
[TOC]
## Redis 为什么这么快?
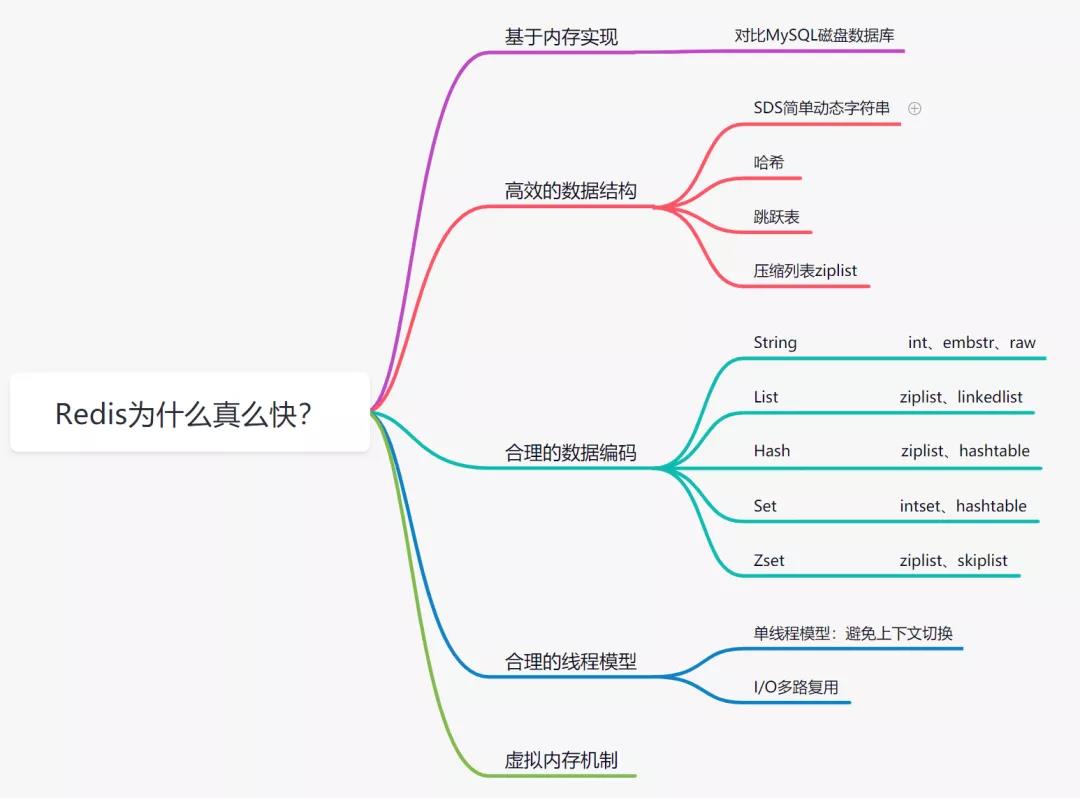
1、完全基于内存,绝大部分请求是纯粹的内存操作,非常快速。数据存在内存中,类似于 HashMap,HashMap 的优势就是查找和操作的时间复杂度都是O(1);
2、数据结构简单,对数据操作也简单,Redis 中的数据结构是专门进行设计的;
3、采用单线程,避免了不必要的上下文切换和竞争条件,也不存在多进程或者多线程导致的切换而消耗 CPU,不用去考虑各种锁的问题,不存在加锁释放锁操作,没有因为可能出现死锁而导致的性能消耗;
4、使用多路 I/O 复用模型,非阻塞 IO。
## 单线程有什么好处?
1. 不会因为线程创建导致的性能消耗;
2. 避免上下文切换引起的 CPU 消耗,没有多线程切换的开销;
3. 避免了线程之间的竞争问题,比如添加锁、释放锁、死锁等,不需要考虑各种锁问题。
4. 代码更清晰,处理逻辑简单。
## redis hash 字典
Redis 整体就是一个 哈希表来保存所有的键值对,无论数据类型是 5 种的任意一种。哈希表,本质就是一个数组,每个元素被叫做哈希桶,不管什么数据类型,每个桶里面的 entry 保存着实际具体值的指针。
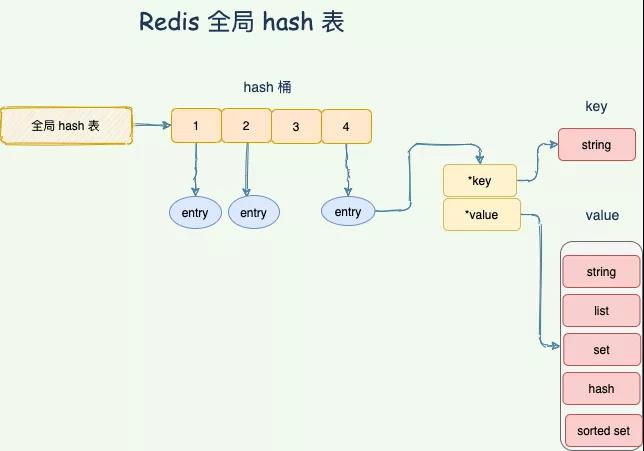
Redis 全局哈希表 **rehash**
整个数据库就是一个全局哈希表,而哈希表的时间复杂度是 O(1),只需要计算每个键的哈希值,便知道对应的哈希桶位置,定位桶里面的 entry 找到对应数据,这个也是 Redis 快的原因之一。
那 Hash 冲突怎么办?
当写入 Redis 的数据越来越多的时候,哈希冲突不可避免,会出现不同的 key 计算出一样的哈希值。
Redis 通过链式哈希解决冲突:也就是同一个 桶里面的元素使用链表保存。但是当链表过长就会导致查找性能变差可能,所以 Redis 为了追求快,使用了两个全局哈希表。用于 rehash 操作,增加现有的哈希桶数量,减少哈希冲突。
开始默认使用 hash 表 1 保存键值对数据,哈希表 2 此刻没有分配空间。当数据越来多触发 rehash 操作,则执行以下操作:
1. 给 hash 表 2 分配更大的空间;
2. 将 hash 表 1 的数据重新映射拷贝到 hash 表 2 中;
3. 释放 hash 表 1 的空间。
值得注意的是,将 hash 表 1 的数据重新映射到 hash 表 2 的过程中并不是一次性的,这样会造成 Redis 阻塞,无法提供服务。
而是采用了渐进式 rehash,每次处理客户端请求的时候,先从 hash 表 1 中第一个索引开始,将这个位置的 所有数据拷贝到 hash 表 2 中,就这样将 rehash 分散到多次请求过程中,避免耗时阻塞。
## 知识补充
https://mp.weixin.qq.com/s/z4VjDaDDbspFz1rIBwazIA
- 消息队列
- 为什么要用消息队列
- 各种消息队列产品的对比
- 消息队列的优缺点
- 如何保证消息队列的高可用
- 如何保证消息不丢失
- 如何保证消息不会重复消费?如何保证消息的幂等性?
- 如何保证消息消费的顺序性?
- 基于MQ的分布式事务实现
- Beanstalk
- PHP
- 函数
- 基础
- 基础函数题
- OOP思想及原则
- MVC生命周期
- PHP7.X新特性
- PHP8新特性
- PHP垃圾回收机制
- php-fpm相关
- 高级
- 设计模式
- 排序算法
- 正则
- OOP代码基础
- PHP运行原理
- zavl
- 网络协议new
- 一面
- TCP和UDP
- 常见状态码和代表的意义以及解决方式
- 网络分层和各层有啥协议
- TCP
- http
- 二面
- TCP2
- DNS
- Mysql
- 锁
- 索引
- 事务
- 高可用?高并发?集群?
- 其他
- 主从复制
- 主从复制数据延迟
- SQL的语⾔分类
- mysqlQuestions
- Redis
- redis-question
- redis为什么那么快
- redis的优缺点
- redis的数据类型和使用场景
- redis的数据持久化
- 过期策略和淘汰机制
- 缓存穿透、缓存击穿、缓存雪崩
- redis的事务
- redis的主从复制
- redis集群架构的理解
- redis的事件模型
- redis的数据类型、编码、数据结构
- Redis连接时的connect与pconnect的区别是什么?
- redis的分布式锁
- 缓存一致性问题
- redis变慢的原因
- 集群情况下,节点较少时数据分布不均匀怎么办?
- redis 和 memcached 的区别?
- 基本算法
- MysqlNew
- 索引new
- 事务new
- 锁new
- 日志new
- 主从复制new
- 树结构
- mysql其他问题
- 删除
- 主从配置
- 五种IO模型
- Kafka
- Nginx
- trait
- genergtor 生成器
- 如何实现手机扫码登录功能
- laravel框架的生命周期