
[TOC]
# 线下
## 流畅度
gfxinfo、开发者模式的GPU渲染、perfdog、LayoutInspect都提供了卡顿监控的能力,不过都是肉眼观察数据判断是否发生卡顿。
## 慢函数
### TraceView
Traceview利用 Android Runtime 函数调用的 event 事件,将函数运行的耗时和调用关系写入 trace 文件中。
由此可见,Traceview 属于 instrument 类型,它可以用来查看整个过程有哪些函数调用,但是工具本身带来的性能开销过大,有时无法反映真实的情况。比如一个函数本身的耗时是 1 秒,开启 Traceview 后可能会变成 5 秒,而且这些函数的耗时变化并不是成比例放大。
使用`Debug.startMethodTracing()`以及`Debug.stopMethodTracing()`可以在程序中动态开启TraceView。
在 Android 5.0 之后,新增了`Debug.startMethodTracingSampling`方法,可以使用基于样本的方式进行分析,以减少分析对运行时的性能影响。新增了 sample 类型后,就需要我们在开销和信息丰富度之间做好权衡。
### systrace
[systrace](https://source.android.com/devices/tech/debug/systrace?hl=zh-cn)是 Android 4.1 新增的性能分析工具。我通常使用 systrace 跟踪系统的 I/O 操作、CPU 负载、Surface 渲染、GC 等事件。
systrace 利用了 Linux 的[ftrace](https://source.android.com/devices/tech/debug/ftrace)调试工具,相当于在系统各个关键位置都添加了一些性能探针,也就是在代码里加了一些性能监控的埋点。Android 在 ftrace 的基础上封装了[atrace](https://android.googlesource.com/platform/frameworks/native/+/master/cmds/atrace/atrace.cpp),并增加了更多特有的探针,例如 Graphics、Activity Manager、Dalvik VM、System Server 等。
systrace 工具只能监控特定系统调用的耗时情况,所以它是属于 sample 类型,而且性能开销非常低。但是它不支持应用程序代码的耗时分析,所以在使用时有一些局限性。
由于系统预留了`Trace.beginSection`接口来监听应用程序的调用耗时,那我们有没有办法在 systrace 上面自动增加应用程序的耗时分析呢?
划重点了,我们可以通过**编译时给每个函数插桩**的方式来实现,也就是在重要函数的入口和出口分别增加`Trace.beginSection`和`Trace.endSection`。当然出于性能的考虑,我们会过滤大部分指令数比较少的函数,这样就实现了在 systrace 基础上增加应用程序耗时的监控。通过这样方式的好处有:
* 可以看到整个流程系统和应用程序的调用流程。包括系统关键线程的函数调用,例如渲染耗时、线程锁,GC 耗时等。
* 性能损耗可以接受。由于过滤了大部分的短函数,而且没有放大 I/O,所以整个运行耗时不到原来的两倍,基本可以反映真实情况。
systrace 生成的也是 HTML 格式的结果,我们利用跟 Nanoscope 相似方式实现对反混淆的支持。
# 线上
## 卡顿监控
### 主进程-Handle
#### 替换 Looper 的 Printer
Looper#loop 代码片段
~~~
public static void loop() {
...
for (;;) {
...
// This must be in a local variable, in case a UI event sets the logger
Printer logging = me.mLogging;
if (logging != null) {
logging.println(">>>>> Dispatching to " + msg.target + " " +
msg.callback + ": " + msg.what);
}
msg.target.dispatchMessage(msg);
if (logging != null) {
logging.println("<<<<< Finished to " + msg.target + " " + msg.callback);
}
...
}
}
~~~
简单实现
~~~
class LooperMonitor implements Printer {
@Override
public void println(String x) {
if (!mPrintingStarted) {
mStartTimestamp = System.currentTimeMillis();
mStartThreadTimestamp = SystemClock.currentThreadTimeMillis();
mPrintingStarted = true;
// 1:处理消息前
startDump();
} else {
final long endTime = System.currentTimeMillis();
mPrintingStarted = false;
if (isBlock(endTime)) {
// 2:处理消息后,如果超时了就获取堆栈并输出
notifyBlockEvent(endTime);
}
stopDump();
}
}
private boolean isBlock(long endTime) {
return endTime - mStartTimestamp > mBlockThresholdMillis;
}
private void startDump() {
BlockCanaryInternals.getInstance().stackSampler.start();
}
private void stopDump() {
BlockCanaryInternals.getInstance().stackSampler.stop();
}
}
~~~
缺点
1. View的TouchEvent中的卡顿这种方案是无法监控的
2. IdleHandler的queueIdle()回调方法也是无法被监控的
3. SyncBarrier(同步屏障)的泄漏同样无法被监控到
4. 需要使用idleHandler循环的检测Looper.mLogging
5. 没有开启Looper的子线程,无法监控
优点
1. 真正有任务执行的时候才监控
#### 插入空消息到消息队列
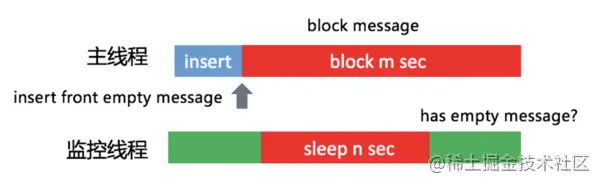
通过一个监控线程,每隔1秒向主线程消息队列的头部插入一条空消息。假设1秒后这个消息并没有被主线程消费掉,说明阻塞消息运行的时间在0~1秒之间。换句话说,如果我们需要监控3秒卡顿,那在第4次轮询中,头部消息依然没有被消费的话,就可以确定主线程出现了一次3秒以上的卡顿。
### Choreographer#doFrame 间隔检测
简单代码实现如下:
~~~
Choreographer.getInstance().postFrameCallback(new Choreographer.FrameCallback() {
@Override
public voiddoFrame(long frameTimeNanos) {
if(frameTimeNanos \- mLastFrameNanos \>100) {
...
}
mLastFrameNanos \= frameTimeNanos;
Choreographer.getInstance().postFrameCallback(this);
}
});
~~~
## 慢函数
### 线程采样
#### 高频采样
在事件进入时,开启一个延时的定时任务,如果任务在规定时间内完成则取消掉,否则开始间隔52ms抓取堆栈对象,最多抓取3秒数据的堆栈。当事件执行结束时,如果总耗时超过卡顿阈值,则将抓取到的多个堆栈,进行合并,将合并后的堆栈树进行上报,如下所示:
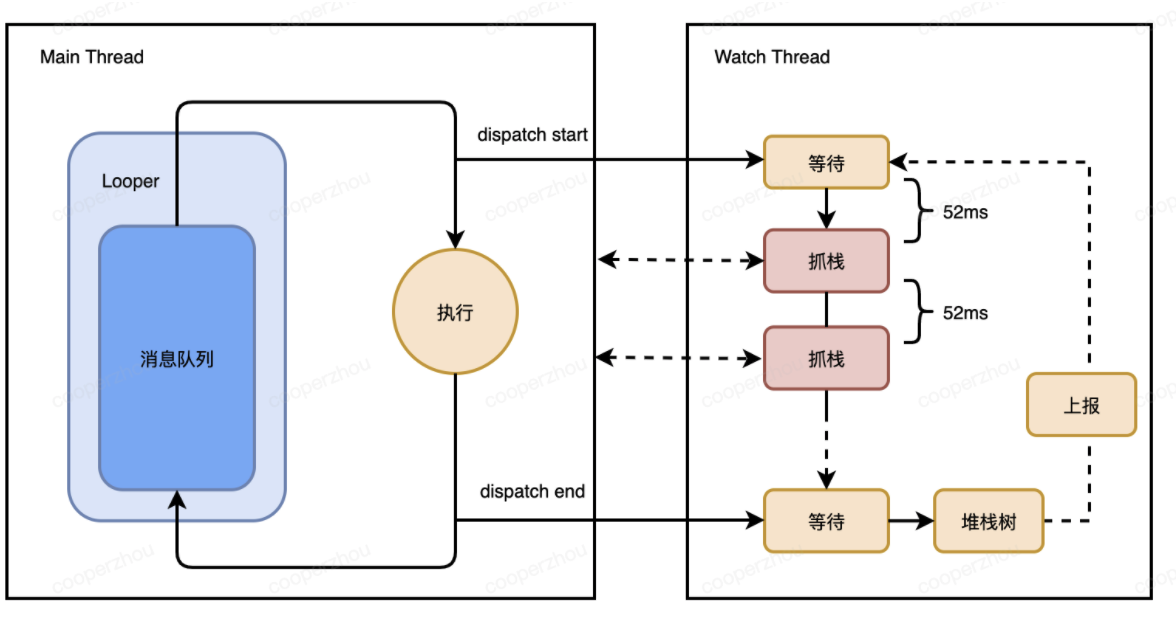
一个堆栈树节点包含以下内容:
1. method:节点对应的方法,如 android.app.ActivityThread.performLaunchActivity
2. weight:节点方法的耗时权重,即该方法在整个消息执行过程中,堆栈数组中出现的个数
3. sliceIndex:节点方法所在的时间片集合,一个完整的堆栈为一个时间片(52ms)
4. children:节点方法下的子节点,即下一个执行的方法
### 3.1.2 堆栈树设计
### 微信 ASM插桩
方案:
1. 为每个插桩的函数分配一个独立 ID
2. 在方法前后插入了 MethodBeat.i/o 的方法
3. MethodBeat有个预先初始化好的数组 long\[\] 中 index 的位置(预先分配记录数据的 buffer 长度为 100w,内存占用约 7.6M)。
4. 数组保存并当前执行的是 MethodBeat i或者o、mehtod id 及时间 offset
5. Choreographer 注册监听,在每一帧 doframe 回调时判断距离上一帧的时间差是否超出阈值(卡顿),如果超出阈值,则获取数组 index 前的所有数据(即两帧之间的所有函数执行信息)进行分析上报。同时,我们在每一帧 doFrame 到来时,重置一个定时器,如果 5s 内没有 cancel,则认为 ANR 发生,这时会主动取出当前记录的 buffer 数据进行独立分析上报,
优化点:
1. 扫描的函数是否只含有 PUT/READ FIELD 等简单的指令,来过滤一些默认或匿名构造函数,以及 get/set 等简单不耗时函数。
2. 时间不是实时获取,而是每 5ms 去更新一个时间变量
缺点:
Matrix的堆栈信息并不包含非系统堆栈信息,无法进行进行一些系统场景,比如Binder耗时,锁耗时等问题,当其无法监听系统堆栈时,其显示效果如下
### Facebook- Profilo
2018 年 3 月,Facebook 开源了一个叫[Profilo](https://github.com/facebookincubator/profilo)的库,它收集了各大方案的优点,令我眼前一亮。具体来说有以下几点:
**第一,集成 atrace 功能**。ftrace 所有性能埋点数据都会通过 trace\_marker 文件写入内核缓冲区,Profilo 通过 PLT Hook 拦截了写入操作,选择部分关心的事件做分析。这样所有 systrace 的探针我们都可以拿到,例如四大组件生命周期、锁等待时间、类校验、GC 时间等。
**不过大部分的 atrace 事件都比较笼统,从事件“B|pid|activityStart”,我们并不知道具体是哪个 Activity 的创建**。同样我们可以统计 GC 相关事件的耗时,但是也不知道为什么发生了这次 GC。

**第二,快速获取 Java 堆栈。很多同学有一个误区,觉得在某个线程不断地获取主线程堆栈是不耗时的。但是事实上获取堆栈的代价是巨大的,它要暂停主线程的运行。**
Profilo 的实现非常精妙,它实现类似 Native 崩溃捕捉的方式快速获取 Java 堆栈,通过间隔发送 SIGPROF 信号,整个过程如下图所示。
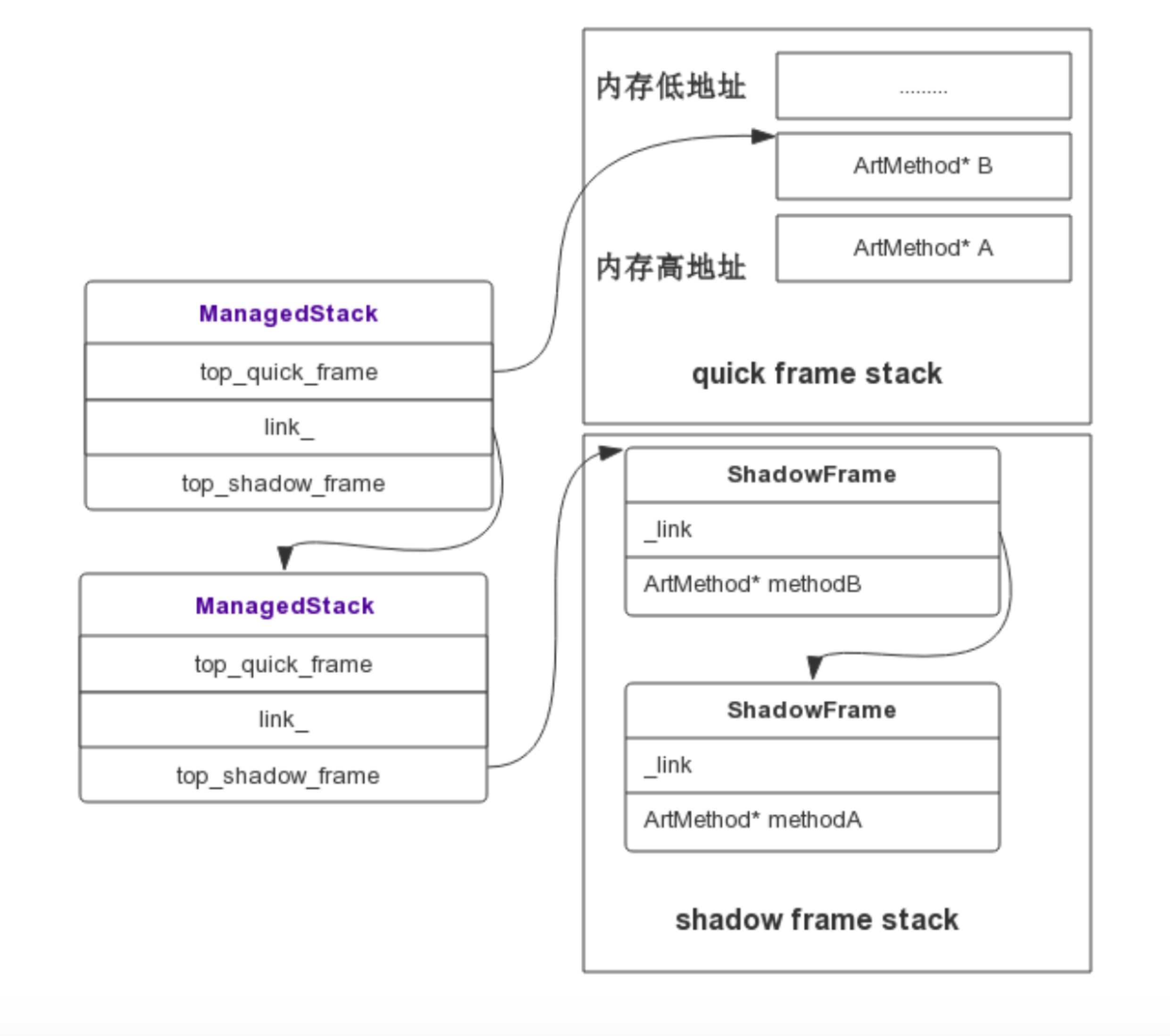
Signal Handler 捕获到信号后,拿取到当前正在执行的 Thread,通过 Thread 对象可以获取当前线程的 ManagedStack,ManagedStack 是一个单链表,它保存了当前的 ShadowFrame 或者 QuickFrame 栈指针,先依次遍历 ManagedStack 链表,然后遍历其内部的 ShadowFrame 或者 QuickFrame 还原一个可读的调用栈,从而 unwind 出当前的 Java 堆栈。通过这种方式,可以实现线程一边继续跑步,我们还可以帮它做检查,而且耗时基本忽略不计。代码可以参照:[Profilo::unwind](https://github.com/facebookincubator/profilo/blob/master/cpp/profiler/unwindc/android_712/arm/unwinder.h)和[StackVisitor::WalkStack](http://androidxref.com/7.1.1_r6/xref/art/runtime/stack.cc#772)。
不用插桩、性能基本没有影响、捕捉信息还全,那 Profilo 不就是完美的化身吗?当然由于它利用了大量的黑科技,兼容性是需要注意的问题。它内部实现有大量函数的 Hook,unwind 也需要强依赖 Android Runtime 实现。Facebook 已经将 Profilo 投入到线上使用,但由于目前 Profilo 快速获取堆栈功能依然不支持 Android 8.0 和 Android 9.0,鉴于稳定性问题,建议采取抽样部分用户的方式来开启该功能。
### 西瓜
通过偏移+校验的方式读取到 Thread List,使用 SusopendThraedByPeer 函数传入目标THread 对象的 jobkect 完成对目标线程的挂起。
获取到 ThreadList 和函数指针后,在栈回溯的前后调用 Suspend 和 Resume 即可完成一次跨线程栈回溯。
在 Suspend 和 Resume 之间,仅执行 WalkStack 的操作,堆栈记录和其他操作则放在 Resume 后执行,保证线程被挂起的时间足够短,这样可以确保性能最优。线程挂起机制经过实践验证可以满足现有需求,实际运行中也未发现无法攻克的问题。另外线程挂起相较于信号机制,可以将大部分操作放到 Resume 后执行,而信号机制记录堆栈等操作需要在回调内做,额外增加耗时,所以最后决定选用线程挂起方案。
# 参考资料
[抖音 Android 性能优化系列:新一代全能型性能分析工具 Rhea](https://toutiao.io/posts/p99i0mc/preview)
[西瓜视频稳定性治理体系建设三:Sliver 原理及实践](https://blog.csdn.net/ByteDanceTech/article/details/119621240)
[Matrix TraceCanary -- 初恋·卡顿](https://mp.weixin.qq.com/s/W4-1tfepKg2XMYvVn62B-Q)
[微信Android客户端的卡顿监控方案](https://mp.weixin.qq.com/s/3dubi2GVW\_rVFZZztCpsKg)
[ 面试官又来了:你的app卡顿过吗?](https://juejin.cn/post/6844903949560971277)
- Android
- 四大组件
- Activity
- Fragment
- Service
- 序列化
- Handler
- Hander介绍
- MessageQueue详细
- 启动流程
- 系统启动流程
- 应用启动流程
- Activity启动流程
- View
- view绘制
- view事件传递
- choreographer
- LayoutInflater
- UI渲染概念
- Binder
- Binder原理
- Binder最大数据
- Binder小结
- Android组件
- ListView原理
- RecyclerView原理
- SharePreferences
- AsyncTask
- Sqlite
- SQLCipher加密
- 迁移与修复
- Sqlite内核
- Sqlite优化v2
- sqlite索引
- sqlite之wal
- sqlite之锁机制
- 网络
- 基础
- TCP
- HTTP
- HTTP1.1
- HTTP2.0
- HTTPS
- HTTP3.0
- HTTP进化图
- HTTP小结
- 实践
- 网络优化
- Json
- ProtoBuffer
- 断点续传
- 性能
- 卡顿
- 卡顿监控
- ANR
- ANR监控
- 内存
- 内存问题与优化
- 图片内存优化
- 线下内存监控
- 线上内存监控
- 启动优化
- 死锁监控
- 崩溃监控
- 包体积优化
- UI渲染优化
- UI常规优化
- I/O监控
- 电量监控
- 第三方框架
- 网络框架
- Volley
- Okhttp
- 网络框架n问
- OkHttp原理N问
- 设计模式
- EventBus
- Rxjava
- 图片
- ImageWoker
- Gilde的优化
- APT
- 依赖注入
- APT
- ARouter
- ButterKnife
- MMKV
- Jetpack
- 协程
- MVI
- Startup
- DataBinder
- 黑科技
- hook
- 运行期Java-hook技术
- 编译期hook
- ASM
- Transform增量编译
- 运行期Native-hook技术
- 热修复
- 插件化
- AAB
- Shadow
- 虚拟机
- 其他
- UI自动化
- JavaParser
- Android Line
- 编译
- 疑难杂症
- Android11滑动异常
- 方案
- 工业化
- 模块化
- 隐私合规
- 动态化
- 项目管理
- 业务启动优化
- 业务架构设计
- 性能优化case
- 性能优化-排查思路
- 性能优化-现有方案
- 登录
- 搜索
- C++
- NDK入门
- 跨平台
- H5
- Flutter
- Flutter 性能优化
- 数据跨平台