
三范式?
* 第一范式:确保每列保持原子性,数据表中的所有字段值都是不可分解的原子值。
* 第二范式:确保表中的每列都和主键相关
* 第三范式:确保每列都和主键列直接相关而不是间接相关
什么是索引?
官方: 本质是一种数据结构, 是帮助MySQL高效获取数据的数据结构
是排好序的快速查找数据结构
索引的优劣?
1. 优势
1. 提高数据检索效率,降低数据库的IO成本
2. 降低数据排序成本,降低了CPU的消耗
3. 劣势
* 实际上索引也是一张表,该表保存了主键和索引字段,并指向实体表的记录,所以索引列也是要占用空间的
* 因为更新表时,MySQL不仅要不存数据,还要保存一下索引文件每次更新添加了索引列的字段,都会调整因为更新所带来的键值变化后的索引信息
* 索引只是提高效率的一个因素,如果你的MySQL有大数据量的表,就需要花时间研究建立优秀的索引,或优化查询语句
索引分类?
1. 普通索引 基本的索引类型,可以为NULL
2. 主键索引 数据列不允许重复,不能为NULL,一个表只能有一个主键索引
3. 唯一索引 数据列必须唯一,但允许有空值
4. 复合索引 即一个索引包含多个列
覆盖索引+回表+索引下推?
* 覆盖索引:索引字段覆盖了查询语句涉及的字段,直接通过索引文件就可以返回查询所需的数据,不必通过回表操作。
* 回表:通过索引找到主键,再根据主键id去主键索引查数据。
* 索引下推:在根据索引查询过程中就根据查询条件过滤掉一些记录,减少最后的回表操作
什么是聚簇索引,什么是非聚簇索引?
聚集索引(主键索引)
聚簇索引和非聚簇索引最主要的区别是数据和索引是否分开存储。
* 聚簇索引(主键索引):**将数据和索引放到一起存储**,索引结构的叶子节点保留了数据行。每个表一定会有一个聚集索引,整个表的数据存储以b+树的方式存在文件中,**b+树叶子节点中的key为主键值,data为完整记录的信息;非叶子节点存储主键的值。**
通过聚集索引检索数据只需要按照b+树的搜索过程,即可以检索到对应的记录。
* 非聚簇索引:将数据进和索引分开存储,索引叶子节点存储的是指向数据行的地址。每个表可以有多个非聚集索引,b+树结构,叶子节点的key为索引字段字段的值,data为主键的值;非叶子节点只存储索引字段的值。
通过非聚集索引检索记录的时候,需要2次操作,先在**非聚集索引中检索出主键**,**然后再到聚集索引中检索出主键对应的记录**,该过程比聚集索引多了一次操作。
在InnoDB存储引擎中,默认的索引为B+树索引,利用主键创建的索引为主索引,也是聚簇索引,在主索引之上创建的索引为辅助索引,也是非聚簇索引。
非聚簇索引一定会进行回表查询吗?
不一定,当遇到**覆盖索引**时,如果查询的数据再辅助索引上完全能获取到便不需要回表查询。
如:返回值是 id 和 name, name上有索引,这时候name的索引列就同上有 name和id了,不需要再回表查询了。
非聚簇索引的叶子节点存储的是主键,也就是说要先通过非聚簇索引找到主键,再通过聚簇索引找到主键所对应的数据,后面这个再通过聚簇索引找到主键对应的数据的过程就是回表查询
什么是前缀索引?
前缀索引是指对文本或者字符串的前几个字符建立索引,这样索引的长度更短,查询速度更快。
使用场景:前缀的区分度比较高的情况下。
ALTER TABLE table_name ADD KEY(column_name(prefix_length));
哪些情况需要创建索引?
1. 主键自动建立唯一索引
2. 频繁作为查询的条件的字段应该创建索引
3. 查询中与其他表关联的字段,外键关系建立索引
4. 频繁更新的字段不适合创建索引 因为每次更新不单单是更新了记录还会更新索引,加重IO负担
5. Where条件里用不到的字段不创建索引
6. 单间/组合索引的选择问题,who?(在高并发下倾向创建组合索引)
7. 查询中排序的字段,排序字段若通过索引去访问将大大提高排序的速度
8. 查询中统计或者分组字段
哪些情况不要创建索引?
1. 表记录太少
2. 经常增删改的表
3. 数据重复且分布平均的表字段,因此应该只为经常查询和经常排序的数据列建立索引。
注意,如果某个数据列包含许多重复的内容,为它建立索引就没有太大的实际效果。
索引的设计原则?
* 最适合索引的列是在where后面出现的列或者连接句子中指定的列,而不是出现在SELECT关键字后面的选择列表中的列。
* 索引列的基数越大,索引的效果越好,换句话说就是索引列的区分度越高,索引的效果越好。比如使用性别这种区分度很低的列作为索引,效果就会很差,因为列的基数最多也就是三种,大多不是男性就是女性。
* 尽量使用短索引,对于较长的字符串进行索引时应该指定一个较短的前缀长度,因为较小的索引涉及到的磁盘I/O较少,并且索引高速缓存中的块可以容纳更多的键值,会使得查询速度更快。
* 尽量利用最左前缀。
* 不要过度索引,每个索引都需要额外的物理空间,维护也需要花费时间,所以索引不是越多越好。
索引优化?
1. 全值匹配我最爱
2. 最佳左前缀法则 如果索引了多例,要遵守最左前缀法则。指的是查询从索引的最左前列开始并且不跳过索引中的列。带头大哥不能死,中间兄弟不能断
3. 不在索引列上做任何操作(计算、函数、(自动or手动)类型转换),会导致索引失效而转向全表扫描
4. 存储引擎不能使用索引中范围条件右边的列
5. 尽量使用覆盖索引(只访问索引的查询(索引列和查询列一致)),减少select*
6. mysql在使用不等于(!=或者<>)的时候无法使用索引会导致全表扫描
7. is null,is not null 也无法使用索引
8. like以通配符开头('$abc...')mysql索引失效会变成全表扫描操作
解决方式, 使用覆盖索引,
9. 字符串不加单引号索引失效
10. 少用or,用它连接时会索引失效
什么是事务?
事务:一组逻辑操作单元,使数据从一种状态变换到另一种状态。
事务处理的原则:保证所有事务都作为 一个工作单元 来执行,即使出现了故障,都不能改变这种执行方 式。当在一个事务中执行多个操作时,要么所有的事务都被提交( commit ),那么这些修改就 永久 地保 存下来;要么数据库管理系统将 放弃 所作的所有 修改 ,整个事务回滚( rollback )到最初状态。
事务的四大特性是什么?
* 原子性(atomicity):原子性是指事务是一个不可分割的工作单位,要么全部提交,要么全部失败回滚。
* 一致性(consistency):一致性是指事务执行前后,数据从一个 合法性状态 变换到另外一个 合法性状态 。这种状态 是 语义上 的而不是语法上的,跟具体的业务有关。
* 隔离型(isolation):一个事务的执行 不能被其他事务干扰 ,即一个事务内部的操作及使用的数据对 并发 的 其他事务是隔离的,并发执行的各个事务之间不能互相干扰。
* 持久性(durability):持久性是指一个事务一旦被提交,它对数据库中数据的改变就是 永久性的 ,接下来的其他操作和数据库 故障不应该对其有任何影响。
数据库的并发一致性问题?
1. 脏写( Dirty Write ) 事务A修改了事务B未提交的的数据。这个不用管,数据本身就解决了。
2. 脏读( Dirty Read ) 事务A读取了事务B修改但未提交的的数据。
3. 不可重复读( Non-Repeatable Read ) 事务A读取了一个字段,事务B修改了此字段,当事务A再次读取此字段时,值不同了,那就意味着发生了不可重复读。
4. 幻读( Phantom ) 事务A读取了一个字段,然后事务B在该表中插入了一些新的行,之后事务A再次读取同一个表,就会多出几行。
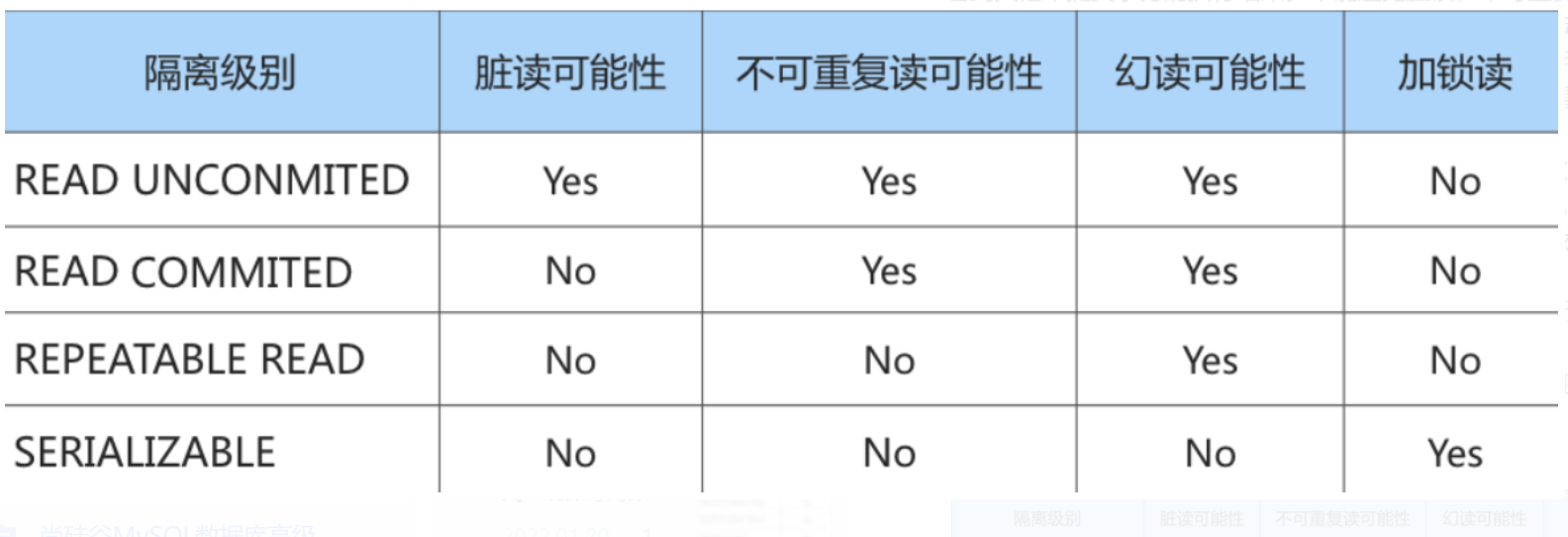
事务的四种隔离级别?
* READ UNCOMMITTED :读未提交,在该隔离级别,所有事务都可以看到其他未提交事务的执行结 果。不能避免脏读、不可重复读、幻读。
* READ COMMITTED :读已提交,它满足了隔离的简单定义:一个事务只能看见已经提交事务所做 的改变。这是大多数数据库系统的默认隔离级别(但不是MySQL默认的)。可以避免脏读,但不可 重复读、幻读问题仍然存在。
* REPEATABLE READ :可重复读,事务A在读到一条数据之后,此时事务B对该数据进行了修改并提 交,那么事务A再读该数据,读到的还是原来的内容。可以避免脏读、不可重复读,但幻读问题仍 然存在。这是MySQL的默认隔离级别。
* SERIALIZABLE :可串行化,确保事务可以从一个表中读取相同的行。在这个事务持续期间,禁止 其他事务对该表执行插入、更新和删除操作。所有的并发问题都可以避免,但性能十分低下。能避 免脏读、不可重复读和幻读。
什么是MVCC?
MVCC(multiple version concurrent control)是一种控制并发的方法,主要用来提高数据库的并发性能。
通过数据行的多个版 本管理来实现数据库的 并发控制 。
主要是为了提高数据库并发性能,用更好的方式去处理 读-写冲突 ,做到 即使有读写冲突时,也能做到 不加锁 , 非阻塞并发读 ,而这个读指的就是 快照读。
快照读
快照读又叫一致性读,读取的是快照数据。不加锁的简单的 SELECT 都属于快照读,即不加锁的非阻塞 读;
mysql中in和exists的区别?
in和exists一般用于子查询。
* 使用exists时会先进行外表查询,将查询到的每行数据带入到内表查询中看是否满足条件;使用in一般会先进行内表查询获取结果集,然后对外表查询匹配结果集,返回数据。
* in在内表查询或者外表查询过程中都会用到索引。
* exists仅在内表查询时会用到索引
* 一般来说,当子查询的结果集比较大,外表较小使用exist效率更高;当子查询寻得结果集较小,外表较大时,使用in效率更高。
* 对于not in和not exists,not exists效率比not in的效率高,与子查询的结果集无关,因为not in对于内外表都进行了全表扫描,没有使用到索引。not exists的子查询中可以用到表上的索引。
UNION和UNION ALL的区别?
union和union all的作用都是将两个结果集合并到一起。
union会对结果去重并排序,union all直接直接返回合并后的结果,不去重也不进行排序。
union all的性能比union性能好。
MySQL的复制原理及流程?如何实现主从复制?
主从部署必要条件:
* 主库开启binlog日志(设置log-bin参数)
* 主从server-id不同
* 从库服务器能连通主库
MySQL复制:为保证主服务器和从服务器的数据一致性,在向主服务器插入数据后,从服务器会自动将主服务器中修改的数据同步过来。
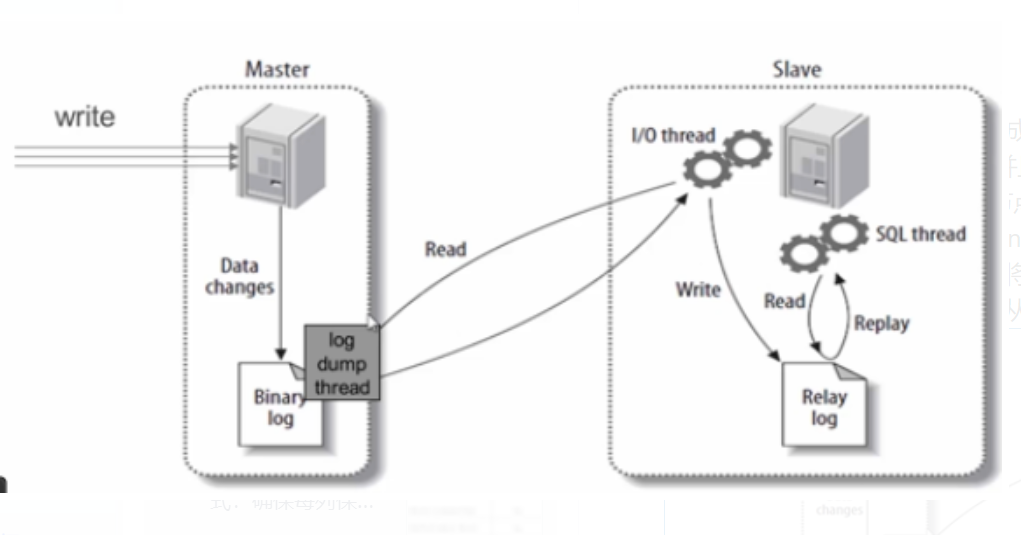
主从复制的原理:
主从复制主要有三个线程:binlog线程,I/O线程,SQL线程。
* binlog线程:负责将主服务器上的数据更改写入到二进制日志(Binary log)中。
* I/O线程:负责从主服务器上读取二进制日志(Binary log),并写入从服务器的中继日志(Relay log)中。
* SQL线程:负责读取中继日志,解析出主服务器中已经执行的数据更改并在从服务器中重放
1. Master在每个事务更新数据完成之前,将操作记录写入到binlog中。
2. Slave从库连接Master主库,并且Master有多少个Slave就会创建多少个binlog dump线程。当Master节点的binlog发生变化时,binlog dump会通知所有的Slave,并将相应的binlog发送给Slave。
3. I/O线程接收到binlog内容后,将其写入到中继日志(Relay log)中。
4. SQL线程读取中继日志,并在从服务器中重放
主从复制的作用?
* 高可用和故障转移
* 负载均衡
* 数据备份
* 升级测试
读写分离?
读写分离主要依赖于主从复制,主从复制为读写分离服务。
读写分离的优势:
* 主服务器负责写,从服务器负责读,缓解了锁的竞争
* 从服务器可以使用MyISAM,提升查询性能及节约系统开销
* 增加冗余,提高可用性
- 学习地址
- MySQL
- 查询优化
- SQL优化
- 关于or、in、not in、!=等走不走索引的说明
- 千万级数据查询优化
- MySQL 深度分页问题
- 嵌套循环 Block Nested Loop 导致索引查询慢
- MySQL增加日志统计表优化各种日志表的统计功能
- MySQL单机读写QPS(性能)优化
- sqlMode 置 select 的值可以比 group 里的多
- drop、delete、truncate的区别
- 尚硅谷MySQL数据库高级学习笔记
- MySQL架构
- 事务部分
- MySQL知识点
- mysql索引
- Linux docker安装 mysql 8.0.25
- docker 安装mysql 5.7
- mysql Field ‘xxx’ doesn’t have a default value
- mysql多实例
- docker中的sql文件导入
- mysql进阶知识
- mysql字符集
- 连接的原理
- redo日志
- InnoDB存储引擎
- InnoDB的数据存储结构
- B+树索引
- 文件系统-表空间
- Buffer Pool
- 亿级数据导入到es
- MySQL数据复制
- MySQL缺少主键的表数据
- mysql update 其中更新的字段根据另一个更新字段作为条件去更新
- MySQL指定字段值排序(将指定值排在前面)
- 设置MySQL连接数、时区
- Navicat15右键删除数据刷新就又恢复了
- MySQL替换字段部分内容
- Java和MySQL统计本周本月本季和年
- 分页时order by 排序数据重复,丢失
- mysql同一张表根据某个字段删除重复数据
- mysqldump定时全量热备
- 专题总结
- 事务
- MySQL事务
- spring事务
- spring事务本类调用
- spring事务传播行为
- spring事务失效问题
- 锁和Transactional注解一块使用的问题
- 数据安全
- 敏感数据
- SQL注入
- 数据源
- XSS
- 接口设计
- 缓存设计
- 限流
- 自定义注解实现根据用户做QPS限流
- 架构
- 高可用
- Java
- Unsatisfied dependency expressed through field ‘baseMapper‘
- mybatisplus多数据源
- 单个字母前缀的java变量
- spring
- spring循环依赖解决
- 事务@Transactional
- yml 文件配置信息绑定到java工具类的静态变量上
- @Configuration @Component 区别
- springboot启动yml文件报错
- spring方法重试注解Retryable
- spring读取yml集合数据
- spring自定义注解
- 获取resource下的图片资源
- 手机号和电话号的正则验证
- 获取字符串中的数字
- mybatis
- mybatis多参数添加数据并返回主键
- 统一异常处理
- 分组校验
- Java读取Python json.dumps 函数保存的redis数据
- springboot整合springCache
- 若依mybatis值为null的字段没有返回
- 若依
- 接口白名单
- @JsonFormat时区问题
- RequestParam.value() was empty on parameter 0
- jdk8和hutool请求第三方的https报错
- springMVC
- springMVC与vue使用post传数组
- elementUI 时间组件报错问题
- vue具名插槽slot
- springboot配置maven的profiles(配置微服务多环境切换打包)
- resources 配置文件读取顺序
- Windows的cmd部署jar注意事项
- Java基础
- JUC(锁-并发-线程池)
- CAS
- Java 锁简介
- synchronized和Logk有什么区别?用新的ock有什么好处
- synchronized锁介绍
- CompletableFuture
- 多线程
- 线程池
- 集合类
- map见过的小问题
- 退出双层循环
- StringBuilder和StringBuffer核心区别
- 日志打印
- 打印log日志
- log日志文件生成配置
- 日期时间
- 时间戳转为时间
- 并发工具
- 连接池
- http调用
- 内网访问天地图
- 判等问题
- 数值计算
- null问题
- 异常处理
- 文件IO
- 序列化
- 内存溢出OOM
- 子线程的错误, 全局异常处理捕获不到
- vue同一个项目访问多个不同ip地址接口
- Autowired注解导入为null
- shiro
- UnavailableSecurityManagerException错误
- Windows服务器80端口被占用
- java图片增加水印
- springcloud
- Feign方法配置错误导致jar包启动失败
- feign调用超时
- 定时任务quartz
- JavaPOI导出Excel
- 合并行和列
- 设置样式
- 设置背景色
- docker
- Linux 安装
- docker命令
- docker网络
- docker数据卷
- dockerfile
- docker安装ping命令
- docker-compose
- docker-compose文件内容介绍
- Linux关闭docker开机启动
- jar打包为镜像
- 迁移docker容器存储位置
- Nginx
- Linux在线安装Nginx
- nginx.conf 核心配置文件
- vue 和 nginx 刷新页面会报404
- nginx 转发给三个集群的tomcat
- ServerName匹配规则
- Nginx负载均衡策略
- location 匹配规则
- Nginx 搭建前端调用后台接口的集群
- alias与root
- nginx 拦截 post 请求, 带参数转发到前端页面
- 防盗链配置
- Nginx的缓存
- 通用Nginx配置
- nginx配置文件服务器
- 后台jar包得不到正确ip,nginx代理时要处理
- 升级使用websocket协议
- 设置IP黑/白名单
- Redis
- 缓存数据一致性
- 内存淘汰策略
- Redis数据类型
- gmt6
- Linux安装GMT6
- GMT6配置中文
- GMT文件修改Windows版本到Linux版本
- 注意GMT不同字体导致符号不同的问题
- GMT绘制南海诸岛小图
- GMT生成中文图例
- elasticsearch
- 安装配置
- Linux安装配置elasticsearch7.6.2
- Linux 安装 kibana 7.6.2
- 安装7.6.2中文分词器
- docker 安装elasticsearch7.6.2
- 安装Logback7.6.2
- springboot使用
- 0. elasticsearch账号密码模式访问
- 1. 配置连接
- 2. 索引
- 3. 批量保存更新
- Result window is too large 10000
- elasticsearch 分词的字段做排序 fielddata, 设置fielddata=true 无效果
- elasticsearch 完全匹配查询(精确查询)
- 模糊搜索
- 日期区间查询
- 6.x基础知识
- 自定义词库
- elasticsearch集群
- 搜索推荐Suggester
- 查询es保存的数组
- 亿级mysql数据导入到es
- es 报错 ORBIDDEN/12/index read-only
- es核心概念
- es的分布式架构原理
- 优化大数据量时的ES查询性能
- canal
- 1. mysql的Binlog
- 2. Canal 的工作原理
- 3. canal同步es
- JVM
- 1 类的字节码
- 2. 类的加载
- JVM知识点
- Maven
- 依赖冲突
- xxl-job
- docker 安装配置 xxl-job
- idea
- springboot启动报错命令过长
- services统一启动微服务各模块
- 云服务器安装宝塔面板
- 突然出现启动或者运行特别慢
- 有导入依赖但是显示红色同时点击进去也有依赖
- Linux
- sh文件执行报错: command not found
- 使用vagrant安装虚拟机
- Linux 开启端口
- 开放端口
- 复制文件夹及其文件到另一个文件夹
- 两个服务器之间映射端口
- TCP协议
- 分层模型
- TCP概述
- 支撑 TCP 协议的基石 —— 首部字段
- 数据包大小对网络的影响 —— MTU 与 MSS 的奥秘
- 端口号
- 三次握手
- TCP 自连接
- 四次挥手
- TCP 头部时间戳
- 分布式
- 分布式脑裂问题
- 分布式事务
- 基础知识
- 实现分布式事务的方案
- 阿里分布式事务中间件seata
- 幂等性问题
- 其他工具
- webstorm git提交代码后project目录树不显示
- 消息队列
- 如何保证消费的顺序
- 数据结构
- 漫画算法:小灰的算法之旅