
如题,近两天遇到此类错误,发现goroutine以及channel的基础仍需巩固。由该错误牵引出go相关并发操作的问题,下面做一些简单的tips操作和记录。
```
func hello() {
fmt.Println("Hello Goroutine!")
}
func main() {
go hello() // 启动另外一个goroutine去执行hello函数
fmt.Println("main goroutine done!")
}
```
1、在程序启动时,Go程序就会为main()函数创建一个默认的goroutine。当main()函数返回的时候该goroutine就结束了,所有在main()函数中启动的goroutine会一同结束!
所以引出sync.WaitGroup的使用。通过它,可以实现goroutine的同步。
```
var wg sync.WaitGroup
func hello(i int) {
defer wg.Done() // goroutine结束就登记-1
fmt.Println("Hello Goroutine!", i)
}
func main() {
for i := 0; i < 10; i++ {
wg.Add(1) // 启动一个goroutine就登记+1
go hello(i)
}
wg.Wait() // 等待所有登记的goroutine都结束
}
```
2、单纯地将函数并发执行是没有意义的。函数与函数间需要交换数据才能体现并发执行函数的意义。如果说goroutine是Go程序并发的执行体,channel就是它们之间的连接。channel是可以让一个goroutine发送特定值到另一个goroutine的通信机制。Go 语言中的通道(channel)是一种特殊的类型。通道像一个传送带或者队列,总是遵循先入先出(First In First Out)的规则,保证收发数据的顺序。每一个通道都是一个具体类型的导管,也就是声明channel的时候需要为其指定元素类型。
通道有发送(send)、接收(receive)和关闭(close)三种操作。
发送和接收都使用<-符号。我们通过调用内置的close函数来关闭通道。
关闭后的通道有以下特点:
对一个关闭的通道再发送值就会导致panic。
对一个关闭的通道进行接收会一直获取值直到通道为空。
对一个关闭的并且没有值的通道执行接收操作会得到对应类型的零值。
关闭一个已经关闭的通道会导致panic。
无缓冲的通道又称为阻塞的通道:
```
func main() {
ch := make(chan int)
ch <- 10
fmt.Println("发送成功")
}
```
上面这段代码能够通过编译,但是执行的时候会出现以下错误:
```
fatal error: all goroutines are asleep - deadlock!
goroutine 1 [chan send]:
main.main()
```
们使用`ch := make(chan int)`创建的是**无缓冲的通道**,无缓冲的通道只有在有人接收值的时候才能发送值。
上面的代码会阻塞在`ch <- 10`这一行代码形成[死锁](https://so.csdn.net/so/search?q=%E6%AD%BB%E9%94%81&spm=1001.2101.3001.7020),那如何解决这个问题呢?
一种方法是启用一个`goroutine`去接收值,并一种方式是使用带缓冲的通道,例如:
```
package main
// 方式1
func recv(c chan int) {
ret := <-c
fmt.Println("接收成功", ret)
}
func main() {
ch := make(chan int)
go recv(ch) // 启用goroutine从通道接收值
ch <- 10
fmt.Println("发送成功")
}
// 方式2
func main() {
ch := make(chan int,1)
ch<-1
println(<-ch)
}
```
但是注意:channel 通道增加缓存区后,可将数据暂存到缓冲区,而不需要接收端同时接收 (缓冲区如果超出大小同样会造成死锁)

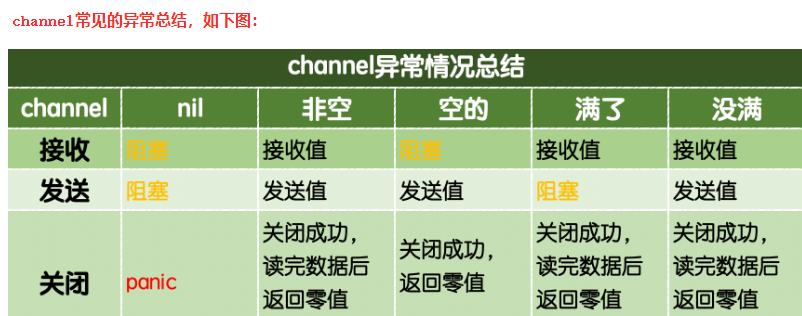
如图,总结,可以看出,产生阻塞的方式,主要容易踩坑的有两种:空的通道一直接收会阻塞;满的通道一直发送也会阻塞!
3、那么,如何解决阻塞死锁问题呢?
1)、如果是上面的无缓冲通道,使用再起一个协程的方式,可使得接收端和发送端并行执行。
2)、可以初始化时就给channel增加缓冲区,也就是使用有缓冲的通道
3)、易踩坑点,针对有缓冲的通道,产生阻塞,如何解决?
如下面例子,开启多个goroutine并发执行任务,并将数据存入管道channel,后续读取数据:
```
package main
import (
"fmt"
"sync"
"time"
)
func request(index int,ch chan<- string) {
time.Sleep(time.Duration(index)*time.Second)
s := fmt.Sprintf("编号%d完成",index)
ch <- s
}
func main() {
ch := make(chan string, 10)
fmt.Println(ch,len(ch))
for i := 0; i < 4; i++ {
go request(i, ch)
}
for ret := range ch{
fmt.Println(len(ch))
fmt.Println(ret)
}
}
```

**不可靠的解决方式如下:**
```
for {
i, ok := <-ch // 通道关闭后再取值ok=false;通道为空去接收,会发生阻塞死锁
if !ok {
break
}
println(i)
}
```
```
for ret := range ch{
fmt.Println(len(ch))
fmt.Println(ret) //通道为空去接收,会发生阻塞死锁
}
```
**以上两种从通道获取方式,都有小坑! 一旦获取的通道没有主动close(ch)关闭,而且通道为空时,无论通过for还是foreach方式去取值获取,都会产生阻塞死锁deadlock chan receive错误! **
**可靠的解决方式1 如下:**
```
package main
import (
"fmt"
"sync"
"time"
)
var wg sync.WaitGroup
func request(index int,ch chan<- string) {
time.Sleep(time.Duration(index)*time.Second)
s := fmt.Sprintf("编号%d完成",index)
ch <- s
defer wg.Done()
}
func main() {
ch := make(chan string, 10)
go func() {
wg.Wait()
close(ch)
}()
for i := 0; i < 4; i++ {
wg.Add(1)
go request(i, ch)
}
for ret := range ch{
fmt.Println(len(ch))
fmt.Println(ret)
}
}
```
解决方式: 即我们在生成完4个goroutine后对data channel进行关闭,这样通过for range从通道循环取出全部值,通道关闭就会退出for range循环。
具体实现:可以利用sync.WaitGroup解决,在所有的 data channel 的输入处理之前,wg.Wait()这个goroutine会处于等待状态(wg.Wait()源码就是for循环)。当执行方法处理完后(wg.Done),wg.Wait()就会放开执行,执行后面的close(ch)。
可靠的解决方式2 如下:
```
package main
import (
"fmt"
"time"
)
func request(index int,ch chan<- string) {
time.Sleep(time.Duration(index)*time.Second)
s := fmt.Sprintf("编号%d完成",index)
ch <- s
}
func main() {
ch := make(chan string, 10)
for i := 0; i < 4; i++ {
go request(i, ch)
}
for {
select {
case i := <-ch: // select会一直等待,直到某个case的通信操作完成时,就会执行case分支对应的语句
println(i)
default:
time.Sleep(time.Second)
fmt.Println("无数据")
}
}
}
```
上面这种方式获取,通过select case + default的方式也可以完美避免阻塞死锁报错!但是适用于通道不关闭,需要时刻循环执行数据并且处理的情境下。
4、由此,引入了select多路复用的使用
在某些场景下我们需要同时从多个通道接收数据。通道在接收数据时,如果没有数据可以接收将会发生阻塞。select的使用类似于switch语句,它有一系列case分支和一个默认的分支。每个case会对应一个通道的通信(接收或发送)过程。select会一直等待,直到某个case的通信操作完成时,就会执行case分支对应的语句。具体格式如下:
```
select{
case <-ch1:
...
case data := <-ch2:
...
case ch3<-data:
...
default:
默认操作
}
```
一定留意,default的作用很大! 是避免阻塞的核心。
使用select语句能提高代码的可读性。
可处理一个或多个channel的发送/接收操作。
如果多个case同时满足,select会随机选择一个。
对于没有case的select{}会一直等待,可用于阻塞main函数。
5、实际项目中goroutine+channel+select的使用
如下,使用于 项目监听终端中断信号操作:
```
srv := http.Server{
Addr: setting.AppConf.Http.Addr,
Handler: routers.SetupRouter(setting.AppConf),
}
go func() {
// 开启一个goroutine启动服务
if err := srv.ListenAndServe(); err != nil {
zap.S().Errorf("listen finish err: %s addr: %s", err, setting.AppConf.Http.Addr)
}
}()
// 等待中断信号来优雅地关闭服务器,为关闭服务器操作设置一个5秒的超时
sig := make(chan os.Signal, 1)
signal.Notify(sig, syscall.SIGINT, syscall.SIGTERM, syscall.SIGQUIT)
for {
select {
case s := <-sig:
zap.S().Infof("recv exit signal: %s", s.String())
ctx, cancel := context.WithTimeout(context.Background(), 5*time.Second)
defer cancel()
// 5秒内优雅关闭服务(将未处理完的请求处理完再关闭服务),超过5秒就超时退出
if err := srv.Shutdown(ctx); err != nil {
zap.S().Fatal("Server Shutdown err: ", err)
}
zap.S().Info("Server Shutdown Success")
return
}
}
```
如下,使用于**项目通过通道来进行数据处理、数据发送接收等操作**:
```
package taillog
// 专门从日志文件,收集日志
import (
"context"
"fmt"
"github.com/hpcloud/tail"
"logagent/kafka"
)
//var (
// tailObj *tail.Tail
//)
//TailTask 一个日志收集的任务
type TailTask struct {
path string
topic string
instance *tail.Tail
//为了能实现退出t.run
ctx context.Context
cancelFunc context.CancelFunc
}
func NewTailTask(path,topic string) (tailObj *TailTask) {
ctx,cancel := context.WithCancel(context.Background())
tailObj = &TailTask{
path:path,
topic:topic,
ctx:ctx,
cancelFunc:cancel,
}
tailObj.init() //根据路径去打开对应的日志
return
}
func (t *TailTask)init() {
config := tail.Config{
ReOpen: true, //重新打开
Follow: true, //是否跟随
Location: &tail.SeekInfo{Offset:0,Whence:2}, //从文件哪个地方开始读
MustExist: false, //文件不存在不报错
Poll: true,
}
var err error
t.instance, err = tail.TailFile(t.path, config)
if err != nil {
fmt.Println("tail file failed,err:",err)
}
// 当goroutine执行的函数退出的时候,goroutine结束
go t.run() //直接去采集日志,发送到kafka
}
func (t *TailTask)run() {
for{
select {
case <- t.ctx.Done():
fmt.Printf("tail task:%s_%s 结束了\n",t.path,t.topic)
return
case line := <- t.instance.Lines: //从tailObj一行行读取数据
//发往kafka
//kafka.SendToKafka(t.topic,line.Text) //函数调用函数
// 优化,先把日志数据发送到一个通道中
// kafka包中有单独的goroutine去取日志发送到kafka
kafka.SendToChan(t.topic,line.Text)
}
}
}
```
```
package kafka
//专门从kafka写日志
import (
"fmt"
"github.com/Shopify/sarama"
"time"
)
type logData struct {
topic string
data string
}
var (
client sarama.SyncProducer //声明一个全局连接kafka的生产者client
logDataChan chan *logData
)
// 初始化client
func Init(address []string, maxSize int)(err error) {
config := sarama.NewConfig()
config.Producer.RequiredAcks = sarama.WaitForAll //发送完数据需要leader和follow都确认
config.Producer.Partitioner = sarama.NewRandomPartitioner //新选出一个partition
config.Producer.Return.Successes = true //成功交付的消息将在success channel 返回
//连接kafka
client,err = sarama.NewSyncProducer(address,config)
if err != nil {
fmt.Println("producer closed,err:",err)
return
}
// 初始化logDataChan
logDataChan = make(chan *logData,maxSize)
// 开启后台的goroutine从通道取数据,发送kafka
go sendToKafka()
return
}
// 给外部暴漏一个函数,该函数只把日志数据发送到一个内部chan中
func SendToChan(topic,data string) {
msg := &logData{
topic: topic,
data: data,
}
logDataChan <- msg
}
//真正往kafka发送日志的函数
func sendToKafka() {
for{
select {
case ld := <- logDataChan:
// 构造一个消息
msg := &sarama.ProducerMessage{}
msg.Topic = ld.topic
msg.Value = sarama.StringEncoder(ld.data)
// 发送到kafka
pid,offset,err := client.SendMessage(msg)
if err != nil {
fmt.Println("send msg failed,err:",err)
return
}
fmt.Printf("pid:%v,offset:%v\n",pid,offset)
default:
time.Sleep(time.Microsecond*50)
}
}
}
```
- Golang
- Beego框架
- Gin框架
- gin框架介绍
- 使用Gin web框架的知名开源线上项目
- go-admin-gin
- air 热启动
- 完整的form表单参数验证语法
- Go 语言入门练手项目推荐
- Golang是基于多线程模型
- golang 一些概念
- Golang程序开发注意事项
- fatal error: all goroutines are asleep - deadlock
- defer
- Golang 的内建调试器
- go部署
- golang指针重要性
- 包(golang)
- Golang框架选型比较: goframe, beego, iris和gin
- GoFrame
- golang-admin-项目
- go module的使用方法及原理
- go-admin支持多框架的后台系统(go-admin.cn)
- docker gocv
- go-fac
- MSYS2
- 企业开发框架系统推荐
- gorm
- go-zero
- 优秀系统
- GinSkeleton(gin web 及gin 知识)
- 一次 request -> response 的生命周期概述
- 路由与路由组以及gin源码学习
- 中间件以及gin源码学习
- golang项目部署
- 独立部署golang
- 代理部署golang
- 容器部署golang
- golang交叉编译
- goravel
- kardianos+gin 项目作为windows服务运行
- go env
- 适用在Windows、Linux和macOS环境下打包Go应用程序的详细步骤和命令
- Redis
- Dochub
- Docker部署开发go环境
- Docker部署运行go环境
- dochub说明
- Vue
- i18n
- vue3
- vue3基本知识
- element-plus 表格单选
- vue3后台模板
- Thinkphp
- Casbin权限控制中间件
- 容器、依赖注入、门面、事件、中间件
- tp6问答
- 伪静态
- thinkphp-queue
- think-throttle
- thinkphp队列queue的一些使用说明,queue:work和queue:listen的区别
- ThinkPHP6之模型事件的触发条件
- thinkphp-swoole
- save、update、insert 的区别
- Socket
- workerman
- 介绍
- 从ThinkPHP6移植到Webman的一些技术和经验(干货)
- swoole
- swoole介绍
- hyperf
- hf官网
- Swoft
- swoft官网
- easyswoole
- easyswoole官网地址
- EASYSWOOLE 聊天室DEMO
- socket问答
- MySQL
- 聚簇索引与非聚簇索引
- Mysql使用max获取最大值细节
- 主从复制
- 随机生成20万User表的数据
- MySQL进阶-----前缀索引、单例与联合索引
- PHP
- 面向切面编程AOP
- php是单线程的一定程度上也可以看成是“多线程”
- PHP 线程,进程、并发、并行 的理解
- excel数据画表格图片
- php第三方包
- monolog/monolog
- league/glide
- 博客-知识网站
- php 常用bc函数
- PHP知识点的应用场景
- AOP(面向切面编程)
- 注解
- 依赖注入
- 事件机制
- phpspreadsheet导出数据和图片到excel
- Hyperf
- mineAdmin
- 微服务
- nacos注册服务
- simps-mqtt连接客户端simps
- Linux
- 切换php版本
- Vim
- Laravel
- RabbitMQ
- thinkphp+rabbitmq
- 博客
- Webman框架
- 框架注意问题
- 关于内存泄漏
- 移动端自动化
- 懒人精灵
- 工具应用
- render
- gitlab Sourcetree
- ssh-agent失败 错误代码-1
- 资源网站
- Git
- wkhtmltopdf
- MSYS2 介绍
- powershell curl 使用教程
- NSSM(windows服务工具)
- MinGW64
- 知识扩展
- 对象存储系统
- minio
- 雪花ID
- 请求body参数类型
- GraphQL
- js 深拷贝
- window 共享 centos文件夹
- 前端get/post 请求 特殊符号 “+”传参数问题
- 什么是SCM系统?SCM系统与ERP系统有什么区别?
- nginx 日志格式统一为 json
- 特殊符号怎么打
- 收藏网址
- 收藏-golang
- 收藏-vue3
- 收藏-php
- 收藏-node
- 收藏-前端
- 规划ITEM
- 旅游类
- 人脸识别
- dlib
- Docker&&部署
- Docker-compose
- Docker的网络模式
- rancher
- DHorse
- Elasticsearch
- es与kibana都docke连接
- 4种数据同步到Elasticsearch方案
- GPT
- 推荐系统
- fastposter海报生成
- elasticsearch+logstash+kibana
- beego文档系统-MinDoc
- jeecg开源平台
- Java
- 打包部署
- spring boot
- 依赖
- Maven 相关 命令
- Gradle 相关命令
- mybatis
- mybatis.plus
- spring boot 模板引擎
- SpringBoot+Maven多模块项目(创建、依赖、打包可执行jar包部署测试)完整流程
- Spring Cloud
- Sentinel
- nacos
- Apollo
- java推荐项目
- gradle
- Maven
- Nexus仓库管理器
- Python
- Masonite框架
- scrapy
- Python2的pip2
- Python3 安装 pip3
- 安全攻防
- 运维技术
- 腾讯云安全加固建议
- 免费freessl证书申请
- ruby
- homeland
- Protobuf
- GIT
- FFMPEG
- 命令说明
- 音频
- ffmpeg合并多个MP4视频
- NODEJS
- 开发npm包
- MongoDB
- php-docker-mongodb环境搭建
- mongo基本命令
- Docker安装MongoDB最新版并连接
- 少儿编程官网
- UI推荐
- MQTT
- PHP连接mqtt
- EMQX服务端
- php搭建mqtt服务端