
# 概述
在解决分布式系统中负载均衡的问题时候可以使用Hash算法让固定的一部分请求落到同一台服务器上,这样每台服务器固定处理一部分请求,起到负载均衡的作用。
但是普通的余数hash(hash\(比如用户id\)%服务器机器数)算法伸缩性很差,当新增或者下线服务器机器时候,用户id与服务器的映射关系会大量失效。一致性hash则利用hash环对其进行了改进
### 一致性哈希算法特性
一致性哈希算法在1997年由麻省理工学院提出的一种分布式哈希(DHT)实现算法,设计目标是为了解决因特网中的热点\(Hot spot\)问题,初衷和CARP十分类似。一致性哈希修正了CARP使用的简单哈希算法带来的问题,使得分布式哈希(DHT)可以在P2P环境中真正得到应用。
一致性hash算法提出了在动态变化的Cache环境中,判定哈希算法好坏的四个定义:
1. 平衡性\(Balance\):平衡性是指哈希的结果能够尽可能分布到所有的缓冲中去,这样可以使得所有的缓冲空间都得到利用。很多哈希算法都能够满足这一条件。
2. 单调性\(Monotonicity\):单调性是指如果已经有一些内容通过哈希分派到了相应的缓冲中,又有新的缓冲加入到系统中。哈希的结果应能够保证原有已分配的内容可以被映射到原有的或者新的缓冲中去,而不会被映射到旧的缓冲集合中的其他缓冲区。
3. 分散性\(Spread\):在分布式环境中,终端有可能看不到所有的缓冲,而是只能看到其中的一部分。当终端希望通过哈希过程将内容映射到缓冲上时,由于不同终端所见的缓冲范围有可能不同,从而导致哈希的结果不一致,最终的结果是相同的内容被不同的终端映射到不同的缓冲区中。这种情况显然是应该避免的,因为它导致相同内容被存储到不同缓冲中去,降低了系统存储的效率。分散性的定义就是上述情况发生的严重程度。好的哈希算法应能够尽量避免不一致的情况发生,也就是尽量降低分散性。
4. 负载\(Load\):负载问题实际上是从另一个角度看待分散性问题。既然不同的终端可能将相同的内容映射到不同的缓冲区中,那么对于一个特定的缓冲区而言,也可能被不同的用户映射为不同的内容。与分散性一样,这种情况也是应当避免的,因此好的哈希算法应能够尽量降低缓冲的负荷
# 一致性Hash概述
为了能直观的理解一致性hash原理,这里结合一个简单的例子来讲解,假设有4台服务器,地址为ip1,ip2,ip3,ip4。
* 一致性hash是首先计算四个ip地址对应的hash值
hash\(ip1\),hash\(ip2\),hash\(ip3\),hash\(ip3\),计算出来的hash值是0~最大正整数直接的一个值,这四个值在一致性hash环上呈现如下图:
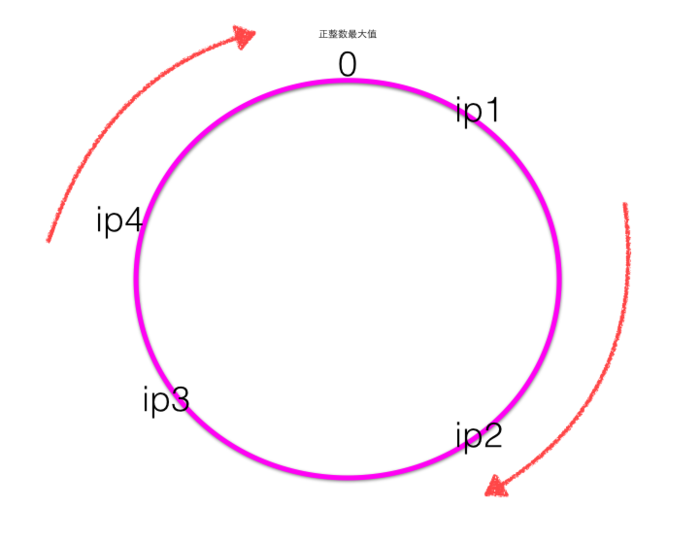
* hash环上顺时针从整数0开始,一直到最大正整数,我们根据四个ip计算的hash值肯定会落到这个hash环上的某一个点,至此我们把服务器的四个ip映射到了一致性hash环
* 当用户在客户端进行请求时候,首先根据hash\(用户id\)计算路由规则(hash值),然后看hash值落到了hash环的那个地方,根据hash值在hash环上的位置顺时针找距离最近的ip作为路由ip
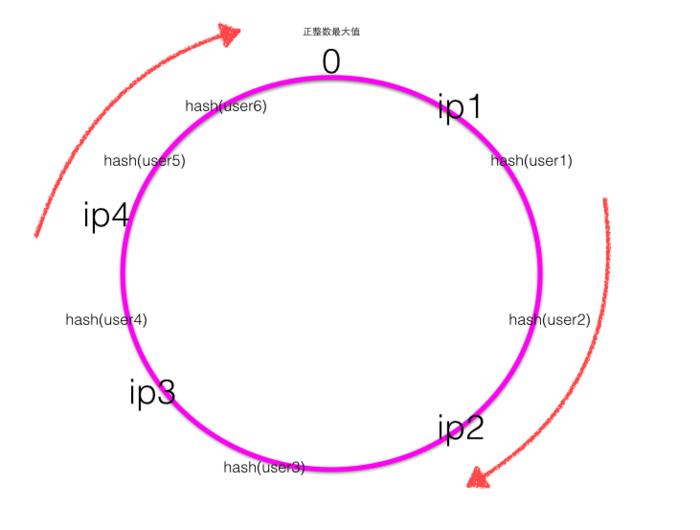
如上图可知user1,user2的请求会落到服务器ip2进行处理,User3的请求会落到服务器ip3进行处理,user4的请求会落到服务器ip4进行处理,user5,user6的请求会落到服务器ip1进行处理。
下面考虑当ip2的服务器挂了的时候会出现什么情况?
当ip2的服务器挂了的时候,一致性hash环大致如下图:
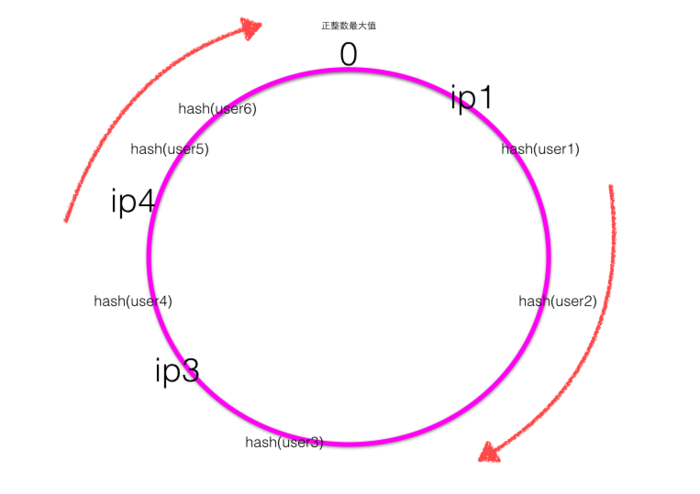
根据顺时针规则可知user1,user2的请求会被服务器ip3进行处理,而其它用户的请求对应的处理服务器不变,也就是只有之前被ip2处理的一部分用户的映射关系被破坏了,并且其负责处理的请求被顺时针下一个节点委托处理。
下面考虑当新增机器的时候会出现什么情况?
当新增一个ip5的服务器后,一致性hash环大致如下图:
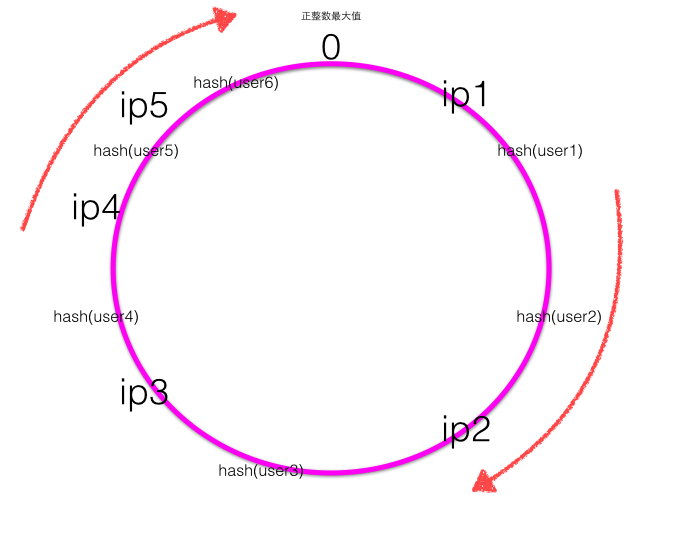
根据顺时针规则可知之前user1的请求应该被ip1服务器处理,现在被新增的ip5服务器处理,其他用户的请求处理服务器不变,也就是新增的服务器顺时针最近的服务器的一部分请求会被新增的服务器所替代
# 虚拟节点
当服务器节点比较少的时候会出现上节所说的一致性hash倾斜的问题,一个解决方法是多加机器,但是加机器是有成本的,那么就加虚拟节点,比如上面三个机器,每个机器引入1个虚拟节点后的一致性hash环的图如下:
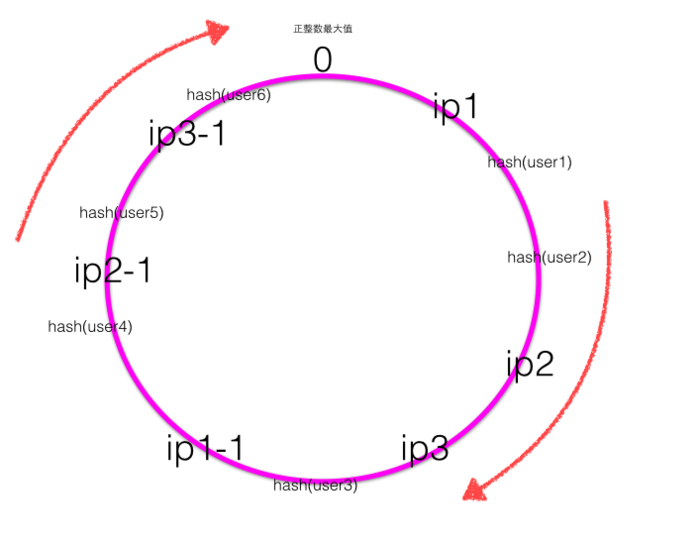
其中ip1-1是ip1的虚拟节点,ip2-1是ip2的虚拟节点,ip3-1是ip3的虚拟节点。
可知当物理机器数目为M,虚拟节点为N的时候,实际hash环上节点个数为M\*N。比如当客户端计算的hash值处于ip2和ip3或者处于ip2-1和ip3-1之间时候使用ip3服务器进行处理
# 均匀一致性hash
上节我们使用虚拟节点后的图看起来比较均衡,但是如果生成虚拟节点的算法不够好很可能会得到下面的环
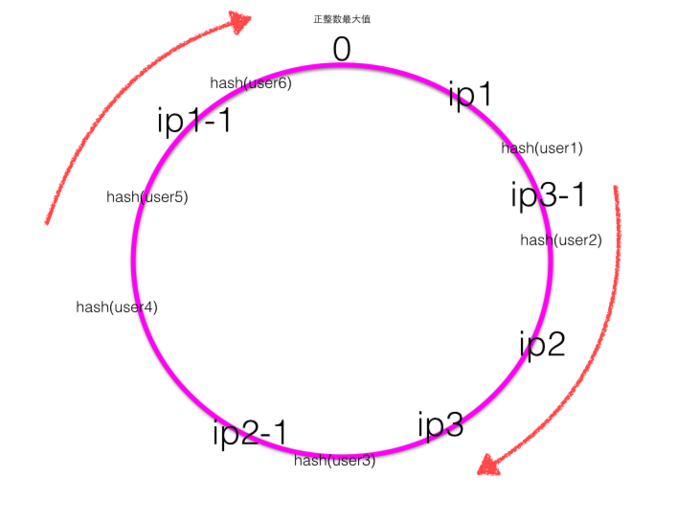
可知每个服务节点引入1个虚拟节点后,情况相比没有引入前均衡性有所改善,但是并不均衡。
均衡的一致性hash应该是如下图:
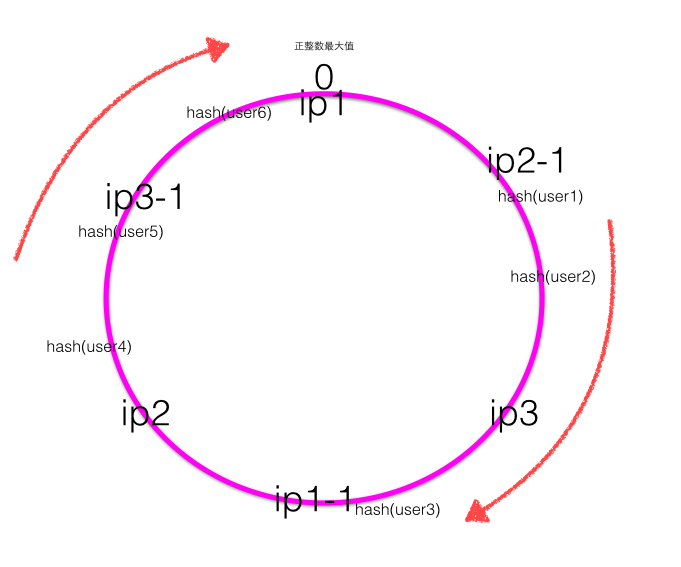
均匀一致性hash的目标是如果服务器有N台,客户端的hash值有M个,那么每个服务器应该处理大概M/N个用户的。也就是每台服务器负载尽量均衡
实际应用中,通常将虚拟节点数设置为32甚至更大,因此即使很少的节点也能做到相对均匀的数据分布
【参考资料】
《大型网站技术架构:核心原理与案例分析》6.3.3章节
- 基础
- 数据
- 数据元素
- 数据结构
- 集合结构
- 线性结构
- 树型结构
- 图状结构
- 数据存储结构
- 算法定义
- 算法效率度量
- 算法效率分析
- 时间复杂度
- O(1)
- O(n)
- O(n2)
- O(logn)
- 空间复杂度
- 线性表
- 数组
- 链表
- 串矩阵和广义表
- 串
- 矩阵
- 广义表
- 栈和队列
- 栈
- 队列
- 树和二叉树
- 二叉树
- 满二叉树
- 完全二叉树
- 哈夫曼树
- 二叉查找树-BST树
- AVL树
- 红黑树
- B树
- B+树
- 字典树
- 跳表
- 算法
- 排序算法
- 冒泡排序
- 选择排序
- 快速排序
- 插入排序
- 希尔排序
- 归并排序
- 堆排序
- 基数排序
- 计数排序
- 桶排序
- 查找算法
- 二分查找算法
- Hash算法
- 一致性hash算法
- 算法题
- 001-用两个栈实现队列
- 002-只使用栈和递归逆序一个栈
- 附录
- SkipList跳表