
# ClickHouse集群部署
防止一些意外的情况
1、取消打开文件数限制
在/etc/security/limits.conf、/etc/security/limits.d/20-nproc.conf这2个文件的末尾加入一下
文件末尾加:
```
* soft nofile 65536
* hard nofile 65536
* soft nproc 131072
* hard nproc 131072
```
2、取消SELINUX
修改/etc/selinux/config 中 SELINUX=disabled
3、关闭防火墙
service iptables stop
4、安装依赖
```
yum install -y libtool
yum install -y *unixODBC
```
5、安装三台单机clickhouse
略
6、配置metrika.xml文件
在/etc/clickhouse-server/config.d文件夹下添加一个名为metrika.xml的配置文件
```XML
<yandex>
<clickhouse_remote_servers>
<!--集群名称,clickhouse支持多集群的模式-->
<clickhouse_cluster>
<!--定义分片节点,这里我指定3个分片,每个分片只有1个副本,也就是它本身-->
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>server1</host>
<port>9000</port>
</replica>
</shard>
<shard>
<replica>
<internal_replication>true</internal_replication>
<host>server2</host>
<port>9000</port>
</replica>
</shard>
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>server3</host>
<port>9000</port>
</replica>
</shard>
</clickhouse_cluster>
</clickhouse_remote_servers>
<!--zookeeper集群的连接信息-->
<zookeeper-servers>
<node index="1">
<host>server1</host>
<port>2181</port>
</node>
<node index="2">
<host>server1</host>
<port>2182</port>
</node>
<node index="3">
<host>server1</host>
<port>2183</port>
</node>
</zookeeper-servers>
<!--定义宏变量,后面需要用-->
<macros>
<replica>server1</replica>
</macros>
<!--不限制访问来源ip地址-->
<networks>
<ip>::/0</ip>
</networks>
<!--数据压缩方式,默认为lz4-->
<clickhouse_compression>
<case>
<min_part_size>10000000000</min_part_size>
<min_part_size_ratio>0.01</min_part_size_ratio>
<method>lz4</method>
</case>
</clickhouse_compression>
</yandex>
```
<p style="color:red">注意配置中变量macros为对应主机名不能一样</p>
7、修改三台机器的config.xml的配置
vi /etc/clickhouse-server/config.xml
取消注释<listen_host>::</listen_host>
```
<!--引入metrika.xml-->
<include_from>/etc/clickhouse-server/config.d/metrika.xml</include_from>
#引用Zookeeper配置的定义
<zookeeper incl="zookeeper-servers" optional="true" />
```
8、启动集群
1)启动Zookeeper集群
```
zkServer.sh start zk1.cfg
zkServer.sh start zk2.cfg
zkServer.sh start zk3.cfg
```
2)启动ClickHouse
分别启动ClickHouse
```
sudo clickhouse start
```
9、验证集群
select * from system.clusters
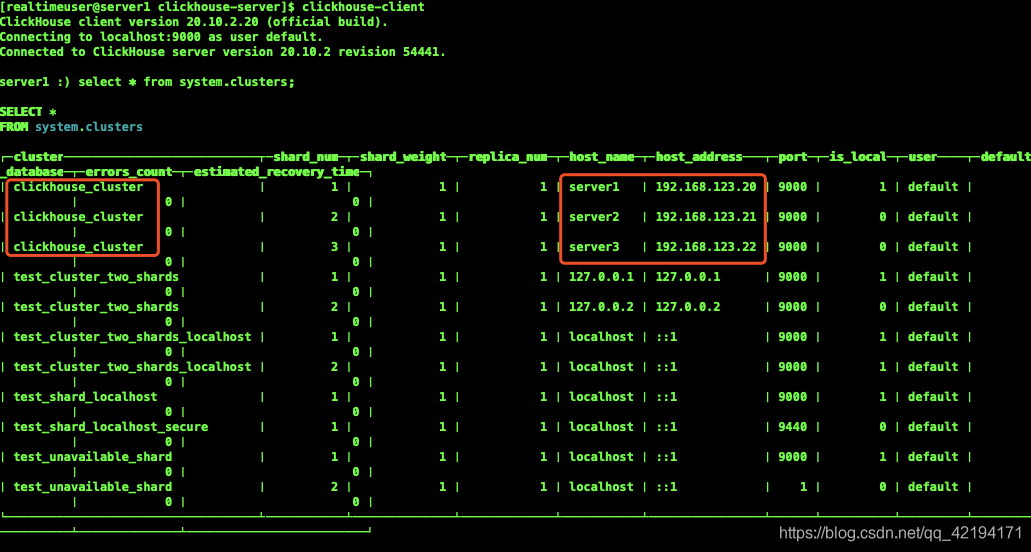
10、使用ClickHouse访问Zookeeper
在ClickHouse系统表中,提供了一张Zookeeper代理表,我们可以使用SQL轻松访问Zookeeper内的数据,不用再像以前一样使用客户端登录进去查看。
```
-- 查询Zookeeper根目录
select * from system.zookeeper where path = '/'
-- 查询ClickHouse目录
select * from system.zookeeper where path = '/clickhouse'
```
文档参考:https://blog.csdn.net/qq_42194171/article/details/109560651
- ClickHouse
- 第一节 ClickHouse入门
- 1.1ClickHouse概述
- 1.2ClickHouse单机安装
- 1.3ClickHouse配置
- 1.4ClickHouse数据库引擎
- 1.5ClickHouse集群部署
- 第二节 ClickHouse进阶
- 2.1ClicKHouse数据类型
- 2.2ClicKHouse基本语法
- 2.3ClickHouse引擎
- 2.4ClickHouse函数
- 2.5ClickHouse分布式表
- 2.6ClickHouse权限和密码加密
- 2.7ClickHouse数据导入和导出
- 第三节 ClicKHouse实战篇
- 3.1ClickHouse的JDBC连接
- 3.2ClickHouse用户行为分析
- 3.3ClickHouse实战
- 第四节 ClicKHouse常见问题
- 4.1ClickHouse常见问题汇总
- 第五节 ClickHouse其他
- 5.1ClickHouse可视化工具
- 5.2ClickHouse学习教程