_VALUE(attack_type)over(partition by rule_id,direction order by last_time desc) as attack_type,
FIRST_VALUE(sub_attack_type)over(partition by rule_id,direction order by last_time desc) as sub_attack_type,
FIRST_VALUE(last_time)over(partition by rule_id,direction order by last_time desc) as last_time
from alerts
) b on a.id = b.id GROUP BY b.rule_id,b.direction
```
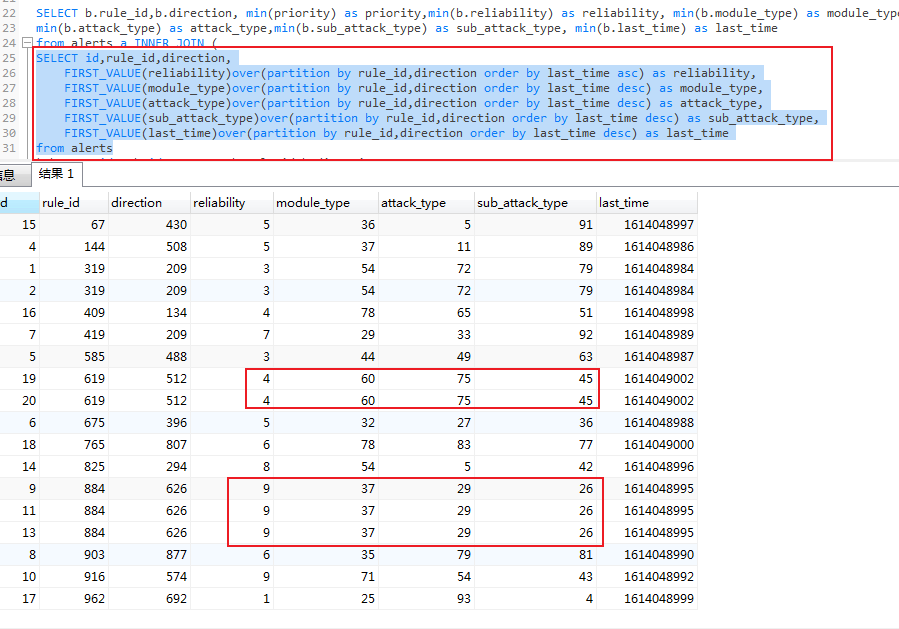
如图,仅执行join内的select语句,使用窗口函数的字段值都是一样的
# <span style="font-size:15px">**第三种方式:创建内置聚合函数(无外部依赖)** </span>
> 此方式为SQL语言实现,没有外部依赖关系。
> 直接在数据库执行以下语句即可,创建完之后可以直接使用last、first函数聚合,[WIKI](https://wiki.postgresql.org/wiki/First/last_(aggregate))
```
-- Create a function that always returns the first non-NULL item
CREATE OR REPLACE FUNCTION public.first_agg ( anyelement, anyelement )
RETURNS anyelement AS $$
SELECT CASE WHEN $1 IS NULL THEN $2 ELSE $1 END;
$$ LANGUAGE SQL STABLE;
-- And then wrap an aggreagate around it
CREATE AGGREGATE public.first (
sfunc = public.first_agg,
basetype = anyelement,
stype = anyelement
);
-- Create a function that always returns the last non-NULL item
CREATE OR REPLACE FUNCTION public.last_agg ( anyelement, anyelement )
RETURNS anyelement AS $$
SELECT $2;
$$ LANGUAGE SQL STABLE;
-- And then wrap an aggreagate around it
CREATE AGGREGATE public.last (
sfunc = public.last_agg,
basetype = anyelement,
stype = anyelement
);
```
```
// 此方式可以直接使用last、first聚合函数,对指定字段进行取第一条/最后一条的操作,同时支持根据指定字段进行排序
// 如reliability字段,实际上是聚合之后,根据last_time升序排序之后取第一条
select rule_id,direction,min(priority) as priority,
first("reliability" ORDER BY "last_time" ASC) as reliability,
last("module_type" ORDER BY "last_time" ASC) as module_type,
last("attack_type" ORDER BY "last_time" ASC) as attack_type,
last("sub_attack_type" ORDER BY "last_time" ASC) as sub_attack_type,
last("last_time" ORDER BY "last_time" ASC) as last_time
FROM alerts GROUP BY rule_id,direction
```
# <span style="font-size:15px">**第四种方式:引入外部聚合扩展(有外部依赖)** </span>
[外部last_first聚合扩展库下载地址](https://debian.pkgs.org/sid/debian-main-amd64/postgresql-13-first-last-agg_0.1.4-4-gd63ea3b-3+b1_amd64.deb.html)
详见 [pgsql安装扩展](http://docs.linchunyu.top/2280100)
<br>
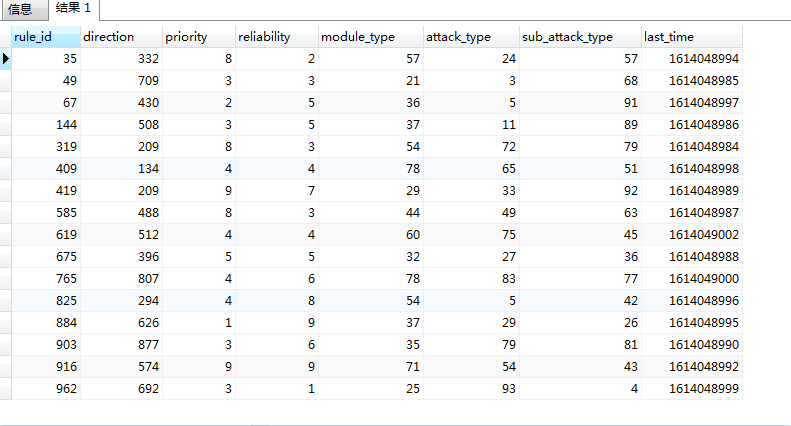
**结果分析:**
以上语句执行结果都是相同的,如下,可以对比建表时的数据。
如rule_id为884、direction为626的数据,取最第一个reliability的值,则是id为9的数据对应的reliability字段值。
- PHP
- PHP基础
- PHP介绍
- 如何理解PHP是弱类型语言
- 超全局变量
- $_SERVER详解
- 字符串处理函数
- 常用数组函数
- 文件处理函数
- 常用时间函数
- 日历函数
- 常用url处理函数
- 易混淆函数区别(面试题常见)
- 时间戳
- PHP进阶
- PSR规范
- RESTFUL规范
- 面向对象
- 三大基本特征和五大基本原则
- 访问权限
- static关键字
- static关键字
- 静态变量与普通变量
- 静态方法与普通方法
- const关键字
- final关键字
- abstract关键字
- self、$this、parent::关键字
- 接口(interface)
- trait关键字
- instanceof关键字
- 魔术方法
- 构造函数和析构函数
- 私有属性的设置获取
- __toString()方法
- __clone()方法
- __call()方法
- 类的自动加载
- 设计模式详解
- 关于设计模式的一些建议
- 工厂模式
- 简单工厂模式
- 工厂方法模式
- 抽象工厂模式
- 区别和适用范围
- 策略模式
- 单例模式
- HTTP
- 定义
- 特点
- 工作过程
- request
- response
- HTTP状态码
- URL
- GET和POST的区别
- HTTPS
- session与cookie
- 排序算法
- 冒泡排序算法
- 二分查找算法
- 直接插入排序算法
- 希尔排序算法
- 选择排序算法
- 快速排序算法
- 循环算法
- 递归与尾递归
- 迭代
- 日期相关的类
- DateTimeInterface接口
- DateTime类
- DateTimeImmutable类
- DateInterval类
- DateTimeZone类
- DatePeriod类
- format参数格式
- DateInterval的format格式化参数
- 预定义接口
- ArrayAccess(数组式访问)接口
- Serializable (序列化)接口
- Traversable(遍历)接口
- Closure类
- Iterator(迭代器)接口
- IteratorAggregate(聚合迭代器) 接口
- Generator (生成器)接口
- composer
- composer安装与使用
- python
- python3执行tarfile解压文件报错:tarfile.ReadError:file could not be opened successfully
- golang
- 单元测试
- 单元测试框架
- Golang内置testing包
- GoConvey库
- testify库
- 打桩与mock
- GoMock框架
- Gomonkey框架
- HTTP Mock
- httpMock
- mux库/httptest
- 数据库
- MYSQL
- SQL语言的分类
- 事务(重点)
- 索引
- 存储过程
- 触发器
- 视图
- 导入导出数据库
- 优化mysql数据库的方法
- MyISAM与InnoDB区别
- 外连接、内连接的区别
- 物理文件结构
- PostgreSQL
- 编译安装
- pgsql常用命令
- pgsql应用目录(bin目录)文件结构解析
- pg_ctl
- initdb
- psql
- clusterdb
- cluster命令
- createdb
- dropdb
- createuser
- dropuser
- pg_config
- pg_controldata
- pg_checksums
- pgbench
- pg_basebackup
- pg_dump
- pg_dumpall
- pg_isready
- pg_receivewal
- pg_recvlogical
- pg_resetwal
- pg_restore
- pg_rewind
- pg_test_fsync
- pg_test_timing
- pg_upgrade
- pg_verifybackup
- pg_archivecleanup
- pg_waldump
- postgres
- reindexdb
- vacuumdb
- ecpg
- pgsql数据目录文件结构解析
- pgsql数据目录文件结构解析
- postgresql.conf解析
- pgsql系统配置参数说明
- pgsql索引类型
- 四种索引类型解析
- 索引之ctid解析
- 索引相关操作
- pgsql函数解析
- pgsql系统函数解析
- pgsql窗口函数解析
- pgsql聚合函数解析
- pgsql系统表解析
- pg_stat_all_indexes
- pg_stat_all_tables
- pg_statio_all_indexes
- pg_statio_all_tables
- pg_stat_database
- pg_stat_statements
- pg_extension
- pg_available_extensions
- pg_available_extension_versions
- pgsql基本原理
- 进程和内存结构
- 存储结构
- 数据文件的内部结构
- 垃圾回收机制VACUUM
- 事务日志WAL
- 并发控制
- 介绍
- 事务ID-txid
- 元组结构-Tuple Structure
- 事务状态记录-Commit Log (clog)
- 事务快照-Transaction Snapshot
- 事务快照实例
- 事务隔离
- 事务隔离级别
- 读已提交-Read committed
- 可重复读-Repeatable read
- 可序列化-Serializable
- 读未提交-Read uncommitted
- 锁机制
- 扩展机制解析
- 扩展的定义
- 扩展的安装方式
- 自定义创建扩展
- 扩展的管理
- 扩展使用实例
- 在pgsql中使用last、first聚合函数
- pgsql模糊查询不走索引的解决方案
- pgsql的pg_trgm扩展解析与验证
- 高可用
- LNMP
- LNMP环境搭建
- 一键安装包
- 搭建方法
- 配置文件目录
- 服务器管理系统
- 宝塔(Linux)
- 安装与使用
- 开放API
- 自定义apache日志
- 一键安装包LNMP1.5
- LNMP1.5:添加、删除站点
- LNMP1.5:php多版本切换
- LNMP1.5 部署 thinkphp项目
- Operation not permitted解决方法
- Nginx
- Nginx的产生
- 正向代理和反向代理
- 负载均衡
- Linux常用命令
- 目录与文件相关命令
- 目录操作命令
- 文件编辑命令
- 文件查看命令
- 文件查找命令
- 文件权限命令
- 文件上传下载命令
- 用户和群组相关命令
- 用户与用户组的关系
- 用户相关的系统配置文件
- 用户相关命令
- 用户组相关命令
- 压缩与解压相关命令
- .zip格式
- .tar.gz格式
- .gz格式
- .bz2格式
- 查看系统版本
- cpuinfo详解
- meminfo详解
- getconf获取系统信息
- 磁盘空间相关命令
- 查看系统负载情况
- 系统环境变量
- 网络相关命令
- ip命令详解
- ip命令格式详解
- ip address命令详解
- ip link命令详解
- ip rule命令详解
- ip route命令详解
- nslookup命令详解
- traceroute命令详解
- netstat命令详解
- route命令详解
- tcpdump命令详解
- 系统进程相关命令
- ps命令详解
- pstree命令详解
- kill命令详解
- 守护进程-supervisord
- 性能监控相关命令
- top命令详解
- iostat命令详解
- pidstat命令详解
- iotop命令详解
- mpstat命令详解
- vmstat命令详解
- ifstat命令详解
- sar命令详解
- iftop命令详解
- 定时任务相关命令
- ssh登录远程主机
- ssh口令登录
- ssh公钥登录
- ssh带密码登录
- ssh端口映射
- ssh配置文件
- ssh安全设置
- 历史纪录
- history命令详解
- linux开启操作日志记录
- 拓展
- git
- git初始化本地仓库-https
- git初始化仓库-ssh
- git-查看和设置config配置
- docker
- 概念
- docker原理
- docker镜像原理
- docker Overlay2 文件系统原理
- docker日志原理
- docker日志驱动
- docker容器日志管理
- 原理论证
- 验证容器的启动是作为Docker Daemon的子进程
- 验证syslog类型日志驱动
- 验证journald类型日志驱动
- 验证local类型日志驱动
- 修改容器的hostname
- 修改容器的hosts
- 验证联合挂载技术
- 验证启动多个容器对于磁盘的占用情况
- 验证写时复制原理
- 验证docker内容寻址原理
- docker存储目录
- /var/lib/docker目录
- image目录
- overlay2目录
- 数据卷
- 具名挂载和匿名挂载
- 数据卷容器
- Dockerfile详解
- dockerfile指令详解
- 实例:构造centos
- 实例:CMD和ENTRYPOINT的区别
- docker网络详解
- docker-compose
- 缓存
- redis
- redis的数据类型和应用场景
- redis持久化
- RDB持久化
- AOF持久化
- redis缓存穿透、缓存击穿、缓存雪崩
- 常见网络攻击类型
- CSRF攻击
- XSS攻击
- SQL注入
- Cookie攻击
- 历史项目经验
- 图片上传项目实例
- 原生php上传方法实例
- base64图片流
- tp5的上传方法封装实例
- 多级关系的递归查询
- 数组转树结构
- thinkphp5.1+ajax实现导出Excel
- JS 删除数组的某一项
- 判断是否为索引数组
- ip操作