
## 说明
匹配方式(匹配符)这个是规则配置的基础,需要深入的理解,并融会贯通才可以配置出自己想要的规则
**对应匹配规则中第二个参数**
## 匹配符
这里就通过一些例子来让大家对匹配符有更清楚的理解,这里关键的前提是 **能不用正则就不用!!!**
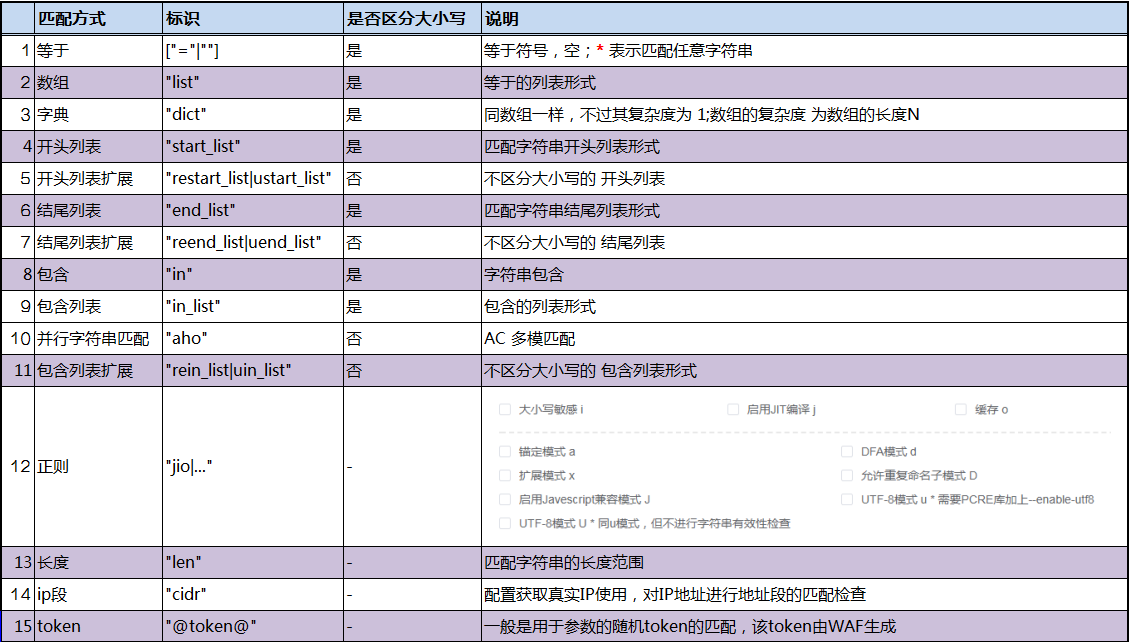
### 等于
等于匹配是进行字符串的完全匹配,是区分大小写的。
比如匹配域名时,匹配符选择等于,如果我要匹配`www.abc.com`那边就可以在内容处填写该内容
第一个参数就是配置的域名,第二个参数为空/或者 `=`,第三参数表示是否取反(可以省略不写)
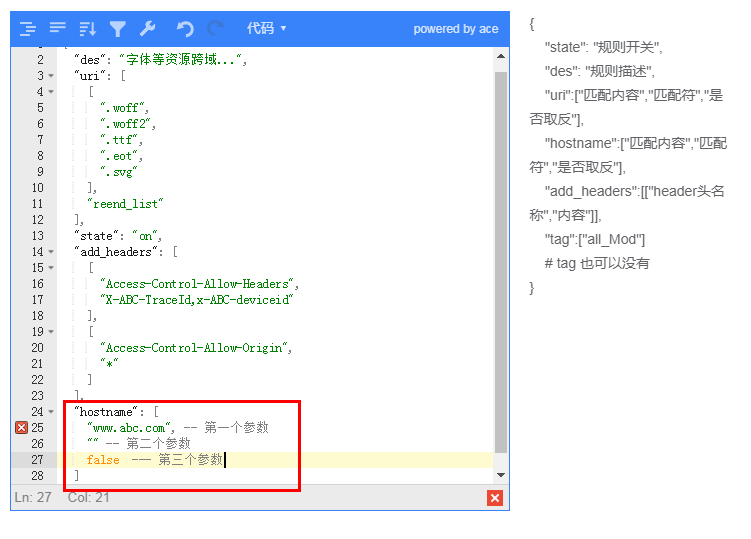
### 数组
等于匹配时只有一个不够用,当匹配多个相等的内容时,就可以使用数组(满足数组中任何一个即为真)
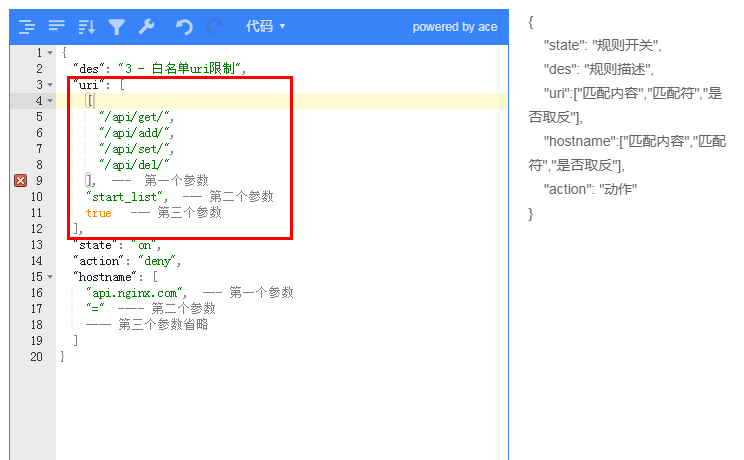
当我们需要进行对接口进行白名单控制,不是我们允许的`uri` 就可以全部拒绝访问,配合取反功能即可
```
域名 api.nginx.com 对外有4个 接口 uri
/api/get/some-msg
/api/add/some-msg
/api/set/some-msg
/api/del/some-msg
```
例子:在普通规则 --- uri 页中可以这样配置
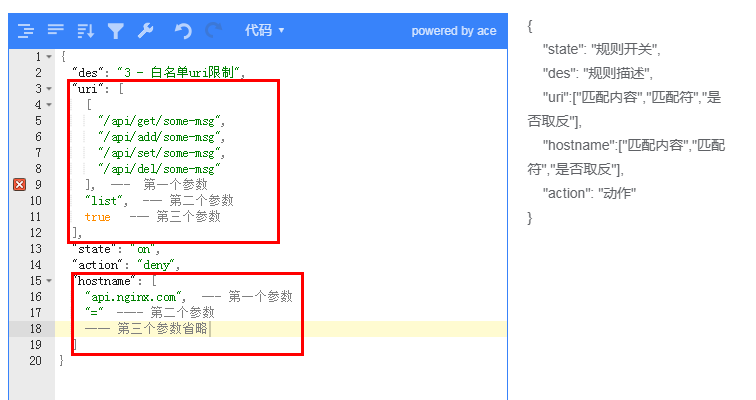
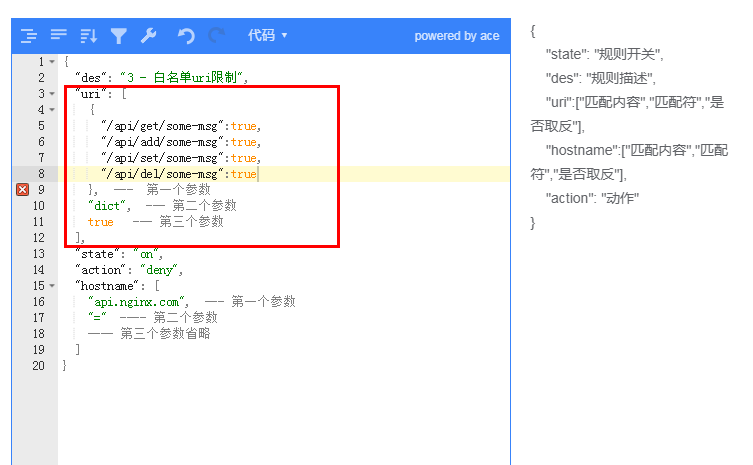
### 字典
数组匹配时条目太多(超过500个)使用,和数组效果一样,不过其空间复杂度为 1 ,效率更高,其有2个参数一个是匹配的内容,一个是布尔类型,真:表示匹配,假:表示不匹配
例子:实现和上面一样的作用,使用字典来配置
### 开头列表/开头扩展列表
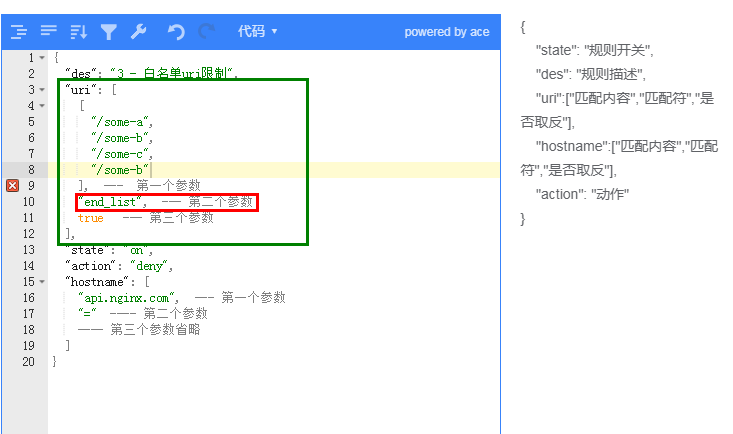
开头列表:名字标记有些俗气,但是非常好理解,就是匹配字符串开头,且是一个数组(数组中任意一个匹配成功,即匹配命中)
开头扩展列表:仅仅是不区分大小写的开头列表
```
当匹配一些 uri 时,我们只知道他们是以什么什么开头的(区分大小写),后面的 uri 是一些可变参数
/api/v1/sms/{tel}/status
/api/v2/aisp/{user-id}/msg
等等这样的 uri 时
```
例子:实现上面类似的功能
### 结尾列表/结尾扩展列表
结尾列表,同样俗气的标记,就是匹配字符串的结尾,是个数组(数组中任意一个匹配成功,即匹配命中)
结尾扩展列表:仅仅是不区分大小写的结尾列表
```
当一些域名 他们是 前缀不一样,但是后面的字符串是完全一样的,就可以使用该匹配符进行匹配
www1.nginx.com
img.nginx.com
static.nginx.com
05c12a287334386c94131ab8aa00d08a.cdn.nginx.com
7d6006e64eb59bcf40d8f8f31ff94ea9.ds.nginx.com
在包含时出现的域名,同样也可以使用结尾列表匹配,且性能会高于 包含
```
举例子:
### 包含
比如一些情况下,等于不能进行很好的匹配,但是我们需要匹配的`host`都包含一些关键字,就可以使用 包含
```
www1.nginx.com
img.nginx.com
static.nginx.com
05c12a287334386c94131ab8aa00d08a.cdn.nginx.com
7d6006e64eb59bcf40d8f8f31ff94ea9.ds.nginx.com
...
比如我们需要匹配这些域名,这些都包含了`nginx.com`,那么就可以使用包含来匹配这些域名
```
举例子:
第二参数改成 in,第一个参数需要是字符串
### 多模匹配 (aho)
效果同包含列表,但是其性能是远远高于的,具体是使用了 aho 的算法,当匹配的字符串不是很多,很大时,可以不用该匹配方式
### 包含列表 / 包含扩展列表
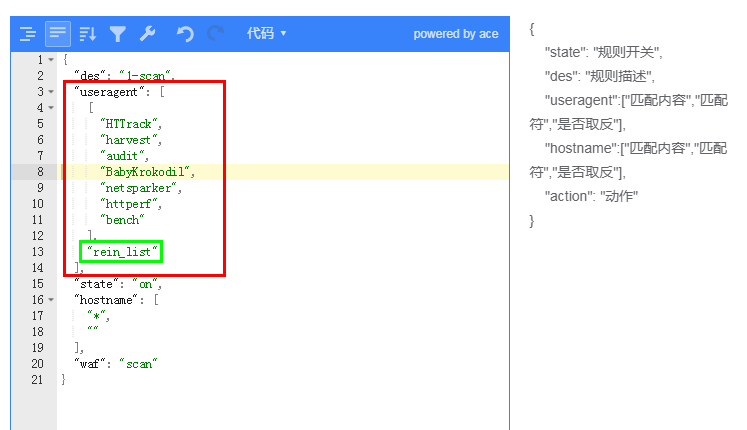
包含列表:包含的复数形式,当有多个字符串需要进行包含匹配时,是个数组(数组中任意一个匹配成功,即匹配命中)
包含扩展列表:仅仅是不区分大小写的包含列表
一些扫描器,攻击软件在`useragent`处有一些特征,就可以使用包含/包含扩展列表进行匹配
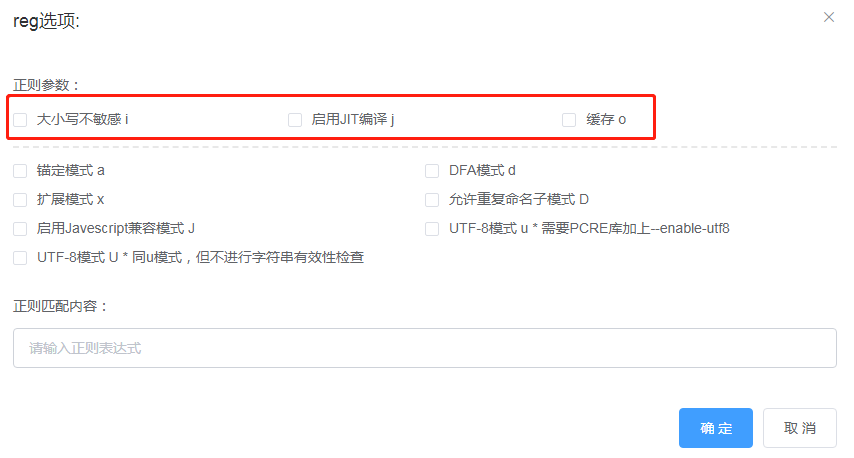
### 正则
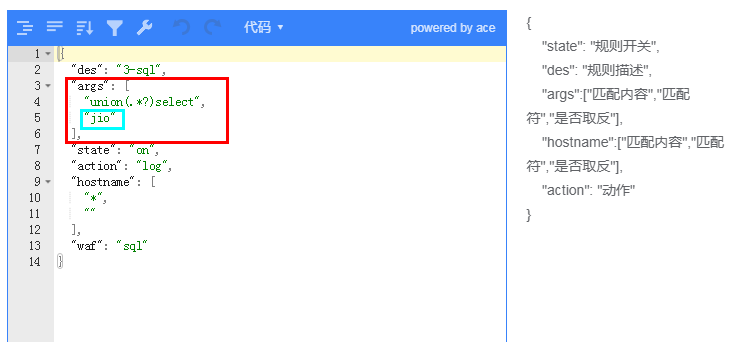
正则是匹配中使用比较多的地方, 但是正则写的不好,会对性能有非常大的影响,所以在前面就特别说明了,**能不用正则的就不用**。
正则匹配这里用到了 `luajit` 缓存 等一些优化特性,即便是这样,正则的使用一定要仔细,看几个例子吧
使用正则一定要进行匹配测试!!!
注:lujit 中特殊的优化特性(启用JIT、缓存),看一下使用正则时的参数的说明
### 长度
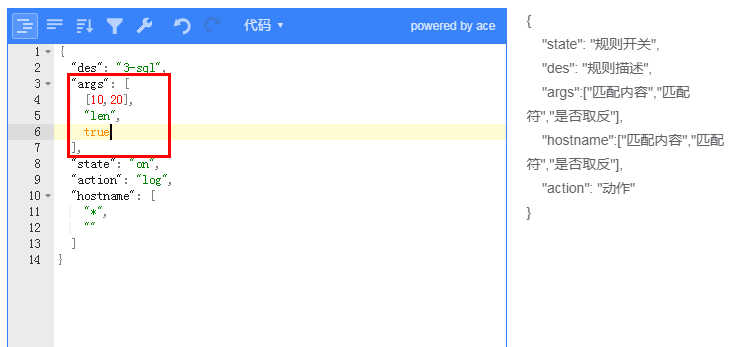
长度比较好理解就是对字符串的长度进行匹配
```
一些 GET 请求参数 我们可以进行长度的控制,比如 userid ,其长度是 我们开发人员约定生成的(18位数字)
那么就可以使用一定规则进行匹配,不符合就可以拦截
```
例子:限制了所有query_string参数的值长度只能是10-20,不在这个范围就都被拦截
### ip段
这里是ip段的匹配,用于匹配整个网段的ip
```
192.168.0.1/24 就可以匹配 ip 192.168.0.1 - 255
```
第二个参数为:cidr,第三个参数就是 tabel了
### token
token是特殊的匹配,token的匹配是WAF在内存中生成的一个随机字符串,匹配则是判断该字符串是否由WAF生成的,这样应用场景一般是一些防护CC攻击时使用
```
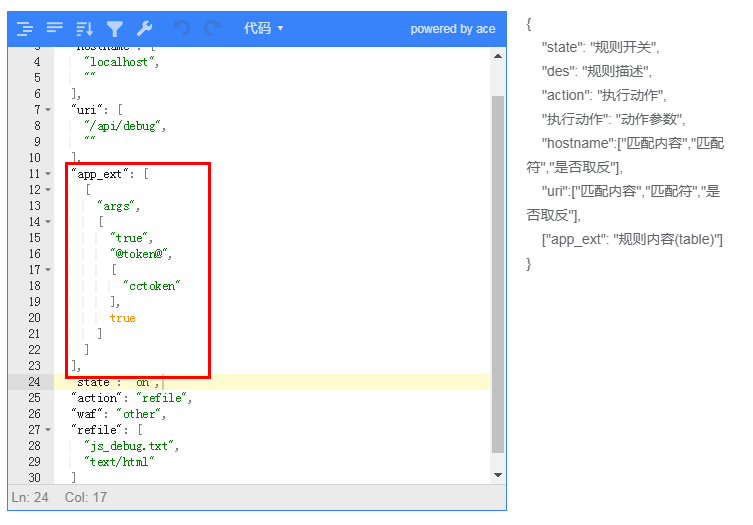
该条规则就是 访问 uri = /api/debug 时,我们进行 GET 参数(cctoken) 进行匹配,匹配失败则返回一个固定的文件内容
<html>
<head>
<script>
var Num="@token@";
var url = window.location.href;
var re = new RegExp("\\?","i");
var url = window.location.href;
if(re.test(url)){
window.location.href=url+"&cctoken="+Num;
}
else
{
window.location.href=url+"?&cctoken="+Num;
}
</script>
</head>
</html>
这是一个JS跳转,跳转的时候添加了一个 cctoken 的参数,其值为 @token@
注:WAF在返回 文件/字符串 时,会将 @token@ 替换为一个WAF 生成的随机字符串
这样配合 对参数 cctoken 进行 token 的检查,这样就可以实现一种 cc 防护了
```
- kcon 兵器谱
- 演示 1
- 演示 2
- 演示 3
- 演示 4
- 演示 5
- 前言
- 安装
- 更新
- 登录后台
- 授权认证
- 集群配置
- 7层防护 -- 最佳实践
- 匹配位置说明
- 匹配方式说明
- 规则匹配详解
- 全局 - CDN规则
- 添加header头配置
- 限速limit配置
- 缓存proxy_cache配置
- 清除缓存
- 全局 - 获取真实IP配置
- 全局 - IP黑白名单
- 全局 - 域名方法配置(白名单)
- 全局 - 跳转规则配置
- 全局 - 高级规则配置
- 全局 - 普通规则配置
- 全局 - 频率规则配置
- 全局 - 内容替换规则
- 内容替换规则(插件使用)
- 全局 - 拦截信息配置
- 全局 - LOG规则配置
- 平台配置
- 基本配置
- 高级配置
- 配置文件管理
- 4 层代理
- 转发配置
- 插件管理
- 防护配置
- 网站管理
- 证书管理
- 域名管理
- 网站规则
- 插件管理
- 插件操作 --- 基本使用
- 插件操作 --- 手机号脱敏插件
- 归档
- 更新日志
- 视频教程目录