
文件及硬盘管理是计算机操作系统的重要组成部分,让微软走上成功之路的正是微软最早推出的个人电脑 PC 操作系统,这个操作系统就叫 DOS,即 Disk Operating System,硬盘操作系统。我们每天使用电脑都离不开硬盘,硬盘既有大小的限制,通常大一点的硬盘也不过几 T,又有速度限制,快一点的硬盘也不过每秒几百 M。
文件是存储在硬盘上的,文件的读写访问速度必然受到硬盘的物理限制,那么如何才能 1 分钟完成一个 100T 大文件的遍历呢?
想要知道这个问题的答案,我们就必须知道文件系统的原理。
做软件开发时,必然要经常和文件系统打交道,而文件系统也是一个软件,了解文件系统的设计原理,可以帮助我们更好地使用文件系统,另外设计文件系统时的各种考量,也对我们自己做软件设计有诸多借鉴意义。
让我们先从硬盘的物理结构说起。
## 硬盘
硬盘是一种可持久保存、多次读写数据的存储介质。硬盘的形式主要两种,一种是机械式硬盘,一种是固态硬盘。
机械式硬盘的结构,主要包含盘片、主轴、磁头臂,主轴带动盘片高速旋转,当需要读写盘上的数据的时候,磁头臂会移动磁头到盘片所在的磁道上,磁头读取磁道上的数据。读写数据需要移动磁头,这样一个机械的动作,至少需要花费数毫秒的时间,这是机械式硬盘访问延迟的主要原因。
如果一个文件的数据在硬盘上不是连续存储的,比如数据库的 B+ 树文件,那么要读取这个文件,磁头臂就必须来回移动,花费的时间必然很长。如果文件数据是连续存储的,比如日志文件,那么磁头臂就可以较少移动,相比离散存储的同样大小的文件,连续存储的文件的读写速度要快得多。
机械式硬盘的数据就存储在具有磁性特质的盘片上,因此这种硬盘也被称为磁盘,而固态硬盘则没有这种磁性特质的存储介质,也没有电机驱动的机械式结构。
其中主控芯片处理端口输入的指令和数据,然后控制闪存颗粒进行数据读写。由于固态硬盘没有了机械式硬盘的电机驱动磁头臂进行机械式物理移动的环节,而是完全的电子操作,因此固态硬盘的访问速度远快于机械式硬盘。
但是,到目前为止固态硬盘的成本还是明显高于机械式硬盘,因此在生产环境中,最主要的存储介质依然是机械式硬盘。如果一个场景对数据访问速度、存储容量、成本都有较高要求,那么可以采用固态硬盘和机械式硬盘混合部署的方式,即在一台服务器上既有固态硬盘,也有机械式硬盘,以满足不同文件类型的存储需求,比如日志文件存储在机械式硬盘上,而系统文件和随机读写的文件存储在固态硬盘上。
## 文件系统
作为应用程序开发者,我们不需要直接操作硬盘,而是通过操作系统,以文件的方式对硬盘上的数据进行读写访问。文件系统将硬盘空间以块为单位进行划分,每个文件占据若干个块,然后再通过一个文件控制块 FCB 记录每个文件占据的硬盘数据块。
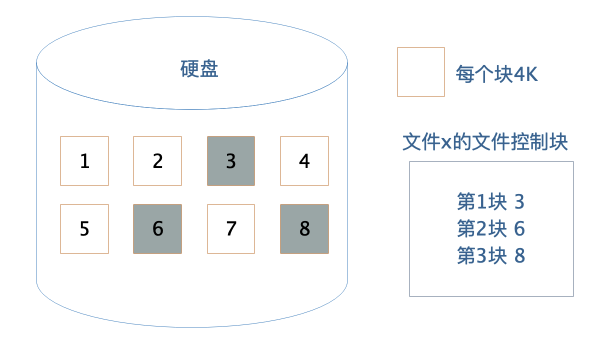
这个文件控制块在 Linux 操作系统中就是 inode,要想访问文件,就必须获得文件的 inode 信息,在 inode 中查找文件数据块索引表,根据索引中记录的硬盘地址信息访问硬盘,读写数据。
inode 中记录着文件权限、所有者、修改时间和文件大小等文件属性信息,以及文件数据块硬盘地址索引。inode 是固定结构的,能够记录的硬盘地址索引数也是固定的,只有 15 个索引。其中前 12 个索引直接记录数据块地址,第 13 个索引记录索引地址,也就是说,索引块指向的硬盘数据块并不直接记录文件数据,而是记录文件数据块的索引表,每个索引表可以记录 256 个索引;第 14 个索引记录二级索引地址,第 15 个索引记录三级索引地址,如下图:
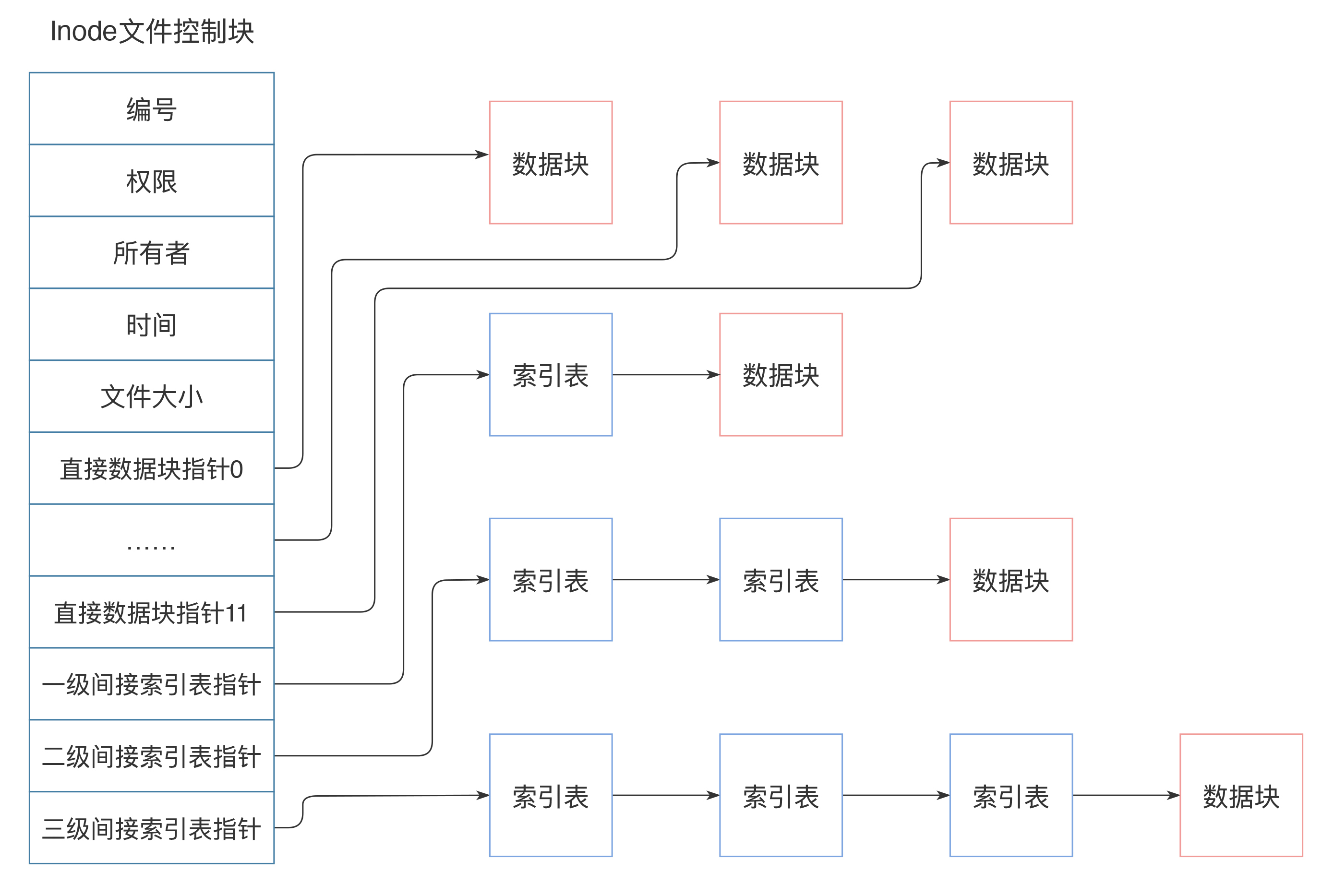
这样,每个 inode 最多可以存储 12+256+256\*256+256\*256\*256 个数据块,如果每个数据块的大小为 4k,也就是单个文件最大不超过 70G,而且即使可以扩大数据块大小,文件大小也要受单个硬盘容量的限制。这样的话,对于我们开头提出的一分钟完成 100T 大文件的遍历,Linux 文件系统是无法完成的。
那么,有没有更给力的解决方案呢?
## RAID
RAID,即独立硬盘冗余阵列,将多块硬盘通过硬件 RAID 卡或者软件 RAID 的方案管理起来,使其共同对外提供服务。RAID 的核心思路其实是利用文件系统将数据写入硬盘中不同数据块的特性,将多块硬盘上的空闲空间看做一个整体,进行数据写入,也就是说,一个文件的多个数据块可能写入多个硬盘。
根据硬盘组织和使用方式不同,常用 RAID 有五种,分别是 RAID 0、RAID 1、RAID 10、RAID 5 和 RAID 6。

RAID 0 将一个文件的数据分成 N 片,同时向 N 个硬盘写入,这样单个文件可以存储在 N 个硬盘上,文件容量可以扩大 N 倍,(理论上)读写速度也可以扩大 N 倍。但是使用 RAID 0 的最大问题是文件数据分散在 N 块硬盘上,任何一块硬盘损坏,就会导致数据不完整,整个文件系统全部损坏,文件的可用性极大地降低了。
RAID 1 则是利用两块硬盘进行数据备份,文件同时向两块硬盘写入,这样任何一块硬盘损坏都不会出现文件数据丢失的情况,文件的可用性得到提升。
RAID 10 结合 RAID 0 和 RAID 1,将多块硬盘进行两两分组,文件数据分成 N 片,每个分组写入一片,每个分组内的两块硬盘再进行数据备份。这样既扩大了文件的容量,又提高了文件的可用性。但是这种方式硬盘的利用率只有 50%,有一半的硬盘被用来做数据备份。
RAID 5 针对 RAID 10 硬盘浪费的情况,将数据分成 N-1 片,再利用这 N-1 片数据进行位运算,计算一片校验数据,然后将这 N 片数据写入 N 个硬盘。这样任何一块硬盘损坏,都可以利用校验片的数据和其他数据进行计算得到这片丢失的数据,而硬盘的利用率也提高到 N-1/N。
RAID 5 可以解决一块硬盘损坏后文件不可用的问题,那么如果两块文件损坏?RAID 6 的解决方案是,用两种位运算校验算法计算两片校验数据,这样两块硬盘损坏还是可以计算得到丢失的数据片。
实践中,使用最多的是 RAID 5,数据被分成 N-1 片并发写入 N-1 块硬盘,这样既可以得到较好的硬盘利用率,也能得到很好的读写速度,同时还能保证较好的数据可用性。使用 RAID 5 的文件系统比简单的文件系统文件容量和读写速度都提高了 N-1 倍,但是一台服务器上能插入的硬盘数量是有限的,通常是 8 块,也就是文件读写速度和存储容量提高了 7 倍,这远远达不到 1 分钟完成 100T 文件的遍历要求。
那么,有没有更给力的解决方案呢?
## 分布式文件系统
我们再回过头看下 Linux 的文件系统:文件的基本信息,也就是文件元信息记录在文件控制块 inode 中,文件的数据记录在硬盘的数据块中,inode 通过索引记录数据块的地址,读写文件的时候,查询 inode 中的索引记录得到数据块的硬盘地址,然后访问数据。
如果将数据块的地址改成分布式服务器的地址呢?也就是查询得到的数据块地址不只是本机的硬盘地址,还可以是其他服务器的地址,那么文件的存储容量就将是整个分布式服务器集群的硬盘容量,这样还可以在不同的服务器上同时并行读取文件的数据块,文件访问速度也将极大的加快。
这样的文件系统就是分布式文件系统,分布式文件系统的思路其实和 RAID 是一脉相承的,就是将数据分成很多片,同时向 N 台服务器上进行数据写入。针对一片数据丢失就导致整个文件损坏的情况,分布式文件系统也是采用数据备份的方式,将多个备份数据片写入多个服务器,以保证文件的可用性。当然,也可以采用 RAID 5 的方式通过计算校验数据片的方式提高文件可用性。
我们以 Hadoop 分布式文件系统 HDFS 为例,看下分布式文件系统的具体架构设计。
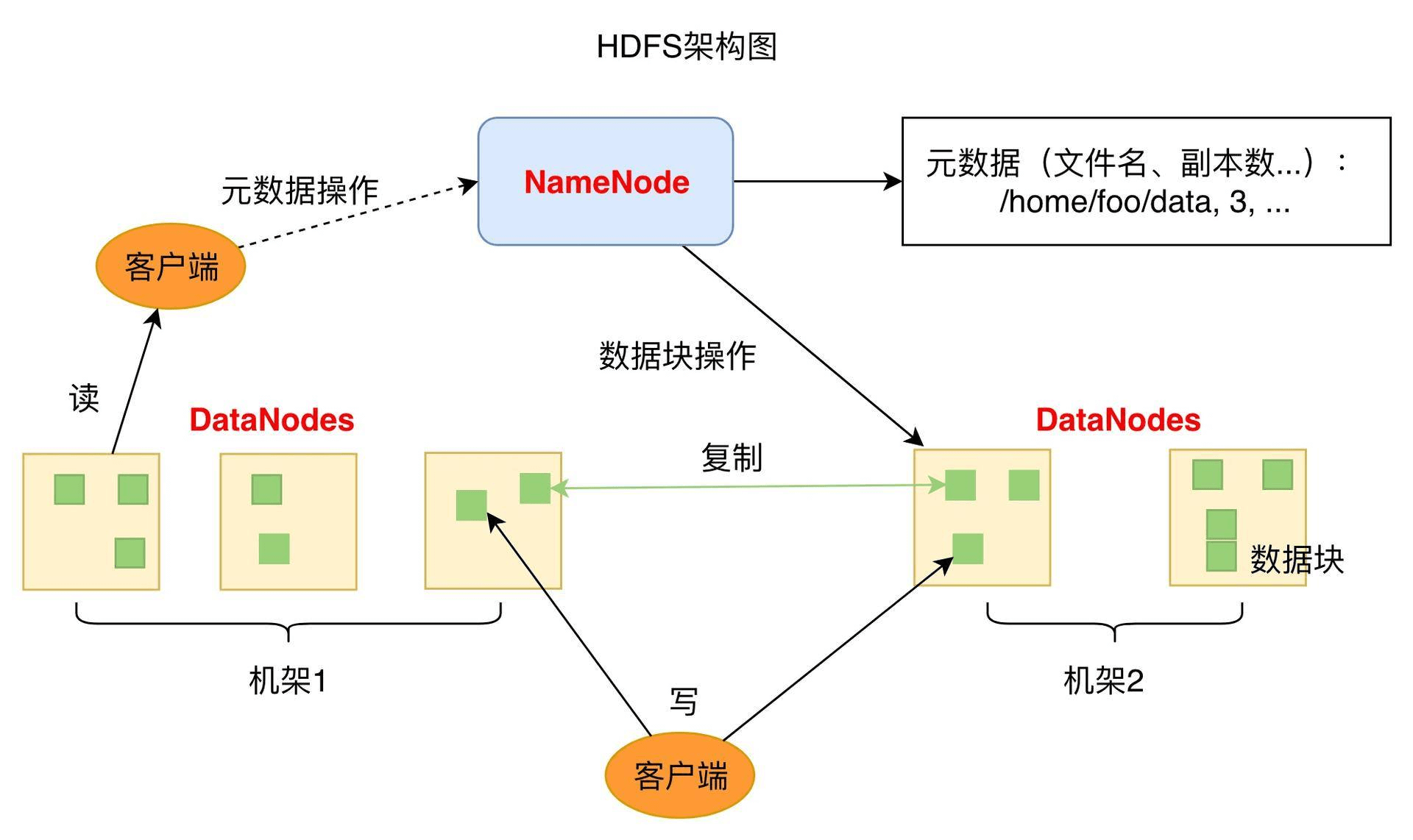
HDFS 的关键组件有两个,一个是 DataNode,一个是 NameNode。
DataNode 负责文件数据的存储和读写操作,HDFS 将文件数据分割成若干数据块(Block),每个 DataNode 存储一部分数据块,这样文件就分布存储在整个 HDFS 服务器集群中。应用程序客户端(Client)可以并行对这些数据块进行访问,从而使得 HDFS 可以在服务器集群规模上实现数据并行访问,极大地提高了访问速度。在实践中,HDFS 集群的 DataNode 服务器会有很多台,一般在几百台到几千台这样的规模,每台服务器配有数块硬盘,整个集群的存储容量大概在几 PB 到数百 PB。
NameNode 负责整个分布式文件系统的元数据(MetaData)管理,也就是文件路径名、访问权限、数据块的 ID 以及存储位置等信息,相当于 Linux 系统中 inode 的角色。HDFS 为了保证数据的高可用,会将一个数据块复制为多份(缺省情况为 3 份),并将多份相同的数据块存储在不同的服务器上,甚至不同的机架上。这样当有硬盘损坏,或者某个 DataNode 服务器宕机,甚至某个交换机宕机,导致其存储的数据块不能访问的时候,客户端会查找其备份的数据块进行访问。
有了 HDFS,可以实现单一文件存储几百 T 的数据,再配合大数据计算框架 MapReduce 或者 Spark,可以对这个文件的数据块进行并发计算。也可以使用 Impala 这样的 SQL 引擎对这个文件进行结构化查询,在数千台服务器上并发遍历 100T 的数据,1 分钟都是绰绰有余的。
## 小结
文件系统从简单操作系统文件,到 RAID,再到分布式文件系统,其设计思路其实是具有统一性的。这种统一性一方面体现在文件数据如何管理,也就是如何通过文件控制块管理文件的数据,这个文件控制块在 Linux 系统中就是 inode,在 HDFS 中就是 NameNode。
另一方面体现在如何利用更多的硬盘实现越来越大的文件存储需求和越来越快的读写速度需求,也就是将数据分片后同时写入多块硬盘。单服务器我们可以通过 RAID 来实现,多服务器则可以将这些服务器组成一个文件系统集群,共同对外提供文件服务,这时候,数千台服务器的数万块硬盘以单一存储资源的方式对文件使用者提供服务,也就是一个文件可以存储数百 T 的数据,并在一分钟完成这样一个大文件的遍历
- 技能知识点
- 对死锁问题的理解
- 文件系统原理:如何用1分钟遍历一个100TB的文件?
- 数据库原理:为什么PrepareStatement性能更好更安全?
- Java Web程序的运行时环境到底是怎样的?
- 你真的知道自己要解决的问题是什么吗?
- 如何解决问题
- 经验分享
- GIT的HTTP方式免密pull、push
- 使用xhprof对php7程序进行性能分析
- 微信扫码登录和使用公众号方式进行扫码登录
- 关于curl跳转抓取
- Linux 下配置 Git 操作免登录 ssh 公钥
- Linux Memcached 安装
- php7安装3.4版本的phalcon扩展
- centos7下php7.0.x安装phalcon框架
- 将字符串按照指定长度分割
- 搜索html源码中标签包的纯文本
- 更换composer镜像源为阿里云
- mac 隐藏文件显示/隐藏
- 谷歌(google)世界各国网址大全
- 实战文档
- PHP7安装intl扩展和linux安装icu
- linux编译安装时常见错误解决办法
- linux删除文件后不释放磁盘空间解决方法
- PHP开启异步多线程执行脚本
- file_exists(): open_basedir restriction in effect. File完美解决方案
- PHP 7.1 安装 ssh2 扩展,用于PHP进行ssh连接
- php命令行加载的php.ini
- linux文件实时同步
- linux下php的psr.so扩展源码安装
- php将字符串中的\n变成真正的换行符?
- PHP7 下安装 memcache 和 memcached 扩展
- PHP 高级面试题 - 如果没有 mb 系列函数,如何切割多字节字符串
- PHP设置脚本最大执行时间的三种方法
- 升级Php 7.4带来的两个大坑
- 不同域名的iframe下,fckeditor在chrome下的SecurityError,解决办法~~
- Linux find+rm -rf 执行组合删除
- 从零搭建Prometheus监控报警系统
- Bug之group_concat默认长度限制
- PHP生成的XML显示无效的Char值27消息(PHP generated XML shows invalid Char value 27 message)
- XML 解析中,如何排除控制字符
- PHP各种时间获取
- nginx配置移动自适应跳转
- 已安装nginx动态添加模块
- auto_prepend_file与auto_append_file使用方法
- 利用nginx实现web页面插入统计代码
- Nginx中的rewrite指令(break,last,redirect,permanent)
- nginx 中 index try_files location 这三个配置项的作用
- linux安装git服务器
- PHP 中运用 elasticsearch
- PHP解析Mysql Binlog
- 好用的PHP学习网(持续更新中)
- 一篇写给准备升级PHP7的小伙伴的文章
- linux 安装php7 -系统centos7
- Linux 下多php 版本共存安装
- PHP编译安装时常见错误解决办法,php编译常见错误
- nginx upstream模块--负载均衡
- 如何解决Tomcat服务器打开不了HOST Manager的问题
- PHP的内存泄露问题与垃圾回收
- Redis数据结构 - string字符串
- PHP开发api接口安全验证
- 服务接口API限流 Rate Limit
- php内核分析---内存管理(一)
- PHP内存泄漏问题解析
- 【代码片-1】 MongoDB与PHP -- 高级查询
- 【代码片-1】 php7 mongoDB 简单封装
- php与mysql系统中出现大量数据库sleep的空连接问题分析
- 解决crond引发大量sendmail、postdrop进程问题
- PHP操作MongoDB GridFS 存储文件,如图片文件
- 浅谈php安全
- linux上keepalived+nginx实现高可用web负载均衡
- 整理php防注入和XSS攻击通用过滤