[TOC]
# redis-spring-boot-starter
redis-spring-boot-starter 通过autoconfig微内核结合redis api提供了通用缓存能力。采用Redis官方推荐的Java版的Redis客户端Redisson提供了非常强大的功能,利用spring Cache与redis的扩展结合简化了缓存的使用难度。
## 序列化反序列化
* 在Java应用的开发中,需要将Java对象实例保存在Redis中,常用方法有两种:
1. 将对象序列化成字符串后存入Redis;
2. 将对象序列化成byte数组后存入Redis;
通过以上的用户情景,结合目前主流的序列化框架封装了一套平台统一的序列化方案。
### 测试脚本
~~~
public static void main(String[] args) {
Map map = new HashMap();
for (int i = 0; i <= 100; i++) {
map.put("a" + i, "a" + i);
}
Serializer jdkSerializer = SerializerManager.getSerializer(SerializerManager.JDK);
Serializer hessianSerializer = SerializerManager.getSerializer(SerializerManager.HESSIAN2);
Serializer fstObjectSerializer = SerializerManager.getSerializer(SerializerManager.FST);
Serializer snappyFstObjectSerializer = SerializerManager.getSerializer(SerializerManager.SNAPPY_FST);
long size = 0;
long time1 = System.currentTimeMillis();
byte[] jdkserialize = null;
byte[] redisserialize = null;
byte[] kryoserialize = null;
for (int i = 0; i < 1000000; i++) {
jdkserialize = jdkSerializer.serialize(map);
size += jdkserialize.length;
}
System.out.println("原生序列化方案[序列化100000次]耗时:" + (System.currentTimeMillis() - time1) + "ms size:=" + size);
long time2 = System.currentTimeMillis();
for (int i = 0; i < 1000000; i++) {
Map aa = (Map) jdkSerializer.deserialize(jdkserialize);
}
System.out.println("原生序列化方案[反序列化100000次]耗时:" + (System.currentTimeMillis() - time2) + "ms size:=" + size);
long time3 = System.currentTimeMillis();
size = 0;
for (int i = 0; i < 1000000; i++) {
redisserialize = hessianSerializer.serialize(map);
size += redisserialize.length;
}
System.out.println("hessian序列化方案[序列化100000次]耗时:" + (System.currentTimeMillis() - time3) + "ms size:=" + size);
long time4 = System.currentTimeMillis();
for (int i = 0; i < 1000000; i++) {
Map aa = (Map) hessianSerializer.deserialize(redisserialize);
}
System.out.println("hessian序列化方案[反序列化100000次]耗时:" + (System.currentTimeMillis() - time4) + "ms size:=" + size);
long time5 = System.currentTimeMillis();
size = 0;
for (int i = 0; i < 1000000; i++) {
kryoserialize = fstObjectSerializer.serialize(map);
size += kryoserialize.length;
}
System.out.println("fst序列化方案[序列化100000次]耗时:" + (System.currentTimeMillis() - time5) + "ms size:=" + size);
long time6 = System.currentTimeMillis();
for (int i = 0; i < 1000000; i++) {
Map aa = (Map) fstObjectSerializer.deserialize(kryoserialize);
}
System.out.println("fst序列化方案[反序列化100000次]耗时:" + (System.currentTimeMillis() - time6) + "ms size:=" + size);
long time7 = System.currentTimeMillis();
size = 0;
for (int i = 0; i < 1000000; i++) {
kryoserialize = snappyFstObjectSerializer.serialize(map);
size += kryoserialize.length;
}
System.out.println("SNAPPY fst序列化方案[序列化100000次]耗时:" + (System.currentTimeMillis() - time5) + "ms size:=" + size);
long time8 = System.currentTimeMillis();
for (int i = 0; i < 1000000; i++) {
Map aa = (Map) snappyFstObjectSerializer.deserialize(kryoserialize);
}
System.out.println("SNAPPY fst反序列化方案[反序列化100000次]耗时:" + (System.currentTimeMillis() - time8) + "ms size:=" + size);
}
~~~
### 结构报告
原生序列化方案[序列化100000次]耗时:15173ms size:=1276000000
原生序列化方案[反序列化100000次]耗时:18906ms size:=1276000000
hessian序列化方案[序列化100000次]耗时:11890ms size:=792000000
hessian序列化方案[反序列化100000次]耗时:6443ms size:=792000000
fst序列化方案[序列化100000次]耗时:4947ms size:=995000000
fst序列化方案[反序列化100000次]耗时:6757ms size:=995000000
SNAPPY fst序列化方案[序列化100000次]耗时:19161ms size:=491000000
SNAPPY fst反序列化方案[反序列化100000次]耗时:8159ms size:=491000000
## 分布式锁
### 过程:
redisson分布式锁实现细节:
* redisson所有指令都通过lua脚本执行,redis支持lua脚本原子性执行
* redisson设置一个key的默认过期时间为30s,如果某个客户端持有一个锁超过了30s怎么办? redisson中有一个watchdog的概念,翻译过来就是看门狗,它会在你获取锁之后,每隔10秒帮你把key的超时时间设为30s 这样的话,就算一直持有锁也不会出现key过期了,其他线程获取到锁的问题了。
* redisson的“看门狗”逻辑保证了没有死锁发生。 (如果机器宕机了,看门狗也就没了。此时就不会延长key的过期时间,到了30s之后就会自动过期了,其他线程可以获取到锁)
### 代码分析
* 获取锁
* 加锁
> 在RedissonLock对象的lock()方法主要调用tryAcquire()方法,由于leaseTime == -1,于是走tryLockInnerAsync()方法
* 加锁细节
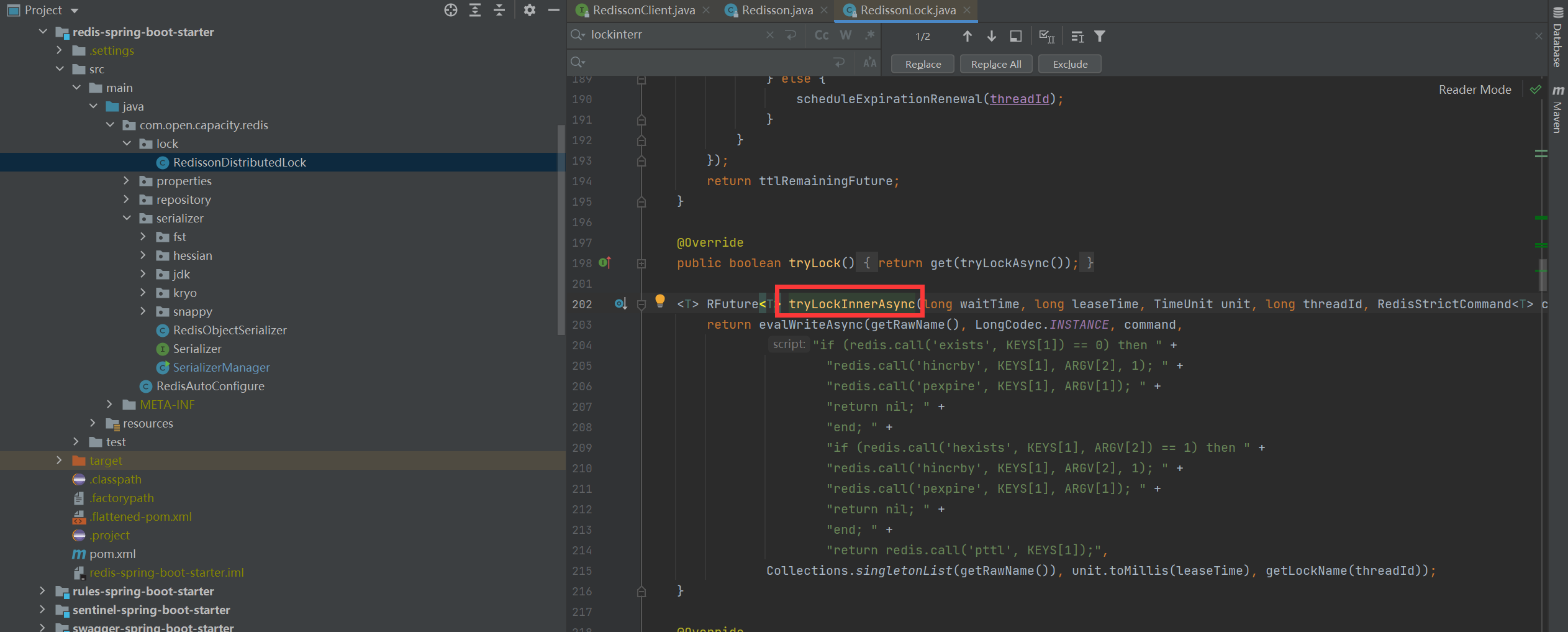
> 结合上面的参数声明,我们可以知道,这里KEYS\[1\]就是getName(),ARGV\[2\]是getLockName(threadId),假设前面获取锁时传的name是“anyLock”,假设调用的线程ID是Thread-1,假设成员变量UUID类型的id是85b196ce-e6f2-42ff-b3d7-6615b6748b5d:65那么KEYS\[1\]=anyLock,ARGV\[2\]=85b196ce-e6f2-42ff-b3d7-6615b6748b5d:Thread-1 ,因此,这段脚本的意思是1、判断有没有一个叫“anyLock”的key2、如果没有,则在其下设置一个字段为“85b196ce-e6f2-42ff-b3d7-6615b6748b5d:Thread-1”,值为“1”的键值对 ,并设置它的过期时间3、如果存在,则进一步判断“85b196ce-e6f2-42ff-b3d7-6615b6748b5d:Thread-1”是否存在,若存在,则其值加1,并重新设置过期时间4、返回“anyLock”的生存时间(毫秒)
* 加锁redis结构

> 这里用的数据结构是hash,hash的结构是: key 字段1 值1 字段2 值2 。。。用在锁这个场景下,key就表示锁的名称,也可以理解为临界资源,字段就表示当前获得锁的线程所有竞争这把锁的线程都要判断在这个key下有没有自己线程的字段,如果没有则不能获得锁,如果有,则相当于重入,字段值加1(次数)
* 解锁
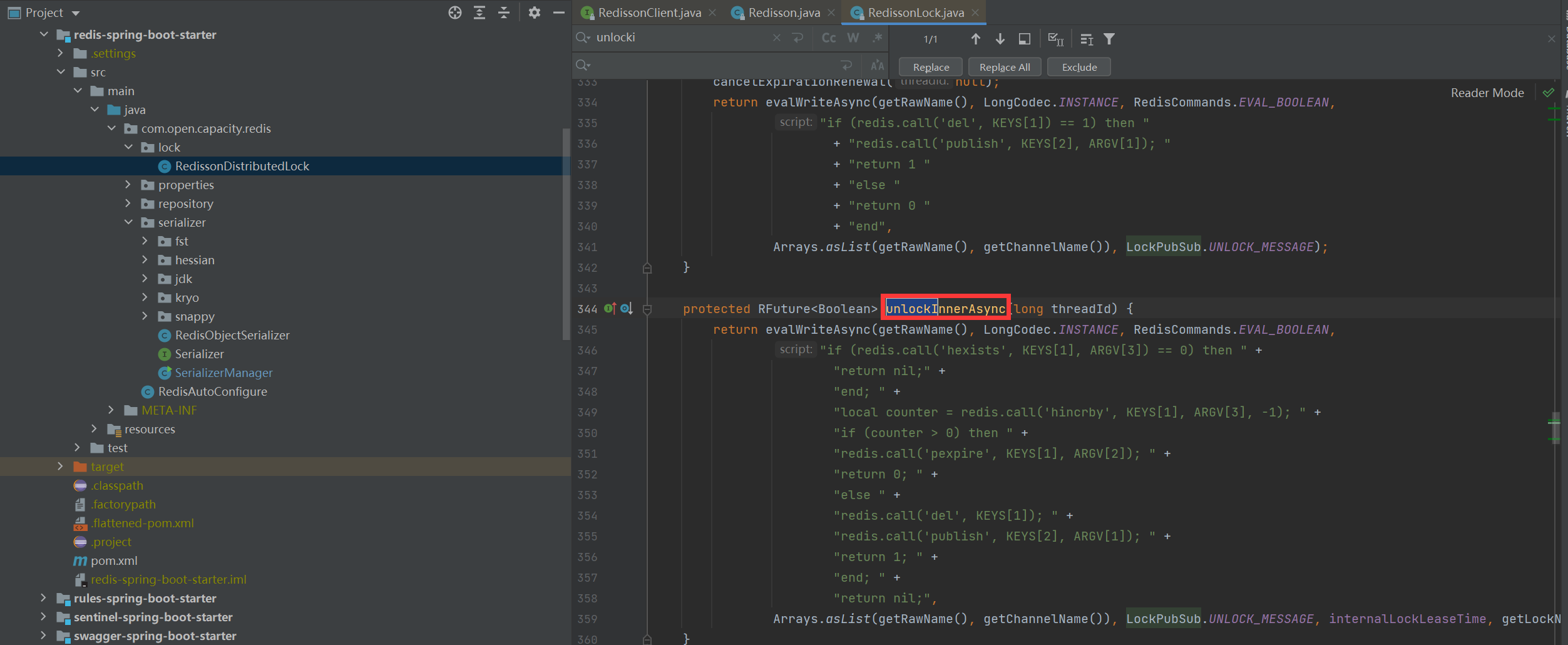
> 我们还是假设name=anyLock,假设线程ID是Thread-1,同理,我们可以知道KEYS\[1\]是getName(),即KEYS\[1\]=anyLock,KEYS\[2\]是getChannelName(),即KEYS\[2\]=redisson\_lock\_\_channel:{anyLock},ARGV\[1\]是LockPubSub.unlockMessage,即ARGV\[1\]=0,ARGV\[2\]是生存时间,ARGV\[3\]是getLockName(threadId),即ARGV\[3\]=85b196ce-e6f2-42ff-b3d7-6615b6748b5d:Thread-1,因此,上面脚本的意思是:1、判断是否存在一个叫“anyLock”的key2、如果不存在,向Channel中广播一条消息,广播的内容是0,并返回1。3、如果存在,进一步判断字段85b196ce-e6f2-42ff-b3d7-6615b6748b5d:Thread-1是否存在。4、若字段不存在,返回空,若字段存在,则字段值减1,5、若减完以后,字段值仍大于0,则返回0。6、减完后,若字段值小于或等于0,则广播一条消息,广播内容是0,并返回1;可以猜测,广播0表示资源可用,即通知那些等待获取锁的线程现在可以获得锁了
* 等待
```
~~~
private void lock(long leaseTime, TimeUnit unit, boolean interruptibly) throws InterruptedException {
long threadId = Thread.currentThread().getId();
Long ttl = tryAcquire(leaseTime, unit, threadId);
// lock acquired
if (ttl == null) {
return;
}
RFuture<RedissonLockEntry> future = subscribe(threadId);
if (interruptibly) {
commandExecutor.syncSubscriptionInterrupted(future);
} else {
commandExecutor.syncSubscription(future);
}
try {
while (true) {
ttl = tryAcquire(leaseTime, unit, threadId);
// lock acquired
if (ttl == null) {
break;
}
// waiting for message
if (ttl >= 0) {
try {
future.getNow().getLatch().tryAcquire(ttl, TimeUnit.MILLISECONDS);
} catch (InterruptedException e) {
if (interruptibly) {
throw e;
}
future.getNow().getLatch().tryAcquire(ttl, TimeUnit.MILLISECONDS);
}
} else {
if (interruptibly) {
future.getNow().getLatch().acquire();
} else {
future.getNow().getLatch().acquireUninterruptibly();
}
}
}
} finally {
unsubscribe(future, threadId);
}
// get(lockAsync(leaseTime, unit));
}
~~~
```
> 这里会订阅Channel,当资源可用时可以及时知道,并抢占,防止无效的轮询而浪费资源当资源可用用的时候,循环去尝试获取锁,由于多个线程同时去竞争资源,所以这里用了信号量,对于同一个资源只允许一个线程获得锁,其它的线程阻塞
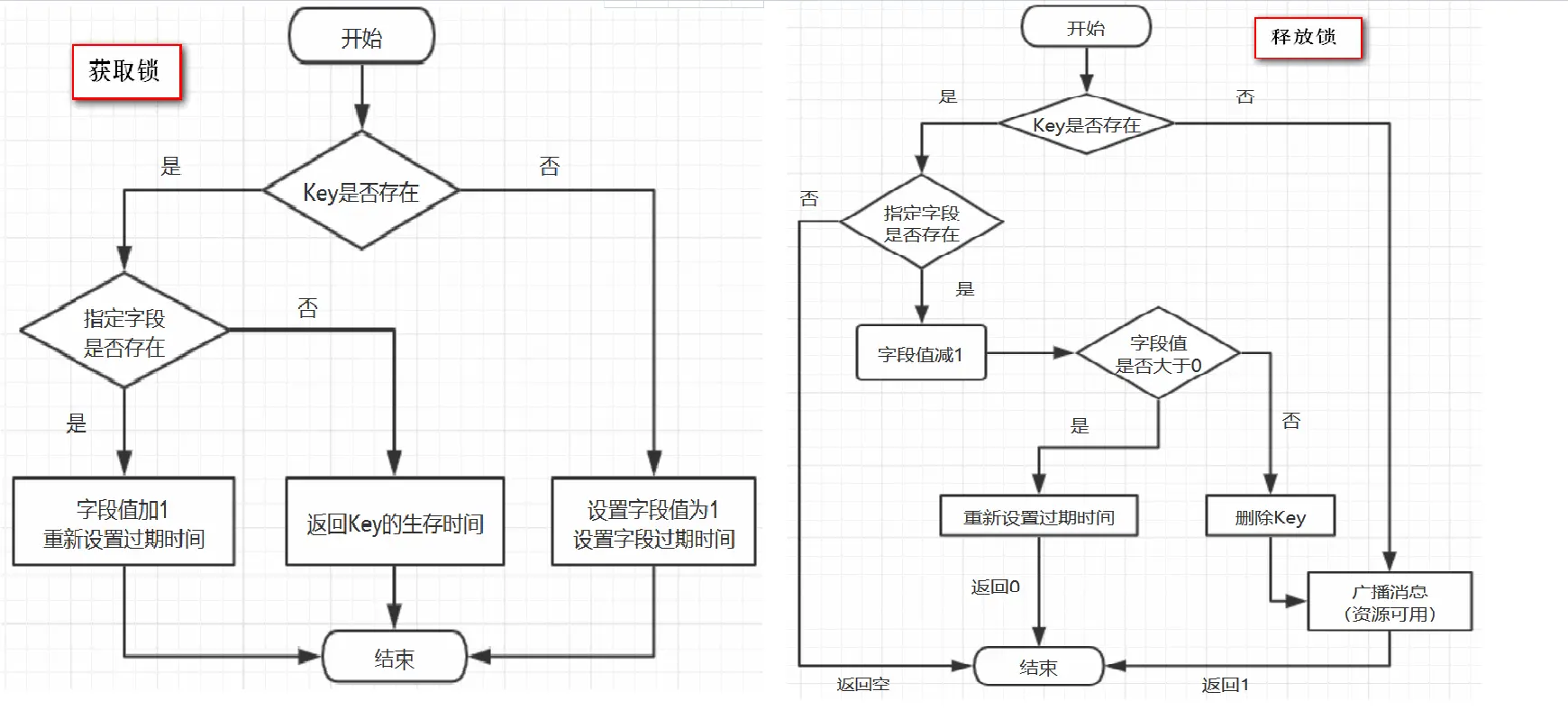
## Cache Aside Pattern
* 读的时候,先读缓存,缓存没有的话,那么就读数据库,然后取出数据后放入缓存,同时返回响应
* 更新的时候,先删除缓存,然后再更新数据库
## Redis和Spring Cache整合
### 配置类
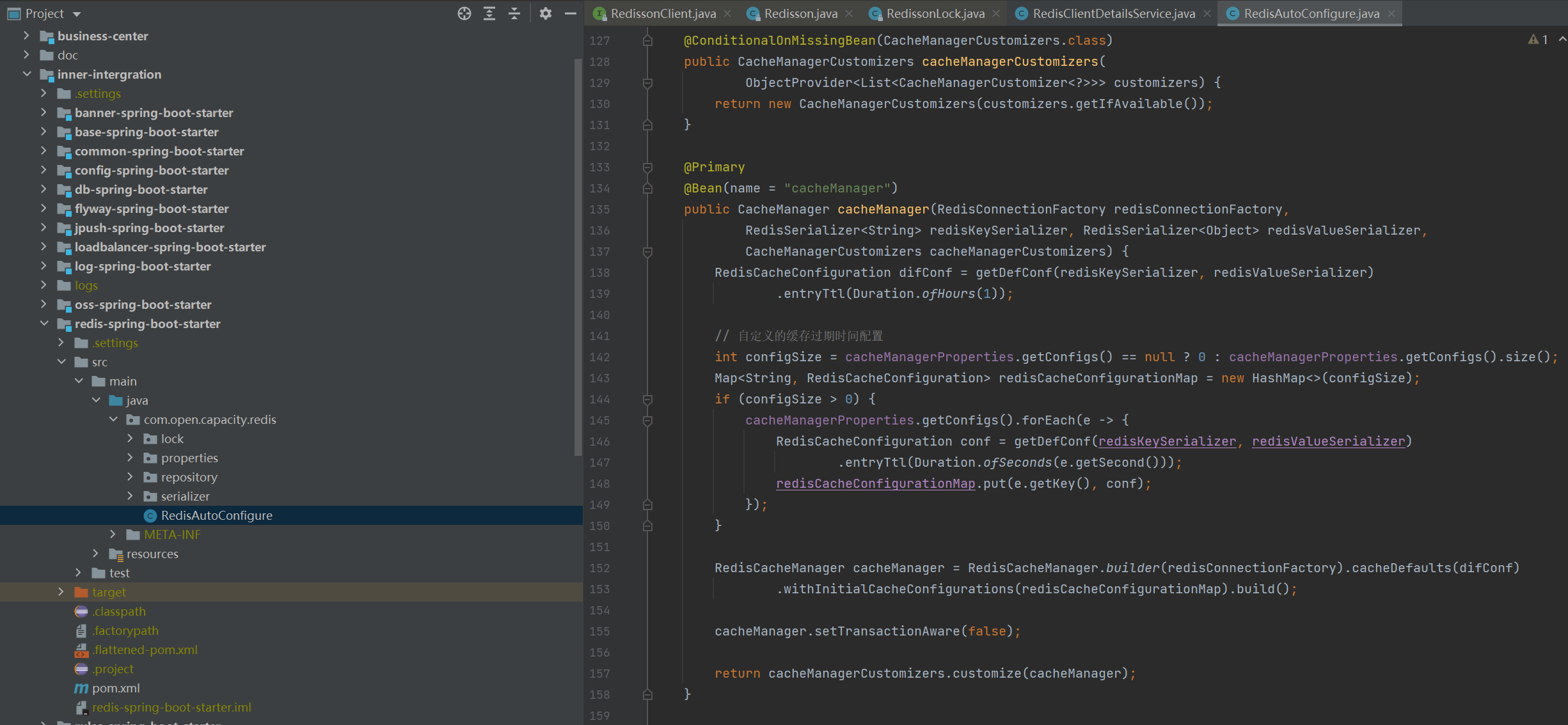
### 缓存key配置
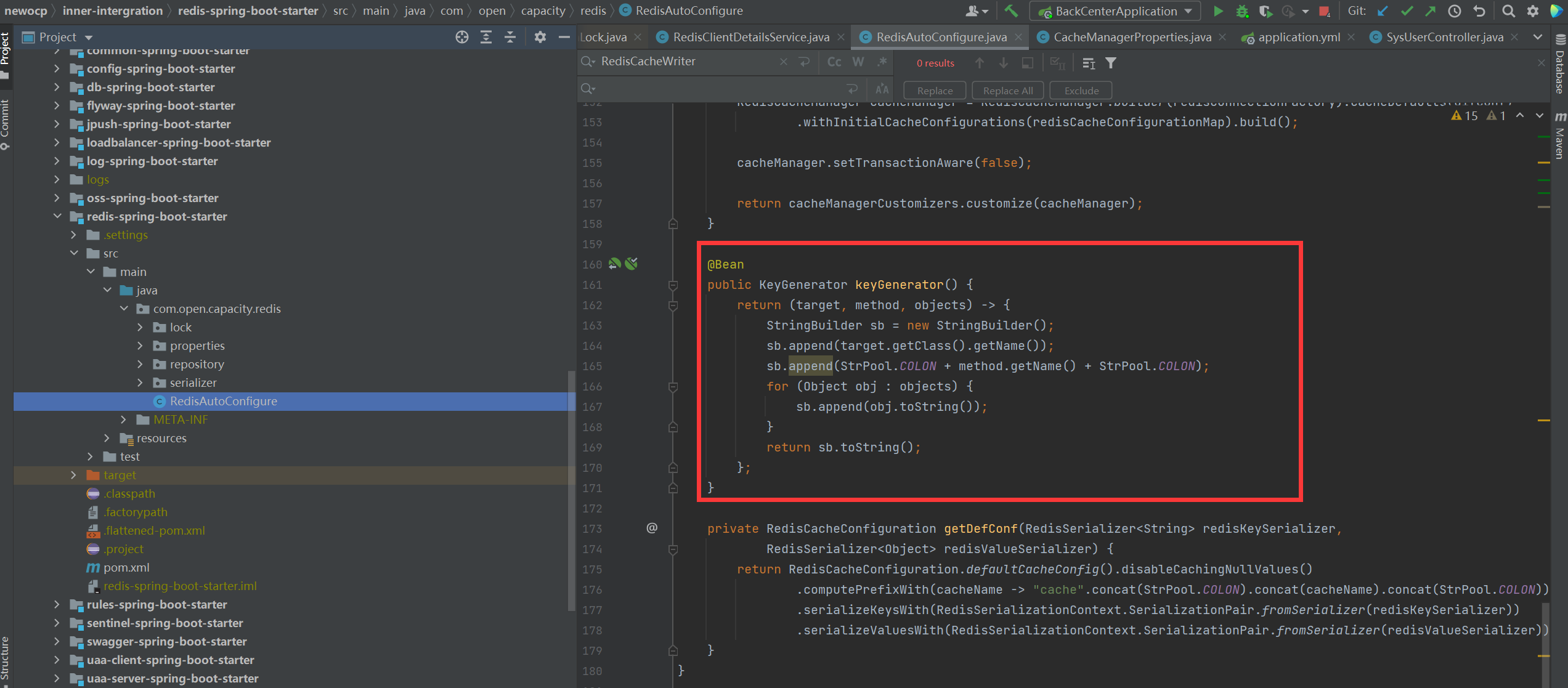
### 配置文件
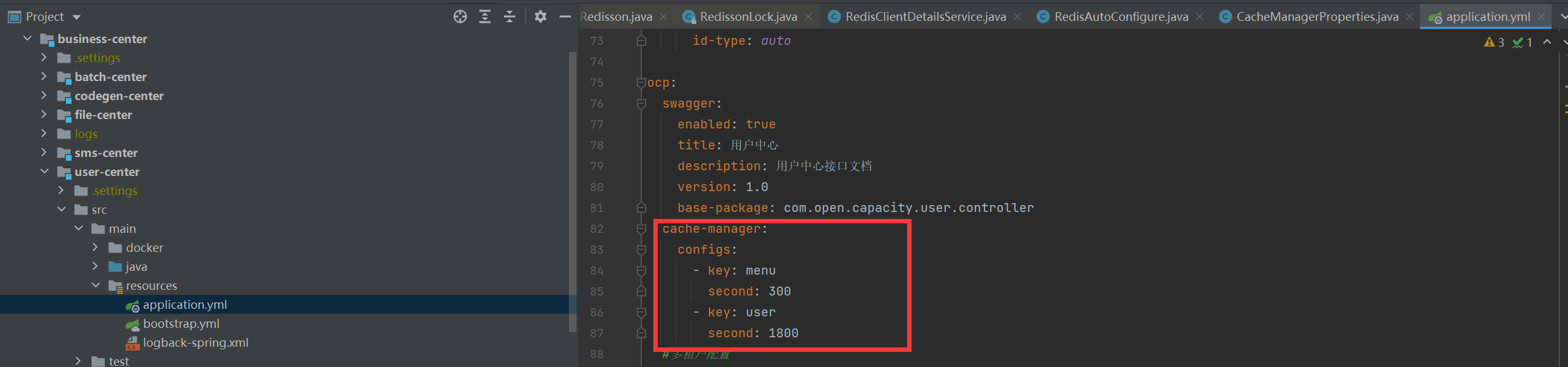
### 使用方式
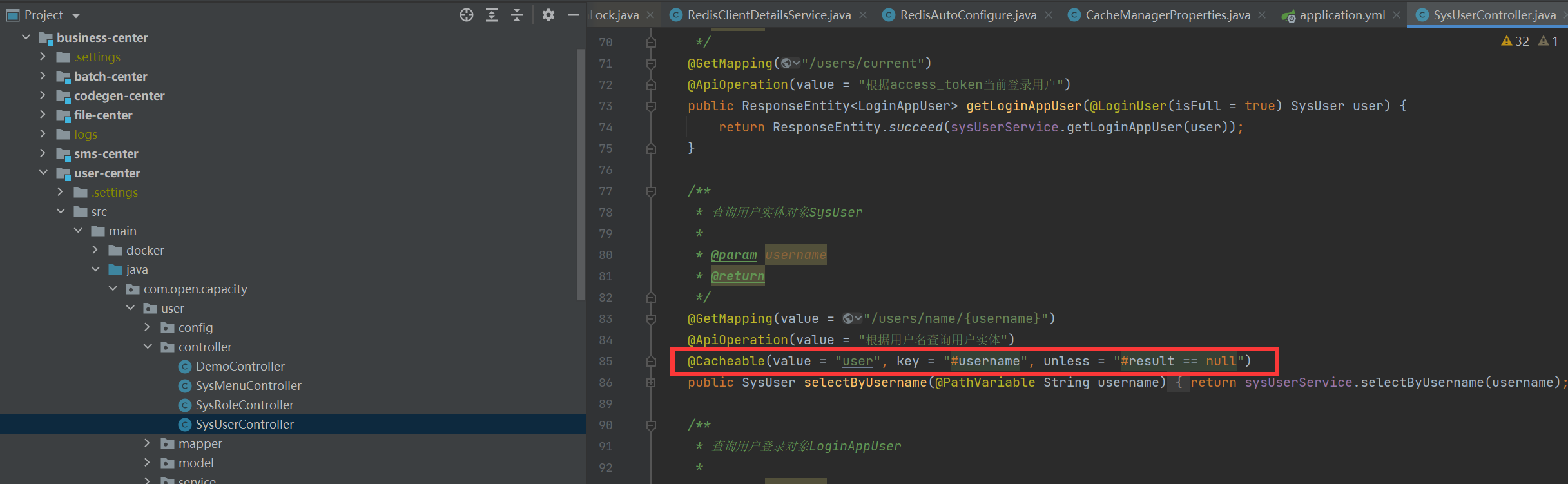
## geohash 经纬度定位
在开发疫情地图时,我们常常需要进行经纬度定位,查询该地区附近多少公里有多少疫情,此时我们需要采用geohash方式进行经纬度定位。
```
/**
* 添加经纬度信息 map.put("北京" ,new Point(116.405285 ,39.904989)) //redis 命令:geoadd
* cityGeo 116.405285 39.904989 "北京"
*/
public Long addGeoPoint(String key, Map<Object, Point> map) {
return redisTemplate.opsForGeo().add(key, map);
}
/**
* 查找指定key的经纬度信息 redis命令:geopos cityGeo 北京
*
* @param key
* @param member
* @return
*/
public Point geoGetPoint(String key, String member) {
List<Point> lists = redisTemplate.opsForGeo().position(key, member);
return lists.get(0);
}
/**
* 返回两个地方的距离,可以指定单位 redis命令:geodist cityGeo 北京 上海
*
* @param key
* @param srcMember
* @param targetMember
* @return
*/
public Distance geoDistance(String key, String srcMember, String targetMember) {
Distance distance = redisTemplate.opsForGeo().distance(key, srcMember, targetMember, Metrics.KILOMETERS);
return distance;
}
/**
* 根据指定的地点查询半径在指定范围内的位置 redis命令:georadiusbymember cityGeo 北京 100 km WITHDIST
* WITHCOORD ASC COUNT 5
*
* @param key
* @param member
* @param distance
* @return
*/
public GeoResults geoRadiusByMember(String key, String member, double distance) {
return redisTemplate.opsForGeo().radius(key, member, new Distance(distance, Metrics.KILOMETERS));
}
/**
* 根据给定的经纬度,返回半径不超过指定距离的元素 redis命令:georadius cityGeo 116.405285 39.904989 100 km
* WITHDIST WITHCOORD ASC COUNT 5
*
* @param key
* @param circle
* @param distance
* @return
*/
public GeoResults geoRadiusByCircle(String key, Circle circle, double distance) {
return redisTemplate.opsForGeo().radius(key, circle, new Distance(distance, Metrics.KILOMETERS));
}
```
## redis cluster的优化
采用Redisson 方式支持Redis集群模式解决了以下问题:
* 自动发现主从节点
* 自动更新状态和组态拓扑
* 自动发现槽的变化
项目中 3主3从 redis集群出现单节点宕机,造成master迁移,但是发现应用无法正常连接redis ,分析了代码,发现默认Lettuce是不会刷新拓扑io.lettuce.core.cluster.models.partitions.Partitions#slotCache,最终造成槽点查找节点依旧找到老的节点,自然访问不了了,采用平台方式解决了以上问题,避免了在redis cluster集群中的一些bug。
- 01.前言
- 02.快速开始
- 01.maven构建项目
- 02.安装mysql数据库
- 03.安装redis缓存中间件
- 04.快速启动框架
- 03.总体流程
- 01.架构设计图
- 02.oauth接口
- 03.功能介绍
- 04.部署细节
- 04.模块详解
- 01.基础介绍
- 02.自定义db-spring-boot-starter
- 03.自定义log-spring-boot-starter
- 04.自定义redis-spring-boot-starter
- 05.自定义base-spring-boot-starter
- 06.自定义common-spring-boot-starter
- 07.自定义loadbalancer-spring-boot-starter
- 08.自定义swagger-spring-boot-starter
- 09.自定义uaa-client-spring-boot-starter
- 10.自定义uaa-server-spring-boot-starter
- 11.自定义oss-spring-boot-starter
- 12.自定义sentinel-spring-boot-starter
- 05.服务详解
- 01.nacos-server
- 02.auth-server
- 03.user-center
- 04.new-api-gateway
- 05.file-center
- 06.log-center
- 07.back-center
- 08.auth-sso模块
- 09.admin-server
- 10.job-center
- 06.系统安全
- 01.非法字符漏洞攻击
- 02.防重放攻击
- 03.代码审计
- 04.Xray扫洞
- 05.混沌工程质量保证
- 07.生产部署K8S
- 01.基本环境安装
- 02.基本组件安装
- 03.集群验证
- 04.安装Metrics Server
- 05.安装容器平台
- 06.Ingress网关
- 07.metalb负载均衡器
- 08.容器平台集群
- 08.K8S资源练习
- 01.Deployment
- 02.StatefulSet
- 03.DaemonSet
- 04.redis集群服务
- 05.elasticsearch集群
- 06.rocketmq部署
- 09.生产容器化部署
- 01.nacos集群部署
- 02.user-center服务
- 03.auth-server服务
- 04.new-api-gateway服务
- 技术交流