
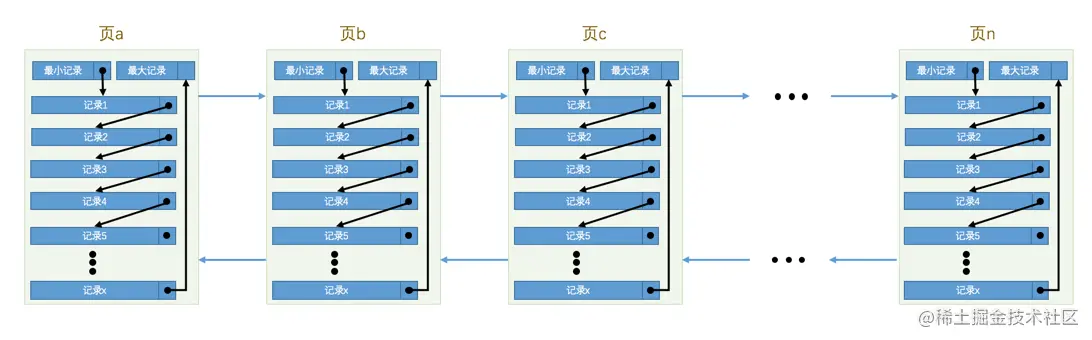
各个数据页可以组成一个`双向链表`,而每个数据页中的记录会按照主键值从小到大的顺序组成一个`单向链表`,每个数据页都会为存储在它里边儿的记录生成一个`页目录`,在通过主键查找某条记录的时候可以在`页目录`中使用二分法快速定位到对应的槽,然后再遍历该槽对应分组中的记录即可快速找到指定的记录
`目录项记录`和普通的`用户记录`的不同点:
* `目录项记录`的`record_type`值是1,而普通用户记录的`record_type`值是0。
* `目录项记录`只有主键值和页的编号两个列,而普通的用户记录的列是用户自己定义的,可能包含很多列,另外还有`InnoDB`自己添加的隐藏列。
* `min_rec_mask`,只有在存储`目录项记录`的页中的主键值最小的`目录项记录`的`min_rec_mask`值为`1`,其他别的记录的`min_rec_mask`值都是`0`。
#### 聚簇索引
1. 使用记录主键值的大小进行记录和页的排序,这包括三个方面的含义:
* 页内的记录是按照主键的大小顺序排成一个单向链表。
* 各个存放用户记录的页也是根据页中用户记录的主键大小顺序排成一个双向链表。
* 存放目录项记录的页分为不同的层次,在同一层次中的页也是根据页中目录项记录的主键大小顺序排成一个双向链表。
2. `B+`树的叶子节点存储的是完整的用户记录。
所谓完整的用户记录,就是指这个记录中存储了所有列的值(包括隐藏列)。
我们把具有这两种特性的`B+`树称为`聚簇索引`,所有完整的用户记录都存放在这个`聚簇索引`的叶子节点处。这种`聚簇索引`并不需要我们在`MySQL`语句中显式的使用`INDEX`语句去创建(后边会介绍索引相关的语句),`InnoDB`存储引擎会自动的为我们创建聚簇索引。另外有趣的一点是,在`InnoDB`存储引擎中,`聚簇索引`就是数据的存储方式(所有的用户记录都存储在了`叶子节点`),也就是所谓的索引即数据,数据即索引。
**将数据和索引放到一起存储**,索引结构的叶子节点保留了数据行。每个表一定会有一个聚集索引,整个表的数据存储以b+树的方式存在文件中,**b+树叶子节点中的key为主键值,data为完整记录的信息;非叶子节点存储主键的值。**
#### 二级索引(非聚簇索引)
和聚簇索引区别
* 使用记录`c2`列的大小进行记录和页的排序,这包括三个方面的含义:
* 页内的记录是按照`索引`列的大小顺序排成一个单向链表。
* 各个存放用户记录的页也是根据页中记录的`索引`列大小顺序排成一个双向链表。
* 存放目录项记录的页分为不同的层次,在同一层次中的页也是根据页中目录项记录的`索引`列大小顺序排成一个双向链表。
* `B+`树的叶子节点存储的并不是完整的用户记录,而只是`索引列+主键`这两个列的值。
* 目录项记录中不再是`主键+页号`的搭配,而变成了`索引列+页号`的搭配。
如果返回的列不在非聚簇索引树种, 则还需要根据得到的主键去聚簇索引里查询详细信息, 此过程叫**回表**
**覆盖索引**:索引字段覆盖了查询语句涉及的字段,直接通过索引文件就可以返回查询所需的数据,不必通过回表操作。
## 索引
* 每个索引都对应一棵`B+`树,`B+`树分为好多层,最下边一层是叶子节点,其余的是内节点。所有`用户记录`都存储在`B+`树的叶子节点,所有`目录项记录`都存储在内节点。
* `InnoDB`存储引擎会自动为主键(如果没有它会自动帮我们添加)建立`聚簇索引`,聚簇索引的叶子节点包含完整的用户记录。
* 我们可以为自己感兴趣的列建立`二级索引`,`二级索引`的叶子节点包含的用户记录由`索引列 + 主键`组成,所以如果想通过`二级索引`来查找完整的用户记录的话,需要通过`回表`操作,也就是在通过`二级索引`找到主键值之后再到`聚簇索引`中查找完整的用户记录。
* `B+`树中每层节点都是按照索引列值从小到大的顺序排序而组成了双向链表,而且每个页内的记录(不论是用户记录还是目录项记录)都是按照索引列的值从小到大的顺序而形成了一个单链表。如果是`联合索引`的话,则页面和记录先按照`联合索引`前边的列排序,如果该列值相同,再按照`联合索引`后边的列排序。
* 通过索引查找记录是从`B+`树的根节点开始,一层一层向下搜索。由于每个页面都按照索引列的值建立了`Page Directory`(页目录),所以在这些页面中的查找非常快。
## 索引的代价
* 空间
每建立一个索引都要为它建立一棵`B+`树,每一棵`B+`树的每一个节点都是一个数据页,一个页默认会占用`16KB`的存储空间,一棵很大的`B+`树由许多数据页组成
* 时间
每次对表中的数据进行增、删、改操作时,都需要去修改各个`B+`树索引。而增、删、改操作可能会对节点和记录的排序造成破坏,所以存储引擎需要额外的时间进行一些记录移位,页面分裂、页面回收啥的操作来维护好节点和记录的排序。
`WHERE`子句中的几个搜索条件的顺序对查询结果没有影响, MySQL的优化器是很智能的.
1. `B+`树索引在空间和时间上都有代价,所以没事儿别瞎建索引。
2. `B+`树索引适用于下边这些情况:
* 全值匹配
* 匹配左边的列
* 匹配范围值
* 精确匹配某一列并范围匹配另外一列
* 用于排序
* 用于分组
3. 在使用索引时需要注意下边这些事项:
* 只为用于搜索、排序或分组的列创建索引
* 为列的基数大的列创建索引
* 索引列的类型尽量小
* 可以只对字符串值的前缀建立索引
* 只有索引列在比较表达式中单独出现才可以适用索引
* 为了尽可能少的让`聚簇索引`发生页面分裂和记录移位的情况,建议让主键拥有`AUTO_INCREMENT`属性。
* 定位并删除表中的重复和冗余索引
* 尽量使用`覆盖索引`进行查询,避免`回表`带来的性能损耗。
- 学习地址
- MySQL
- 查询优化
- SQL优化
- 关于or、in、not in、!=等走不走索引的说明
- 千万级数据查询优化
- MySQL 深度分页问题
- 嵌套循环 Block Nested Loop 导致索引查询慢
- MySQL增加日志统计表优化各种日志表的统计功能
- MySQL单机读写QPS(性能)优化
- sqlMode 置 select 的值可以比 group 里的多
- drop、delete、truncate的区别
- 尚硅谷MySQL数据库高级学习笔记
- MySQL架构
- 事务部分
- MySQL知识点
- mysql索引
- Linux docker安装 mysql 8.0.25
- docker 安装mysql 5.7
- mysql Field ‘xxx’ doesn’t have a default value
- mysql多实例
- docker中的sql文件导入
- mysql进阶知识
- mysql字符集
- 连接的原理
- redo日志
- InnoDB存储引擎
- InnoDB的数据存储结构
- B+树索引
- 文件系统-表空间
- Buffer Pool
- 亿级数据导入到es
- MySQL数据复制
- MySQL缺少主键的表数据
- mysql update 其中更新的字段根据另一个更新字段作为条件去更新
- MySQL指定字段值排序(将指定值排在前面)
- 设置MySQL连接数、时区
- Navicat15右键删除数据刷新就又恢复了
- MySQL替换字段部分内容
- Java和MySQL统计本周本月本季和年
- 分页时order by 排序数据重复,丢失
- mysql同一张表根据某个字段删除重复数据
- mysqldump定时全量热备
- 专题总结
- 事务
- MySQL事务
- spring事务
- spring事务本类调用
- spring事务传播行为
- spring事务失效问题
- 锁和Transactional注解一块使用的问题
- 数据安全
- 敏感数据
- SQL注入
- 数据源
- XSS
- 接口设计
- 缓存设计
- 限流
- 自定义注解实现根据用户做QPS限流
- 架构
- 高可用
- Java
- Unsatisfied dependency expressed through field ‘baseMapper‘
- mybatisplus多数据源
- 单个字母前缀的java变量
- spring
- spring循环依赖解决
- 事务@Transactional
- yml 文件配置信息绑定到java工具类的静态变量上
- @Configuration @Component 区别
- springboot启动yml文件报错
- spring方法重试注解Retryable
- spring读取yml集合数据
- spring自定义注解
- 获取resource下的图片资源
- 手机号和电话号的正则验证
- 获取字符串中的数字
- mybatis
- mybatis多参数添加数据并返回主键
- 统一异常处理
- 分组校验
- Java读取Python json.dumps 函数保存的redis数据
- springboot整合springCache
- 若依mybatis值为null的字段没有返回
- 若依
- 接口白名单
- @JsonFormat时区问题
- RequestParam.value() was empty on parameter 0
- jdk8和hutool请求第三方的https报错
- springMVC
- springMVC与vue使用post传数组
- elementUI 时间组件报错问题
- vue具名插槽slot
- springboot配置maven的profiles(配置微服务多环境切换打包)
- resources 配置文件读取顺序
- Windows的cmd部署jar注意事项
- Java基础
- JUC(锁-并发-线程池)
- CAS
- Java 锁简介
- synchronized和Logk有什么区别?用新的ock有什么好处
- synchronized锁介绍
- CompletableFuture
- 多线程
- 线程池
- 集合类
- map见过的小问题
- 退出双层循环
- StringBuilder和StringBuffer核心区别
- 日志打印
- 打印log日志
- log日志文件生成配置
- 日期时间
- 时间戳转为时间
- 并发工具
- 连接池
- http调用
- 内网访问天地图
- 判等问题
- 数值计算
- null问题
- 异常处理
- 文件IO
- 序列化
- 内存溢出OOM
- 子线程的错误, 全局异常处理捕获不到
- vue同一个项目访问多个不同ip地址接口
- Autowired注解导入为null
- shiro
- UnavailableSecurityManagerException错误
- Windows服务器80端口被占用
- java图片增加水印
- springcloud
- Feign方法配置错误导致jar包启动失败
- feign调用超时
- 定时任务quartz
- JavaPOI导出Excel
- 合并行和列
- 设置样式
- 设置背景色
- docker
- Linux 安装
- docker命令
- docker网络
- docker数据卷
- dockerfile
- docker安装ping命令
- docker-compose
- docker-compose文件内容介绍
- Linux关闭docker开机启动
- jar打包为镜像
- 迁移docker容器存储位置
- Nginx
- Linux在线安装Nginx
- nginx.conf 核心配置文件
- vue 和 nginx 刷新页面会报404
- nginx 转发给三个集群的tomcat
- ServerName匹配规则
- Nginx负载均衡策略
- location 匹配规则
- Nginx 搭建前端调用后台接口的集群
- alias与root
- nginx 拦截 post 请求, 带参数转发到前端页面
- 防盗链配置
- Nginx的缓存
- 通用Nginx配置
- nginx配置文件服务器
- 后台jar包得不到正确ip,nginx代理时要处理
- 升级使用websocket协议
- 设置IP黑/白名单
- Redis
- 缓存数据一致性
- 内存淘汰策略
- Redis数据类型
- gmt6
- Linux安装GMT6
- GMT6配置中文
- GMT文件修改Windows版本到Linux版本
- 注意GMT不同字体导致符号不同的问题
- GMT绘制南海诸岛小图
- GMT生成中文图例
- elasticsearch
- 安装配置
- Linux安装配置elasticsearch7.6.2
- Linux 安装 kibana 7.6.2
- 安装7.6.2中文分词器
- docker 安装elasticsearch7.6.2
- 安装Logback7.6.2
- springboot使用
- 0. elasticsearch账号密码模式访问
- 1. 配置连接
- 2. 索引
- 3. 批量保存更新
- Result window is too large 10000
- elasticsearch 分词的字段做排序 fielddata, 设置fielddata=true 无效果
- elasticsearch 完全匹配查询(精确查询)
- 模糊搜索
- 日期区间查询
- 6.x基础知识
- 自定义词库
- elasticsearch集群
- 搜索推荐Suggester
- 查询es保存的数组
- 亿级mysql数据导入到es
- es 报错 ORBIDDEN/12/index read-only
- es核心概念
- es的分布式架构原理
- 优化大数据量时的ES查询性能
- canal
- 1. mysql的Binlog
- 2. Canal 的工作原理
- 3. canal同步es
- JVM
- 1 类的字节码
- 2. 类的加载
- JVM知识点
- Maven
- 依赖冲突
- xxl-job
- docker 安装配置 xxl-job
- idea
- springboot启动报错命令过长
- services统一启动微服务各模块
- 云服务器安装宝塔面板
- 突然出现启动或者运行特别慢
- 有导入依赖但是显示红色同时点击进去也有依赖
- Linux
- sh文件执行报错: command not found
- 使用vagrant安装虚拟机
- Linux 开启端口
- 开放端口
- 复制文件夹及其文件到另一个文件夹
- 两个服务器之间映射端口
- TCP协议
- 分层模型
- TCP概述
- 支撑 TCP 协议的基石 —— 首部字段
- 数据包大小对网络的影响 —— MTU 与 MSS 的奥秘
- 端口号
- 三次握手
- TCP 自连接
- 四次挥手
- TCP 头部时间戳
- 分布式
- 分布式脑裂问题
- 分布式事务
- 基础知识
- 实现分布式事务的方案
- 阿里分布式事务中间件seata
- 幂等性问题
- 其他工具
- webstorm git提交代码后project目录树不显示
- 消息队列
- 如何保证消费的顺序
- 数据结构
- 漫画算法:小灰的算法之旅