
# Kafka 副本机制
副本机制(Replication) aka. 备份机制:指分布式系统在多台互联的机器上保存有相同的数据拷贝
副本优势
* 提供数据冗余
* 提供高伸缩性
* 支持横向扩展
* 增加机器即可提升读性能
* 改善数据局部性
* 允许数据放入用户地理位置相近的地方从而降低延时
> Apache Kafka 只实现了第一点
## Kafka 副本定义
* 副本的定义是在分区(Partition)层下定义的,i.e. 每个分区有多个副本
* 副本(Replica):本质是只能追加写消息的提交日志
* 副本分散保存在不同的 Broker 上
## Kafka 副本角色
Q:如何确保副本中所有的数据都是一致的?
A:基于领导者(Leader-based)的副本机制
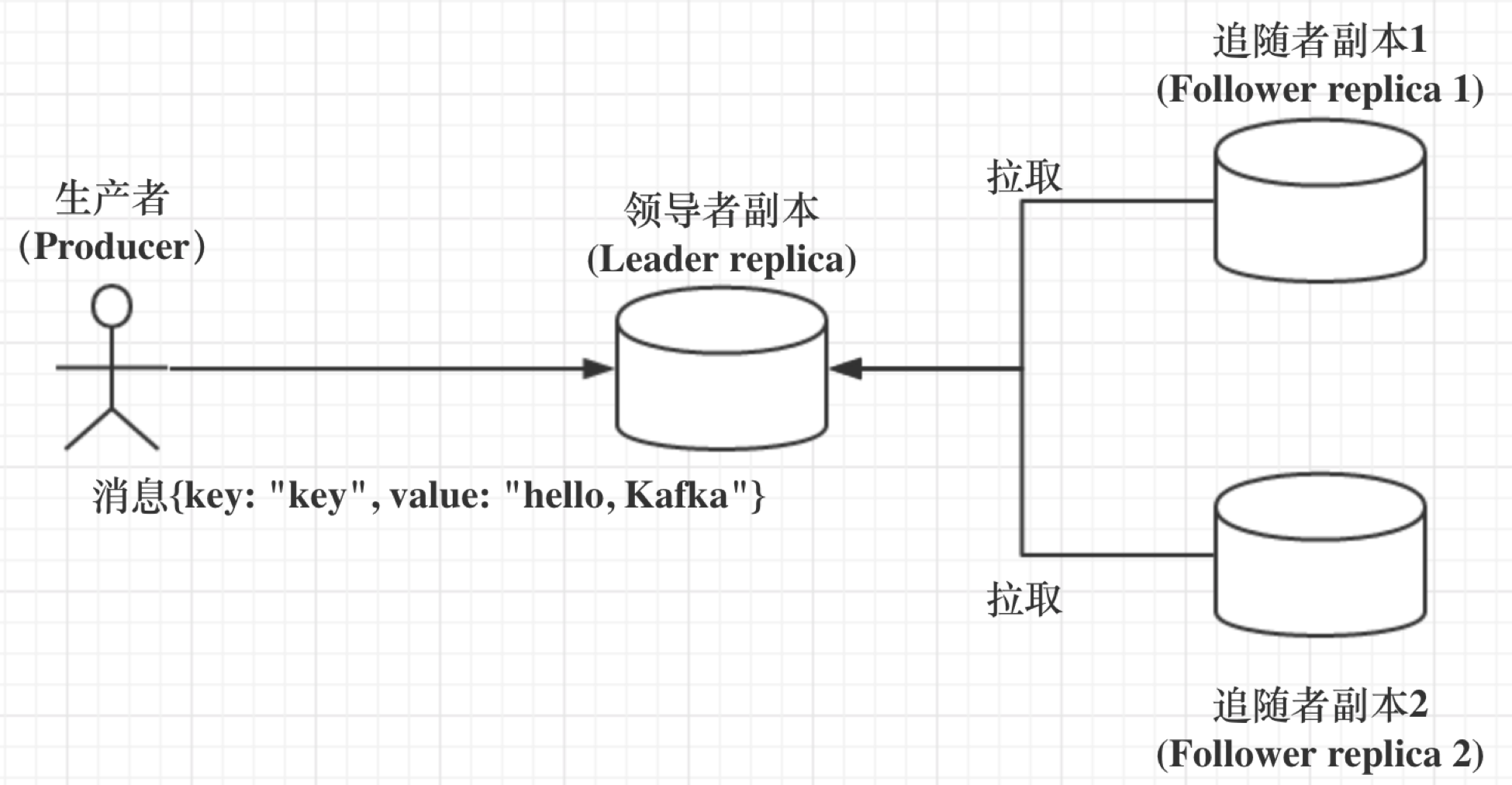
* Kafka 中副本分为领导者副本(Leader Replica) & 追随者副本(Follower Replica)
* 每个 Partition 创建时都要选举一个副本,称为 Leader Replica,其余副本为 Follower Replica
* Kafka 中 Follower Replica 不对外提供服务
* 所有读写请求均发生在 Leader Replica 所在的 Broker,由该 Broker 负责
* Follower Replica 的唯一职责:从 Leader Replica 异步拉取消息,写入到自己的提交日志中
* Leader Replica / Broker 宕机时,Kafka 依靠 ZK 提供的监控功能开启新一轮 Leader Election
* 从 Follower Replica 中选取
* 老 Leader Replica 恢复后会作为 Follower Replica 加入集群
这种副本机制设计的优势
* 方便实现 Read-your-writes
* Read-your-writes:当你使用 Producer API 写消息后,马上使用 Consumer API 去消费
* 如果允许 Follower 对外提供服务,由于异步,因此不能实现 Read-your-writes
* 方便实现单调读(Monotonic Reads)
* 单调读:对于一个 Consumer,多次消费时,不会看到某条消息一会存在一会不存在
* 问题案例
* 如果允许 Follower 提供服务,假设有两个 Follower F1、F2
* 如果 F1 拉取了最新消息而 F2 还没有
* 对于 Consumer 第一次消费时从 F1 看到的消息,第二次从 F2 则可能看不到
* 这种场景是非单调读
* 所有读请求通过 Leader 则可以实现单调读
* In-sync Replicas(ISR)
* 对于 Follower 存在与 Leader 不同步的风险
* Kafka 要明确 Follower 在什么条件下算与 Leader 同步,因此引入 ISR 副本集合
* Q:什么副本算作 ISR?
* A:
* Leader 天然在 ISR 中,某些情况 ISR 中只有 Leader
* Kafka 判断 Follower 和 Leader 同步的标准基于 Broker 端参数 `replica.lag.time.max.ms`,i.e. Follower Replica 能够落后 Leader Replica 的最长时间间隔,默认值是 10s
* 如果一个 Follower 落后 Leader 不超过 10s,则认为该 Follower 是同步的,即该 Follower 被认为是 ISR
* ISR 是动态调整的
## Unclean Leader Election
* 由于 ISR 是动态调整的,可能出现 ISR 为空,即 Leader 宕机,Follower 都不同步
* ISR 为空时,如何选举新 Leader?
* `非同步副本`:Kafka 把所有不在 ISR 中的存活副本称为非同步副本
* Broker 参数 `unclean.leader.election.enable` 控制是否允许 Unclean Leader Election
* 即如果参数为 true,ISR 为空是,会从非同步副本中选举 Leader
---
* 优势:提高可用性
* 缺点:数据丢失
基于 CAP,Kafka 赋予你选择 C / A 的权利。
- 概览
- 入门
- 1. 消息引擎系统
- 2. Kafka 术语
- 3. 分布式流处理平台
- 4. Kafka “发行版”
- 5. Kafka 版本号
- 基本使用
- 6. 生产集群部署
- 7. 集群参数配置
- 客户端实践与原理
- 9. Consumer 分区机制
- 10. Consumer 压缩算法
- 11. 无消息丢失配置
- 12. 客户端高级功能
- 13. Producer 管理 TCP
- 14. 幂等生产者和事务生产者
- 15. 消费者组
- 16. 位移主题
- 17. 消费者组重平衡(TODO)
- 18. 位移提交
- 19. CommitFailedException
- 20. 多线程开发者实例
- 21. Consumer 管理 TCP
- 22. 消费者组消费进度监控
- Kafka 内核
- 23. 副本机制
- 24. 请求处理
- 25. Rebalance 全流程
- 26. Kafka 控制器
- 27. 高水位和 Leader Epoch
- 管理与监控
- 28. Topic 管理
- 29. Kafka 动态配置
- 30. 重设消费者组位移
- 31. 工具脚本
- 32. KafkaAdminClient
- 33. 认证机制
- 34. 云下授权
- 35. 跨集群备份 MirrorMaker
- 36. 监控 Kafka
- 37. Kafka 监控框架
- 38. 调优 Kafka
- 39. 实时日志流处理平台
- 流处理
- 40. Kafka Streams
- 41. Kafka Streams DSL
- 42. Kafka Streams 金融
- Q&A