
[TOC]
## GOT/PLT Hook
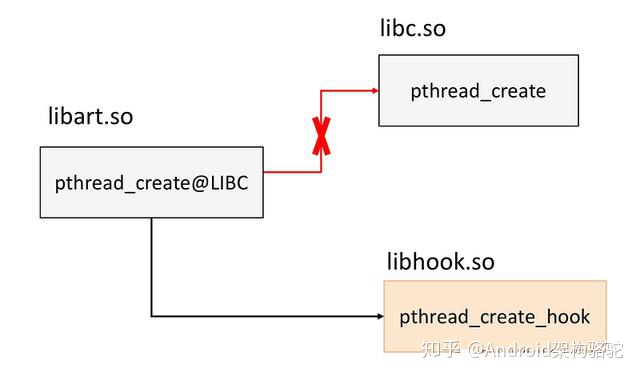
GOT/PLT Hook 主要是用于替换某个 SO 的[外部调用](),通过将外部函数调用跳转成我们的目标函数。GOT/PLT Hook 可以说是一个非常经典的 Hook 方法,它非常稳定,可以达到部署到生产环境的标准。
### ELF 格式
ELF(Executableand Linking Format)是可执行和链接格式,它是一个开放标准,各种 UNIX 系统的可执行文件大多采用 ELF 格式。虽然 ELF 文件本身就支持三种不同的类型(重定位、执行、共享),不同的视图下格式稍微不同,不过它有一个统一的结构,这个结构如下图所示。
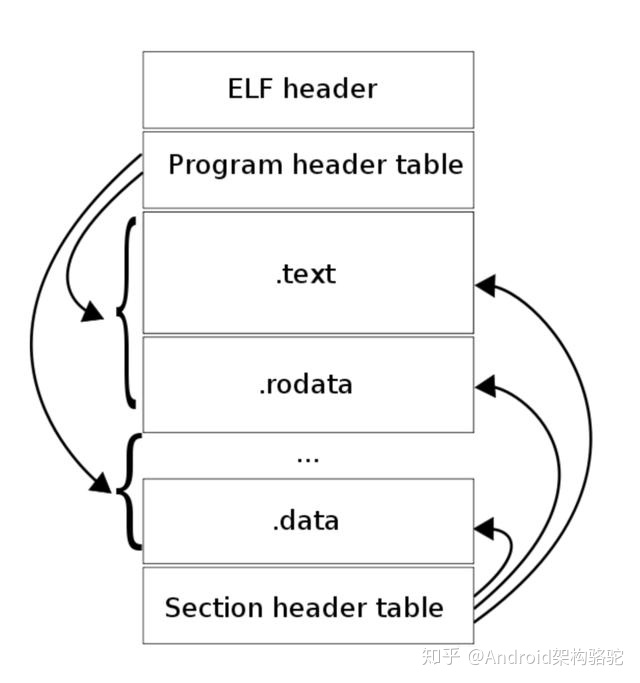
网上介绍 ELF 格式的文章非常多,你可以参考《ELF 文件格式解析》。顾名思义,对于 GOT/PLT Hook 来说,我们主要关心“.plt”和“.got”这两个节区:
* .plt。该节保存过程链接表(Procedure Linkage Table)。
* .got。该节保存着全局的偏移量表。
我们也可以使用readelf -S来查看 ELF 文件的具体信息。
### 链接过程
接下来我们再来看看动态链接的过程,当需要使用一个 Native 库(.so 文件)的时候,我们需要调用dlopen("libname.so")来加载这个库。
在我们调用了dlopen("libname.so")之后,系统首先会检查缓存中已加载的 ELF 文件列表。如果未加载则执行加载过程,如果已加载则计数加一,忽略该调用。然后系统会用从 libname.so 的dynamic节区中读取其所依赖的库,按照相同的加载逻辑,把未在缓存中的库加入加载列表。
你可以使用下面这个命令来查看一个库的依赖:
~~~text
readelf -d <library> | grep NEEDED
~~~
下面我们大概了解一下系统是如何加载的 ELF 文件的。
* 读 ELF 的程序头部表,把所有 PT\_LOAD 的节区 mmap 到内存中。
* 从“.dynamic”中读取各信息项,计算并保存所有节区的虚拟地址,然后执行重定位操作。
* 最后 ELF 加载成功,引用计数加一。
但是这里有一个关键点,在 ELF 文件格式中我们只有函数的绝对地址。如果想在系统中运行,这里需要经过重定位。这其实是一个比较复杂的问题,因为不同机器的 CPU 架构、加载顺序不同,导致我们只能在运行时计算出这个值。不过还好动态加载器(/system/bin/linker)会帮助我们解决这个问题。
如果你理解了动态链接的过程,我们再回头来思考一下“.got”和“.plt”它们的具体含义。
* **The Global Offset Table (GOT)**。简单来说就是在数据段的地址表,假定我们有一些代码段的指令引用一些地址变量,编译器会引用 GOT 表来替代直接引用绝对地址,因为绝对地址在编译期是无法知道的,只有重定位后才会得到 ,GOT 自己本身将会包含函数引用的绝对地址。
* **The Procedure Linkage Table (PLT)**。PLT 不同于 GOT,它位于代码段,动态库的每一个外部函数都会在 PLT 中有一条记录,每一条 PLT 记录都是一小段可执行代码。一般来说,外部代码都是在调用 PLT 表里的记录,然后 PLT 的相应记录会负责调用实际的函数。我们一般把这种设定叫作“蹦床”(Trampoline)。
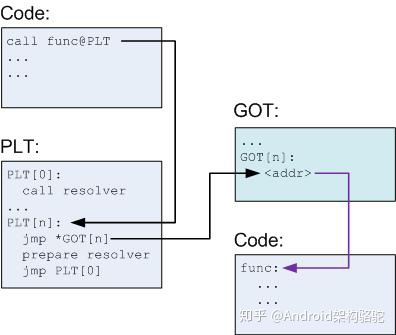
PLT 和 GOT 记录是一一对应的,并且 GOT 表第一次解析后会包含调用函数的实际地址。既然这样,那 PLT 的意义究竟是什么呢?PLT 从某种意义上赋予我们一种懒加载的能力。当动态库首次被加载时,所有的函数地址并没有被解析。下面让我们结合图来具体分析一下首次函数调用,请注意图中黑色箭头为跳转,紫色为指针。
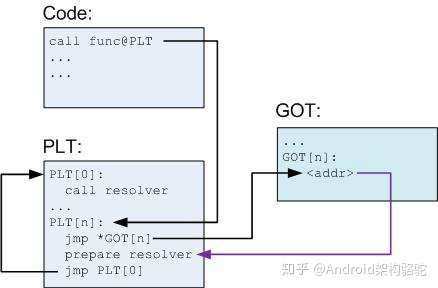
* 我们在代码中调用 func,编译器会把这个转化为 func@plt,并在 PLT 表插入一条记录。
* PLT 表中第一条(或者说第 0 条)PLT\[0\] 是一条特殊记录,它是用来帮助我们解析地址的。通常在类 Linux 系统,这个的实现会位于动态加载器,就是专栏前面文章提到的 /system/bin/linker。
* 其余的 PLT 记录都均包含以下信息:
\-- 跳转 GOT 表的指令(jmp \*GOT\[n\])。-- 为上面提到的第 0 条解析地址函数准备参数。-- 调用 PLT\[0\],这里 resovler 的实际地址是存储在 GOT\[2\] 。
在解析前 GOT\[n\] 会直接指向 jmp \*GOT\[n\] 的下一条指令。在解析完成后,我们就得到了 func 的实际地址,动态加载器会将这个地址填入 GOT\[n\],然后调用 func。
如果你对上面的这个调用流程还有疑问,你可以参考《GOT 表和 PLT 表》这篇文章,它里面有一张图非常清晰。
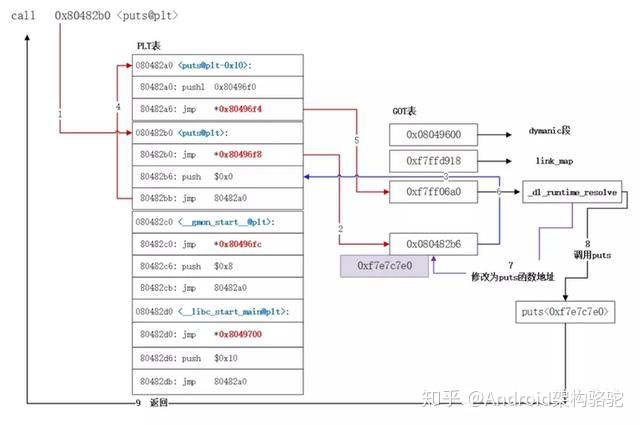
当第一次调用发生后,之后再调用函数 func 就高效简单很多。首先调用 PLT\[n\],然后执行 jmp \*GOT\[n\]。GOT\[n\] 直接指向 func,这样就高效的完成了函数调用。
总结一下,因为很多函数可能在程序执行完时都不会被用到,比如错误处理函数或一些用户很少用到的功能模块等,那么一开始把所有函数都链接好实际就是一种浪费。为了提升动态链接的性能,我们可以使用 PLT 来实现延迟绑定的功能。
对于函数运行的实际地址,我们依然需要通过 GOT 表得到,整个简化过程如下:
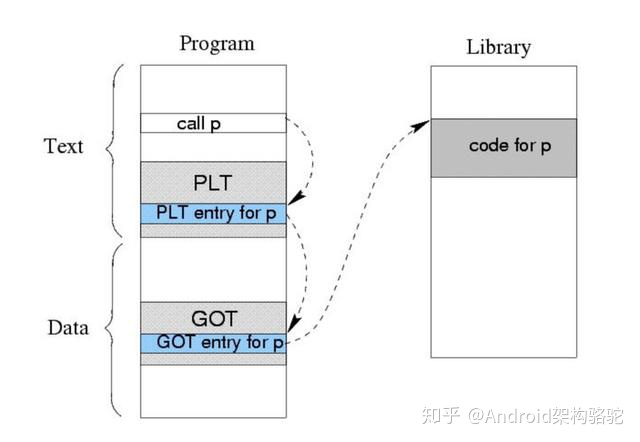
看到这里,相信你已经有了如何 Hack 这一过程的初步想法。这里业界通常会根据修改 PLT 记录或者 GOT 记录区分为 GOT Hook 和 PLT Hook,但其本质原理十分接近。
### 成熟方案
GOT/PLT Hook 看似简单,但是实现起来也是有一些坑的,需要考虑兼容性的情况。一般来说,推荐使用如下业界的成熟方案。
微信 Matrix 开源库的ELF Hook,它使用的是 GOT Hook,主要使用它来做性能监控。爱奇艺开源的的xHook,它使用的也是 GOT Hook。Facebook 的PLT Hook。
如果不想深入它内部的原理,我们只需要直接使用这些开源的优秀方案就可以了。因为这种 Hook 方式非常成熟稳定,除了 Hook 线程的创建,我们还有很多其他的使用范例。
* “I/O 优化”中使用matrix-io-canary Hook 文件的操作。
* “网络优化”中使用 Hook 了 Socket 的相关操作。
这种 Hook 方法也不是万能的,因为它只能替换导入函数的方式。有时候我们不一定可以找到这样的外部调用函数。如果想 Hook 函数的内部调用,这个时候就需要用到我们的 Trap Hook 或者 Inline Hook 了。
,并且无法Hook 未导出的私有函数,而且只存在安装与卸载 2 种状态,一旦安装就会 Hook 所有函数调用。
## Trap Hook
Trap Hook 最为稳定,但由于需要切换运行模式(R0/R3),且依赖内核的信号机制,导致性能很差。
## Inline Hook
Inline Hook 是一个非常激进的方案,有很好的性能,并且也没有 PLT 作用域的限制,可以说是一个非常灵活、完美的方案。但其实现难度极高,我至今也没有看到可以部署在生产环境的 Inline Hook 方案,因为涉及指令修复,需要编译器的各种优化。
但是需要注意,无论是哪一种 Hook 都只能 Hook 到应用自身的进程,我们无法替换系统或其他应用进程的函数执行。
# 参考资料
[Android Native Hook技术你知道多少?](https://zhuanlan.zhihu.com/p/132699875)
- Android
- 四大组件
- Activity
- Fragment
- Service
- 序列化
- Handler
- Hander介绍
- MessageQueue详细
- 启动流程
- 系统启动流程
- 应用启动流程
- Activity启动流程
- View
- view绘制
- view事件传递
- choreographer
- LayoutInflater
- UI渲染概念
- Binder
- Binder原理
- Binder最大数据
- Binder小结
- Android组件
- ListView原理
- RecyclerView原理
- SharePreferences
- AsyncTask
- Sqlite
- SQLCipher加密
- 迁移与修复
- Sqlite内核
- Sqlite优化v2
- sqlite索引
- sqlite之wal
- sqlite之锁机制
- 网络
- 基础
- TCP
- HTTP
- HTTP1.1
- HTTP2.0
- HTTPS
- HTTP3.0
- HTTP进化图
- HTTP小结
- 实践
- 网络优化
- Json
- ProtoBuffer
- 断点续传
- 性能
- 卡顿
- 卡顿监控
- ANR
- ANR监控
- 内存
- 内存问题与优化
- 图片内存优化
- 线下内存监控
- 线上内存监控
- 启动优化
- 死锁监控
- 崩溃监控
- 包体积优化
- UI渲染优化
- UI常规优化
- I/O监控
- 电量监控
- 第三方框架
- 网络框架
- Volley
- Okhttp
- 网络框架n问
- OkHttp原理N问
- 设计模式
- EventBus
- Rxjava
- 图片
- ImageWoker
- Gilde的优化
- APT
- 依赖注入
- APT
- ARouter
- ButterKnife
- MMKV
- Jetpack
- 协程
- MVI
- Startup
- DataBinder
- 黑科技
- hook
- 运行期Java-hook技术
- 编译期hook
- ASM
- Transform增量编译
- 运行期Native-hook技术
- 热修复
- 插件化
- AAB
- Shadow
- 虚拟机
- 其他
- UI自动化
- JavaParser
- Android Line
- 编译
- 疑难杂症
- Android11滑动异常
- 方案
- 工业化
- 模块化
- 隐私合规
- 动态化
- 项目管理
- 业务启动优化
- 业务架构设计
- 性能优化case
- 性能优化-排查思路
- 性能优化-现有方案
- 登录
- 搜索
- C++
- NDK入门
- 跨平台
- H5
- Flutter
- Flutter 性能优化
- 数据跨平台