
## *****Gerapy 使用*****
Gerapy 是一款分布式爬虫管理框架,支持 Python 3,基于 Scrapy、Scrapyd、Scrapyd-Client、Scrapy-Redis、Scrapyd-API、Scrapy-Splash、Jinjia2、Django、Vue.js 开发,Gerapy 可以帮助我们:
更方便地控制爬虫运行
更直观地查看爬虫状态
更实时地查看爬取结果
更简单地实现项目部署
更统一地实现主机管理
更轻松地编写爬虫代码(几乎没用,感觉比较鸡肋)
## **Greapy安装**
### 1.gerapy下载
~~~
pip install gerapy
~~~
查看是否安装成功
### 2.初始化gerapy
~~~
gerapy init
~~~
执行后会在当前目录下生成一个名字为gerapy的文件夹cd gerapy接着进入该文件夹下,可以看到project文件家说明初始化成功
### 3.初始化数据库
~~~
gerapy migrate
~~~
(此命令在gerapy目录下执行)会在gerapy目录下生成一个sqlite数据库,同时创建数据表
### 4.运行gerapy服务
~~~
gerapy runserver
~~~
(如果电脑在打开酷狗音乐,请关闭再访问:因为端口是一样的
### 5.访问gerapy管理界面
~~~
http://127.0.0.1:8000
~~~
如果遇到:需要登录账号密码 ,但是我们没有设置的话,可以执行:
~~~
gerapy migrate
~~~
初始化数据库
~~~
gerapy createsuperuser
~~~
创建超级用户 (之后就是输入Username:, Email:--可以不用写直接回车, Password:)
### 访问成功!!!
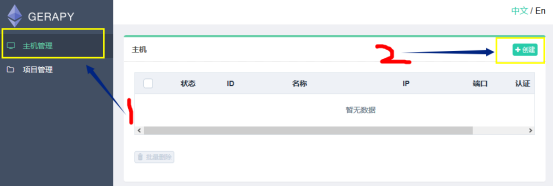
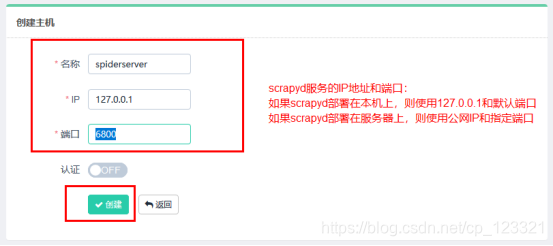
### 7.点击左侧 Clients 选项卡,即主机管理页面,添加我们的 Scrapyd 远程服务,点击右上角的创建按钮即可添加我们需要管理的 Scrapyd 服务。
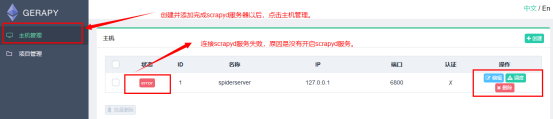
### 8.在cmd中,开启scrapyd服务。(如果scrapyd在远程服务器上已经部署成功了,那么是不需要再次进行开启的。一般远程服务器上的scrapyd会一直保持运行状态。)
在cmd中输入scrapyd,即可开启服务.

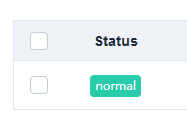
### 9.再次刷新主机管理,scrapyd的连接状态变成normal即可。
# 二、在gerapy中部署爬虫项目
### 1\. 点击左侧的 Projects ,即项目管理选项。

### 2.将自己的爬虫项目,拷贝到gerapy目录下的projects目录下。
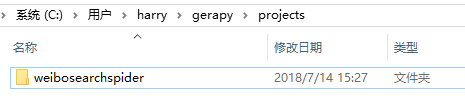
### 3.刷新浏览器页面,我们便可以看到 Gerapy 检测到了这个项目。
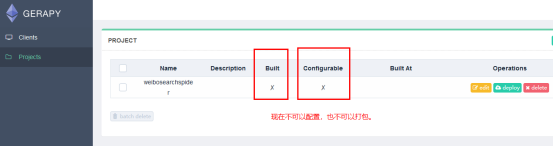
### 4.点击部署按钮进行打包和部署,在右下角我们可以输入打包时的描述信息,类似于 Git 的 commit 信息,然后点击打包按钮,即可发现 Gerapy 会提示打包成功,同时在左侧显示打包的结果和打包名称。

### 5.开始打包。

### 6.打包完成以后,开始将爬虫项目部署到scrapyd服务上。

### 三、开始调度爬虫,检测爬虫的运行状态。
### 1.部署完毕之后就可以回到 “主机管理”页面进行任务调度。
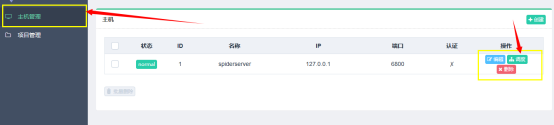
### 2.选择要运行的爬虫项目。
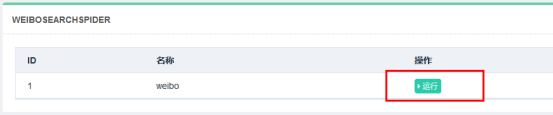
### 3.查看运行结果。

- thinkphp
- thinkphp笔记
- 后台登陆退出
- config配置
- 隐藏后台模块
- 单独调用腾讯云行为验证码
- api接口跨域问题
- api接口创建案例代码
- 使用gateway worker
- 使用swoole代码笔记
- 使用队列 think-queue笔记
- 后台布局
- MySQL
- 1、关于lnmp mysql的一个坑
- 2、mysql实现group by后取各分组的最新一条
- 其他
- 搞笑的注释代码
- 分页类
- nodejs 打包网址为exe
- 免费天气预报API接口
- Ajax
- 简单的ajax分页1
- 通用ajax-post提交
- 引用的类库文件
- Auth.php
- Auth.php权限控制对应的数据库表结构
- Layui.php
- Pinyin.php
- Random.php
- Tree.php
- Tree2.php
- Js-Jq
- Git的使用
- 3、bootstrap-datetimepicker实现两个时间范围输入
- CentOS安装SSR做梯子
- Python爬虫
- 1、安装Gerapy
- 2、安装Scrapy
- 3、Scrapy使用
- 4、Scrapy框架,爬取网站返回json数据(spider源码)
- 0、Python pip更换国内源(一句命令换源)
- 服务器运维
- 1、宝塔使用webhook更新服务器代码
- 2、搭建内网穿透
- 3、数据库主从同步
- 4、数据库复制
- hui-Shop问题
- 1、前端模板的注意事项
- 2、模板标签