
# 生产者消息分区机制
## 背景需求
* 希望数据能够均匀地分配到所有 Broker
## 为什么分区
* Kafka 消息组织结构的三层结构:Topic - Partition - Record
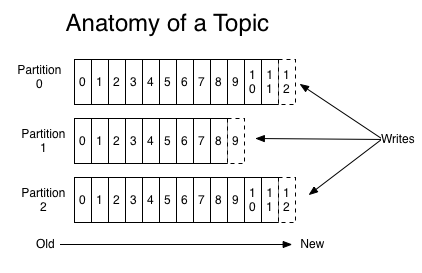
* 分区的目的:提供负载均衡的能力,i.e. 系统的高伸缩性(Scalability)
* 不同的分区能够放在不同的节点,数据的读写以分区粒度进行
* 因此可以增加节点机器来增加系统吞吐
* 不同系统分区的叫法
* Kafka:Partition 分区
* MongoDB / ElasticSearch:Shard 分片
* HBase:Region
* Cassandra:vnode
* 它们底层的思想都是 Partitioning
## 分区策略
* 分区策略:决定生产者将消息发送到哪个分区的算法
* 自定义分区策略
* 配置 Producer 的参数:partitioner.class
* 实现:编写一个具体的类实现 `org.apache.kafka.clients.producer.Partitioner` 接口
* 该接口只定义了两个方法:partition(), close()
```
int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster);
```
* 充分利用参数对信息计算,将其发到哪个分区
### 常见分区策略
* 轮询策略,i.e. Round-robin 策略
* 顺序分配
* 默认分区策略
* 随机策略,i.e. Randomness 策略
* 按消息键保序策略,i.e. Key-ordering 策略
* 每条消息定义消息键,i.e. Key
* 默认分区策略有两种
* 如果没指定 Key,则是轮询策略
* 否则是 Key-ordering 策略
### 其他分区策略
* 基于地理位置的分区策略
* e.g. 跨城市大规模 Kafka 集群
## 其他
* Kafka 中同一个 Topic 不保证消息顺序性,但是 Topic 下同一个 Partition 是保障顺序性的
- 概览
- 入门
- 1. 消息引擎系统
- 2. Kafka 术语
- 3. 分布式流处理平台
- 4. Kafka “发行版”
- 5. Kafka 版本号
- 基本使用
- 6. 生产集群部署
- 7. 集群参数配置
- 客户端实践与原理
- 9. Consumer 分区机制
- 10. Consumer 压缩算法
- 11. 无消息丢失配置
- 12. 客户端高级功能
- 13. Producer 管理 TCP
- 14. 幂等生产者和事务生产者
- 15. 消费者组
- 16. 位移主题
- 17. 消费者组重平衡(TODO)
- 18. 位移提交
- 19. CommitFailedException
- 20. 多线程开发者实例
- 21. Consumer 管理 TCP
- 22. 消费者组消费进度监控
- Kafka 内核
- 23. 副本机制
- 24. 请求处理
- 25. Rebalance 全流程
- 26. Kafka 控制器
- 27. 高水位和 Leader Epoch
- 管理与监控
- 28. Topic 管理
- 29. Kafka 动态配置
- 30. 重设消费者组位移
- 31. 工具脚本
- 32. KafkaAdminClient
- 33. 认证机制
- 34. 云下授权
- 35. 跨集群备份 MirrorMaker
- 36. 监控 Kafka
- 37. Kafka 监控框架
- 38. 调优 Kafka
- 39. 实时日志流处理平台
- 流处理
- 40. Kafka Streams
- 41. Kafka Streams DSL
- 42. Kafka Streams 金融
- Q&A