
[TOC]
https://mp.weixin.qq.com/s/bb7C6VNbq7REP9u8PsreSg
应用程序的IO操作分为两种动作:**IO调用和IO执行**。IO调用是由进程(应用程序的运行态)发起,而IO执行是**操作系统内核**的工作。
## 操作系统的一次IO过程
应用程序发起的一次IO操作包含两个阶段:
* IO调用:应用程序进程向操作系统**内核**发起调用。
* IO执行:操作系统内核完成IO操作。
操作系统内核完成IO操作还包括两个过程:
* 准备数据阶段:内核等待I/O设备准备好数据
* 拷贝数据阶段:将数据从内核缓冲区拷贝到用户进程缓冲区
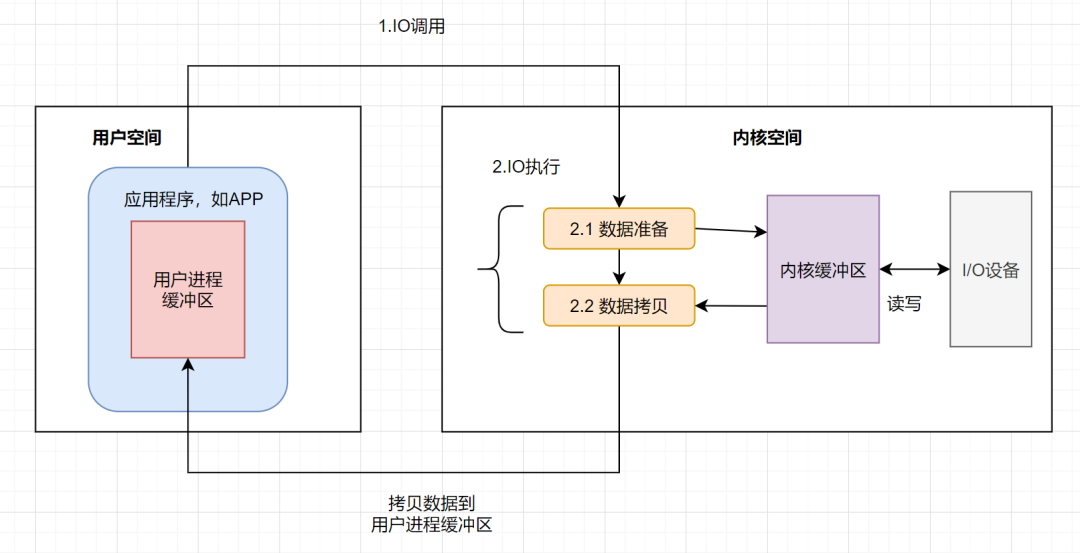
其实IO就是把进程的内部数据转移到外部设备,或者把外部设备的数据迁移到进程内部。外部设备一般指硬盘、socket通讯的网卡。一个完整的**IO过程**包括以下几个步骤:
* 应用程序进程向操作系统发起**IO调用请求**
* 操作系统**准备数据**,把IO外部设备的数据,加载到**内核缓冲区**
* 操作系统拷贝数据,即将内核缓冲区的数据,拷贝到用户进程缓冲区
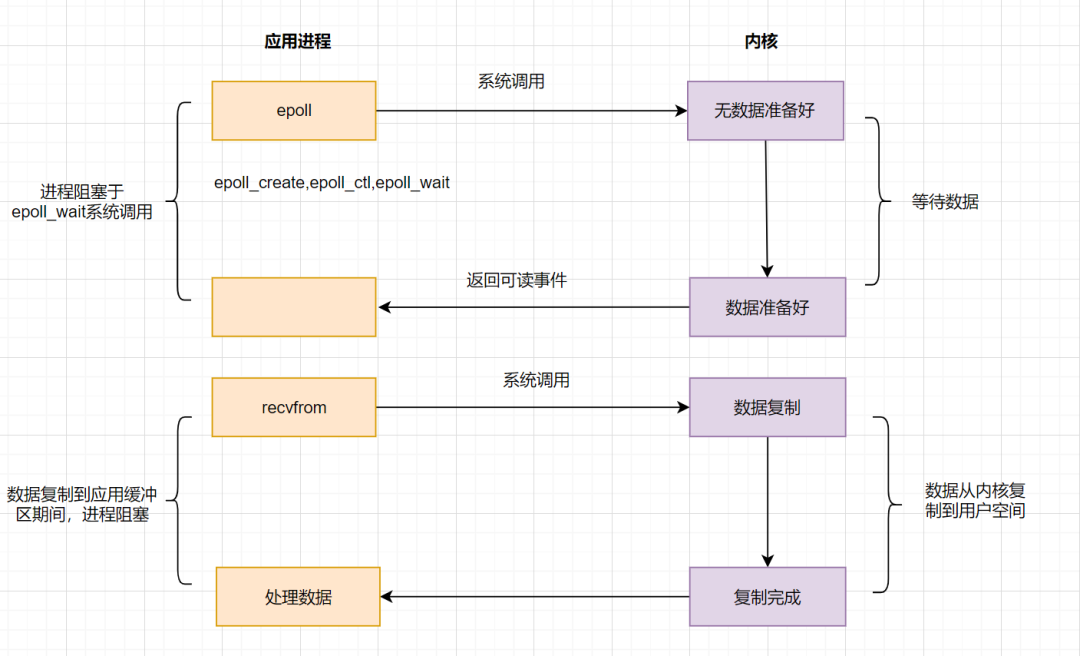
## 阻塞IO模型
阻塞IO:应用程序的进程发起**IO调用**,但**内核的数据还没准备好**,应用程序进程就一直在**阻塞等待**,一直等到内核数据准备好了,从内核拷贝到用户空间,才返回成功提示
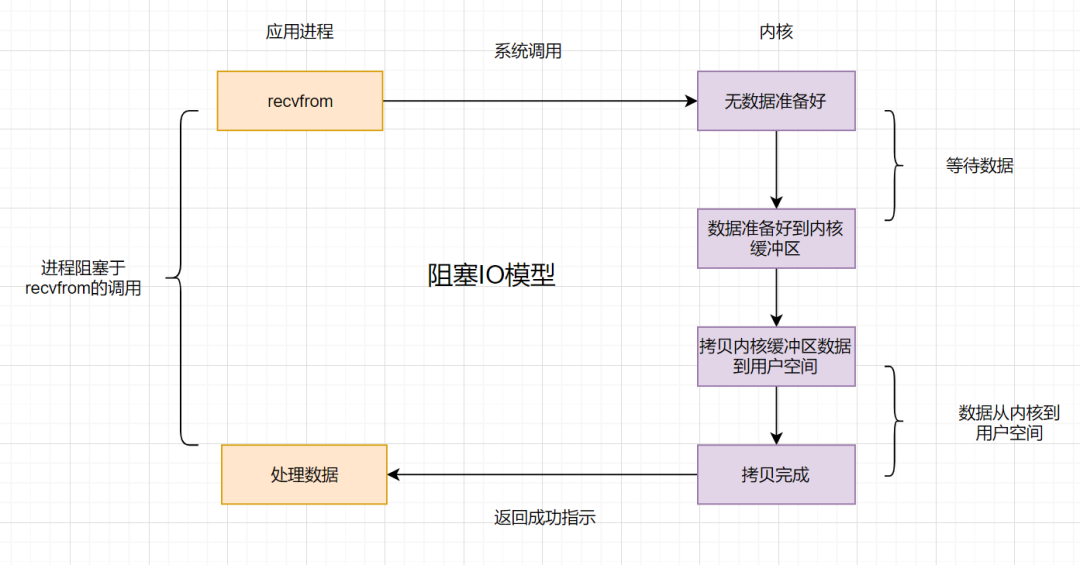
* 阻塞IO比较经典的应用就是**阻塞socket、Java BIO**。
* 阻塞IO的缺点就是:如果内核数据一直没准备好,那用户进程将一直阻塞,**浪费性能**,可以使用**非阻塞IO**优化。
## 非阻塞IO模型
非阻塞IO:如果内核数据还没准备好,可以先返回错误信息给用户进程,让它不需要等待,而是通过轮询的方式再来请求
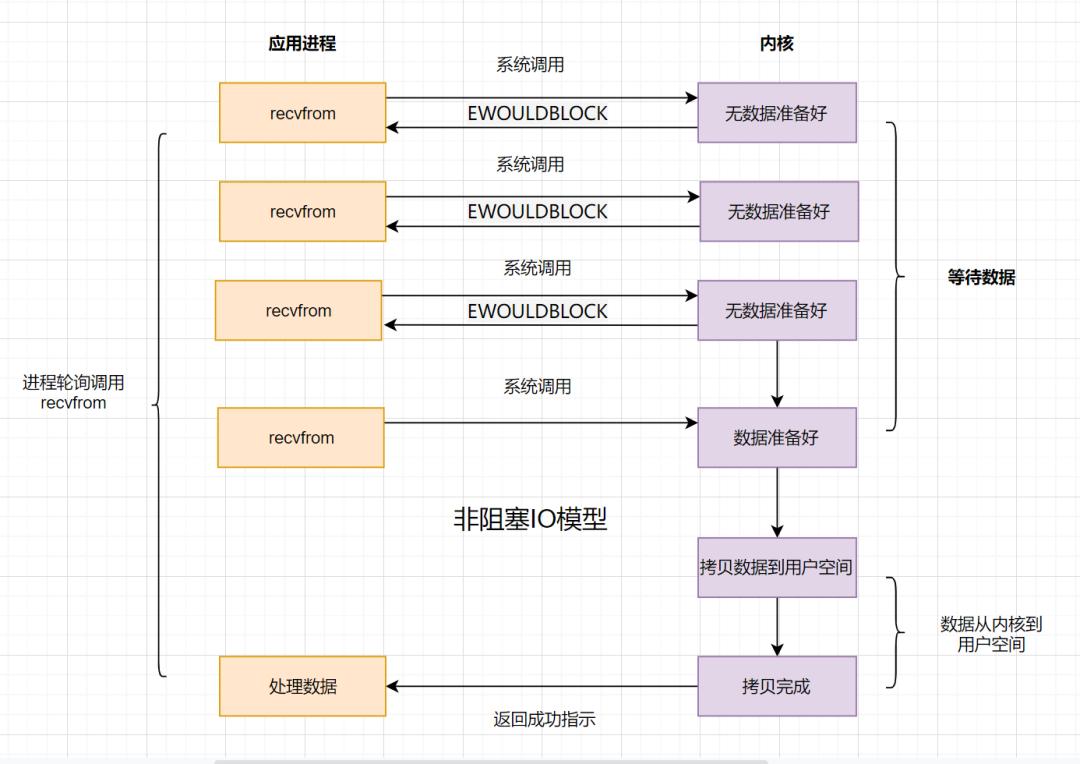
非阻塞IO的流程如下:
* 应用进程向操作系统内核,发起`recvfrom`读取数据。
* 操作系统内核数据没有准备好,立即返回`EWOULDBLOCK`错误码。
* 应用程序进程轮询调用,继续向操作系统内核发起`recvfrom`读取数据。
* 操作系统内核数据准备好了,从内核缓冲区拷贝到用户空间。
* 完成调用,返回成功提示。
非阻塞IO模型,简称**NIO**,`Non-Blocking IO`。它相对于阻塞IO,虽然大幅提升了性能,但是它依然存在**性能问题**,即**频繁的轮询**,导致频繁的系统调用,同样会消耗大量的CPU资源。可以考虑**IO复用模型**,去解决这个问题。
## IO多路复用模型
### IO复用模型核心思路
系统给我们提供**一类函数**(如我们耳濡目染的**select、poll、epoll**函数),它们可以同时监控多个`fd`的操作,任何一个返回内核数据就绪,应用进程再发起`recvfrom`系统调用。
### IO多路复用之select
应用进程通过调用**select**函数,可以同时监控多个`fd`,在`select`函数监控的`fd`中,只要有任何一个数据状态准备就绪了,`select`函数就会返回可读状态,这时应用进程再发起`recvfrom`请求去读取数据。
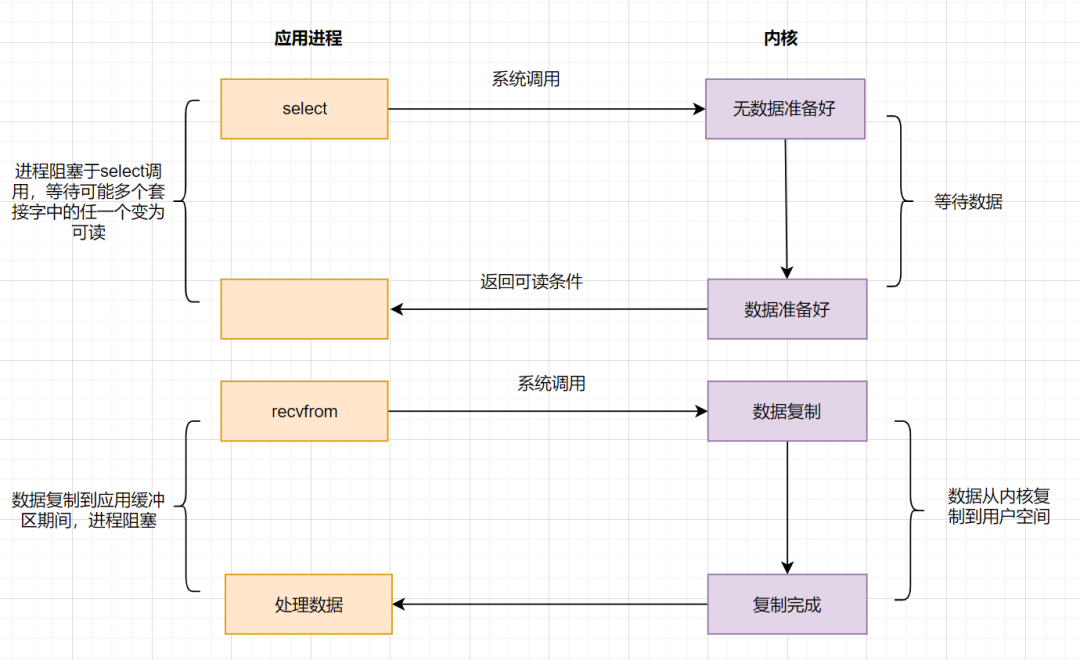
非阻塞IO模型(NIO)中,需要`N`(N>=1)次轮询系统调用,然而借助`select`的IO多路复用模型,只需要发起一次询问就够了,大大优化了性能。
### 缺点
* 监听的IO最大连接数有限,在Linux系统上一般为1024。
* select函数返回后,是通过**遍历**`fdset`,找到就绪的描述符`fd`。(仅知道有I/O事件发生,却不知是哪几个流,所以**遍历所有流**)
因为**存在连接数限制**,所以后来又提出了**poll**。与select相比,**poll**解决了**连接数限制问题**。但是呢,select和poll一样,还是需要通过遍历文件描述符来获取已经就绪的`socket`。如果同时连接的大量客户端,在一时刻可能只有极少处于就绪状态,伴随着监视的描述符数量的增长,**效率也会线性下降**。
### IO多路复用之epoll
为了解决`select/poll`存在的问题,多路复用模型`epoll`诞生,它采用事件驱动来实现。
**epoll**先通过`epoll_ctl()`来注册一个`fd`(文件描述符),一旦基于某个`fd`就绪时,内核会采用回调机制,迅速激活这个`fd`,当进程调用`epoll_wait()`时便得到通知。
采用**监听事件回调**的机制
| select | poll | epoll |
| --- | --- | --- |
| 底层数据结构 | 数组 | 链表 | 红黑树和双链表 |
| 获取就绪的fd | 遍历 | 遍历 | 事件回调 |
| 事件复杂度 | O(n) | O(n) | O(1) |
| 最大连接数 | 1024 | 无限制 | 无限制 |
| fd数据拷贝 | 每次调用select,需要将fd数据从用户空间拷贝到内核空间 | 每次调用poll,需要将fd数据从用户空间拷贝到内核空间 | 使用内存映射(mmap),不需要从用户空间频繁拷贝fd数据到内核空间 |
**epoll**明显优化了IO的执行效率,但在进程调用`epoll_wait()`时,仍然可能被阻塞
## IO模型之信号驱动模型
信号驱动IO不再用主动询问的方式去确认数据是否就绪,而是向内核发送一个信号(调用`sigaction`的时候建立一个`SIGIO`的信号),然后应用用户进程可以去做别的事,不用阻塞。当内核数据准备好后,再通过`SIGIO`信号通知应用进程,数据准备好后的可读状态。应用用户进程收到信号之后,立即调用`recvfrom`,去读取数据。
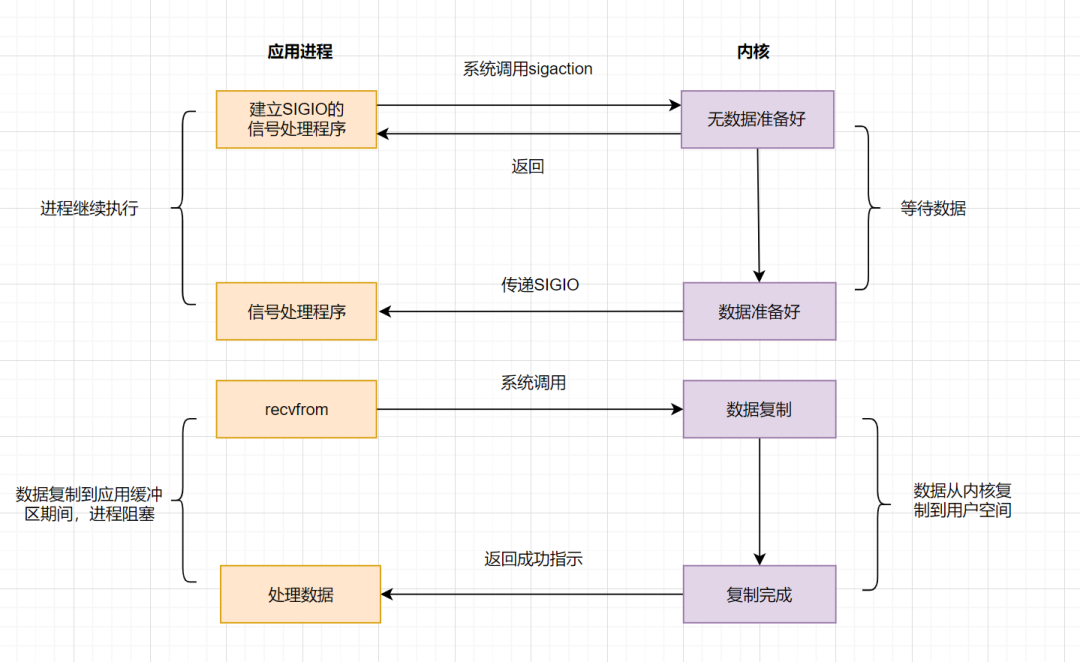
信号驱动IO模型,在应用进程发出信号后,是立即返回的,不会阻塞进程。它已经有异步操作的感觉了。但是你细看上面的流程图,**发现数据复制到应用缓冲的时候**,应用进程还是阻塞的。回过头来看下,不管是BIO,还是NIO,还是信号驱动,在数据从内核复制到应用缓冲的时候,都是阻塞的。还有没有优化方案呢?**AIO**(真正的异步IO)!
## IO 模型之异步IO(AIO)
前面讲的`BIO,NIO和信号驱动`,在数据从内核复制到应用缓冲的时候,都是**阻塞**的,因此都不算是真正的异步。
`AIO`实现了IO全流程的非阻塞,就是应用进程发出系统调用后,是立即返回的,但是**立即返回的不是处理结果,而是表示提交成功类似的意思**。等内核数据准备好,将数据拷贝到用户进程缓冲区,发送信号通知用户进程IO操作执行完毕。
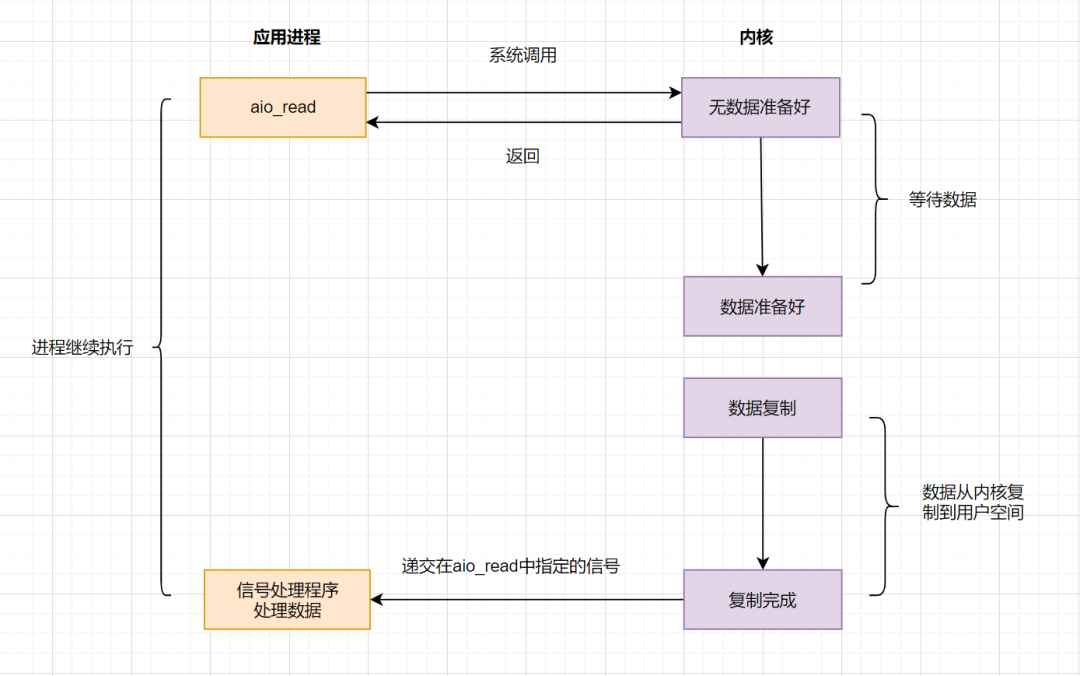
异步IO的优化思路很简单,只需要向内核发送一次请求,就可以完成数据状态询问和数据拷贝的所有操作,并且不用阻塞等待结果。
日常开发中,有类似思想的业务场景:
>比如发起一笔批量转账,但是批量转账处理比较耗时,这时候后端可以先告知前端转账提交成功,等到结果处理完,再通知前端结果即可。
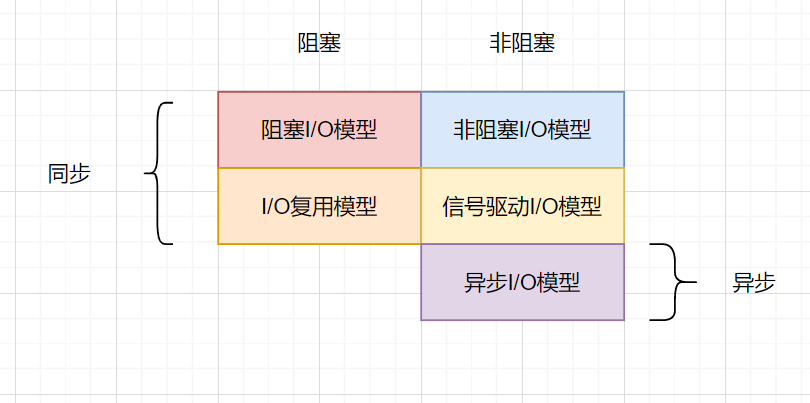
| IO模型 | |
| --- | --- |
| 阻塞I/O模型 | 同步阻塞 |
| 非阻塞I/O模型 | 同步非阻塞 |
| I/O多路复用模型 | 同步阻塞 |
| 信号驱动I/O模型 | 同步非阻塞 |
| 异步IO(AIO)模型 | 异步非阻塞 |
## 一个通俗例子读懂BIO、NIO、AIO
* 同步阻塞(blocking-IO)简称BIO
* 同步非阻塞(non-blocking-IO)简称NIO
* 异步非阻塞(asynchronous-non-blocking-IO)简称AIO
**一个经典生活的例子:**
* 小明去吃同仁四季的椰子鸡,就这样在那里排队,**等了一小时**,然后才开始吃火锅。(**BIO**)
* 小红也去同仁四季的椰子鸡,她一看要等挺久的,于是去逛会商场,**每次逛一下,就跑回来看看,是不是轮到她了**。于是最后她既购了物,又吃上椰子鸡了。(**NIO**)
* 小华一样,去吃椰子鸡,由于他是高级会员,所以店长说,**你去商场随便逛会吧,等下有位置,我立马打电话给你**。于是小华不用干巴巴坐着等,也不用每过一会儿就跑回来看有没有等到,最后也吃上了美味的椰子鸡(**AIO**)
- 消息队列
- 为什么要用消息队列
- 各种消息队列产品的对比
- 消息队列的优缺点
- 如何保证消息队列的高可用
- 如何保证消息不丢失
- 如何保证消息不会重复消费?如何保证消息的幂等性?
- 如何保证消息消费的顺序性?
- 基于MQ的分布式事务实现
- Beanstalk
- PHP
- 函数
- 基础
- 基础函数题
- OOP思想及原则
- MVC生命周期
- PHP7.X新特性
- PHP8新特性
- PHP垃圾回收机制
- php-fpm相关
- 高级
- 设计模式
- 排序算法
- 正则
- OOP代码基础
- PHP运行原理
- zavl
- 网络协议new
- 一面
- TCP和UDP
- 常见状态码和代表的意义以及解决方式
- 网络分层和各层有啥协议
- TCP
- http
- 二面
- TCP2
- DNS
- Mysql
- 锁
- 索引
- 事务
- 高可用?高并发?集群?
- 其他
- 主从复制
- 主从复制数据延迟
- SQL的语⾔分类
- mysqlQuestions
- Redis
- redis-question
- redis为什么那么快
- redis的优缺点
- redis的数据类型和使用场景
- redis的数据持久化
- 过期策略和淘汰机制
- 缓存穿透、缓存击穿、缓存雪崩
- redis的事务
- redis的主从复制
- redis集群架构的理解
- redis的事件模型
- redis的数据类型、编码、数据结构
- Redis连接时的connect与pconnect的区别是什么?
- redis的分布式锁
- 缓存一致性问题
- redis变慢的原因
- 集群情况下,节点较少时数据分布不均匀怎么办?
- redis 和 memcached 的区别?
- 基本算法
- MysqlNew
- 索引new
- 事务new
- 锁new
- 日志new
- 主从复制new
- 树结构
- mysql其他问题
- 删除
- 主从配置
- 五种IO模型
- Kafka
- Nginx
- trait
- genergtor 生成器
- 如何实现手机扫码登录功能
- laravel框架的生命周期