
## 介绍
MySQL 提供了一个**EXPALIN**命令,可以用于对**SELECT 语句**的执行计划进行分析,并详细的输出分析结果,供开发人员进行针对性的优化。
我们想要查询一条sql有没有用上索引,有没有全表查询,这些都可以通过explain这个命令来查看。
通过explain命令,我们可以深入了解到MySQL的基于开销的优化器,还可以获得很多被优化器考虑到的访问策略的细节以及运行sql语句时哪种策略预计会被优化器采用。
explain的使用十分简单,通过在查询语句前面加一个explain关键字即可。

## 参数说明
explain 命令一共返回12列信息,分别是:
~~~text
id、select_type、table、partitions、type、possible_keys、key、key_len、ref、rows、filtered、Extra
~~~
以下是本文的案例表:
~~~mysql
# 用户表
CREATE TABLE user(
id int primary key auto_increment,
nickname varchar(100),
name varchar(100),
age int,
sex tinyint(1),
dep int,
addr int,
description varchar(100)
)ENGINE INNODB;
# 部门表
CREATE TABLE dep(
id int primary key auto_increment,
name varchar(100)
)ENGINE INNODB;
# 地址表
CREATE TABLE addr(
id int primary key auto_increment,
address varchar(100)
)ENGINE INNODB;
# 普通索引
ALTER TABLE user ADD INDEX idx_dep(dep);
# 唯一索引
ALTER TABLE user ADD unique INDEX uniq_name(name);
# 复合索引
ALTER TABLE user ADD INDEX c_nickname_age_sex(nickname,age,sex);
# 全文索引
ALTER TABLE user ADD FULLTEXT f_description(description);
# 普通索引
ALTER TABLE dep ADD INDEX idx_name(name);
~~~
## id 列
* 每个select语句都会自动分配的一个唯一标识符
* 表示查询中,操作表的顺序,有三种情况
* id相同,执行顺序从上到下
* id不同,如果是子查询,id号会自增,id越大,**优先级越高**
* id相同的不相同的同时存在
* id列为null表示为结果集,不需要使用这个语句来查询
## select\_type 列(很重要)
查询类型,主要用于区别**普通查询、联合查询(union、union all)、子查询等复杂查询。**
**simple**
表示不需要union操作或者不包含子查询的简单select查询。有连接查询时,外层的查询为simple,且只有一个。

**primary**
一个需要使用union的操作或者含有子查询的select,位于最外层的单位查询的select\_type即为primary。且只有一个

**subquery**
除了from子句中包含的子查询外,其它地方出现的子查询都可能时subquery

**dependent subquery**
子查询的结果受到外层的影响:

**union、union result**
union 连接的多表查询,第一个查询是primary,后面的是union, 结果集是 union result

**dependent union**
和union一样,出现在union或者union all中,但是这个查询要受到外部查询的影响

**derived**
在from子句后面的子查询,也叫派生表,**注意,在MySql5.6 对于此查询没有优化,所以查询类型是derived.在mysql 5.7 使用了 Merge Derived table 优化,查询类型变为SIMPLE。通过控制参数: optimizer\_switch='derived=on|off' 决定开始还是优化。默认开启。**

mysql 5.7
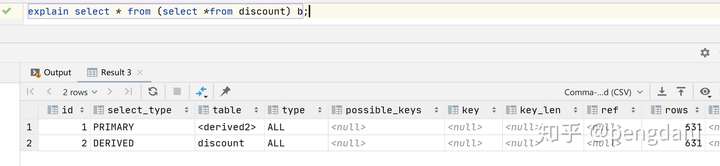
mysql 5.6
## table 列
* 显示的查询表名,如果查询使用了别名,那么这里显示的就是别名
* 如果不涉及对数据表的操作,那么这里就是null
* 如果显示为尖括号括起来的就表示这是一个临时表,N就是执行计划的id,表示结果来自这个查询
* 如果显示为尖括号括起来的也表示一个临时表,表示来自union查询id为n、m的结果集
## partitions 列
分区信息
## type 列 重要
* 依次从好到差:
~~~mysql
system、const、eq_ref、ref、full_text、ref_or_null、unique_subquery、
index_subquery、range、index_merge、index、all
~~~
除了 All 以外,其它的类型都可以用到索引,除了index\_merge可以使用多个索引之外,其它的类型最多只能使用到一个索引。
注意!!最少也应该要使用索引到range级别!
**system**
表中只有一行数据或者是空表。

**const**
使用唯一**索引或者主键**,返回记录一定是一条的等值where条件时,通常type是const。
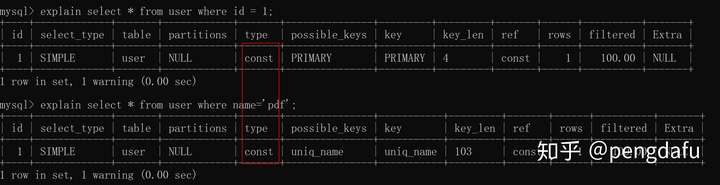
**eq\_ref**
连接字段为主键或者唯一索引,此类型通常出现于多表的join查询,表示对于前表的每一个结果,都对应后表的唯一一条结果。并且查询的比较是=操作,查询效率比较高。

上面未使用覆盖索引,下面使用覆盖索引,减少回表
**ref**
ref有三种情况:
1. 非主键或者唯一键的等值查询
2. join连接字段是非主键或者唯一键
3. 最左前缀索引匹配
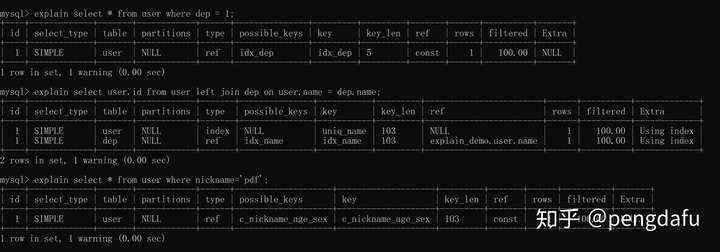
三个查询分别对应上面三种情况
**fulltext**
全文检索索引。
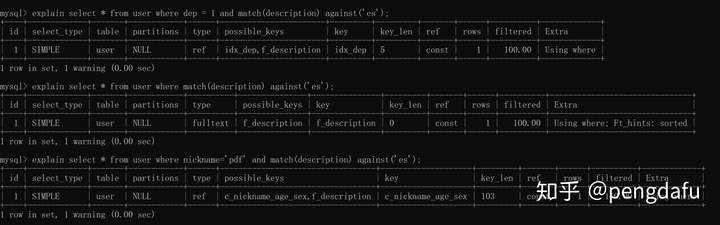
并不是优先使用全文索引
**ref\_or*\_*null**
和ref类似,增加了null值判断
**unique\_subquery、 index\_subquery**
都是子查询,前者返回唯一值,后者返回可能有重复。
**range 重要**
索引范围扫描,常用于 ><,is null,between,in,like等

**index\_merge(索引合并)**
表示查询使用了两个或者以上的索引数量,常见于and或者or查询匹配上了多个不同索引的字段
**index(辅助索引)**
减少回表次数,因为要查询的索引都在一颗索引树上

**all 全表扫描**
## possible\_keys 列
此次查询中,可能选用的索引
## key 列
查询实际使用的索引,select\_type为index\_merge时,key列可能有多个索引,其它时候这里只会有一个
## key\_len 列
* 用于处理查询的索引长度,如果是单列索引,那么整个索引长度都会计算进去,如果是多列索引,那么查询不一定能使用到所有的列,具体使用了多少个列的索引,这里就会计算进去,没有使用到的索引,这里不会计算进去。
* 留意一下这个长度,计算一下就知道这个索引使用了多少列
* 另外,key\_len 只计算 where 条件使用到索引长度,而排序和分组就算用到了索引也不会计算key\_len
## ref
* 如果是使用的常数等值查询,这里会显示const
* 如果是连接查询,被驱动表的执行计划这里会显示驱动表的关联字段
* 如果是条件使用了表达式或者函数,或者条件列发生了内部隐式转换,这里可能会显示func
## rows
执行计划估算的扫描行数,不是精确值(innodb不是精确值,myisam是精确值,主要是因为innodb使用了mvcc)。
## extra
这个列包含很多不适合在其它列显示的重要信息,有很多种,常用的有:
* **using temporary**
* 表示使用了临时表存储中间结果
* MySQL在对**order by和group by**时使用临时表
* 临时表可以是内存临时表和磁盘临时表,执行计划中看不出来,需要查看status变量:used\_tmp\_table、used\_tmp\_disk\_table才可以看出来

* no table used
不带from字句的查询或者from dual查询(explain select 1;)
**使用 not in() 形式的子查询查询或者not exists运算符的连接查询,这种叫做反链接**
**即:**一般连接先查询内表再查询外表,反链接就是先查询外表再查询内表
* **using filesort**
* 排序时无法使用到所以就会出现这个,常见于order by和group by
* 说明MySQL会使用一个外部的索引进行排序,而不是按照索引顺序进行读取
* MySQL中无法利用索引完成的排序就叫“文件排序”

* **using index 查询时候不需要回表**
* 表示相应的select查询中使用到了**覆盖索引(Covering index)**,避免访问表的数据行
* 如果同时出现了using where,说明索引被用来执行查询键值
* 如果没有using where,表示读取数据而不是执行查找操作

* **using where**
* 表示存储引擎返回的记录并不都是符合条件的,需要在server层进行筛选过滤,性能很低

* **using index condition**
* 索引下推,不需要再在server层进行过滤,5.6.x开始支持
* **first match**
* 5.6.x 开始出现的优化子查询的新特性之一,常见于where字句含有in()类型的子查询,如果内表数据量过大,可能出现
* **loosescan**
* 5.6.x 开始出现的优化子查询的新特性之一,常见于where字句含有in()类型的子查询,如果内表返回有重复值,可能出现
## filtered 列
5.7之后的版本默认就有这个字段,不需要使用explain extended了。这个字段表示存储引擎返回的数据在server层过滤后,剩下多少满足查询的记录数量的比例,注意是百分比,不是具体记录数。
转载:https://zhuanlan.zhihu.com/p/149807046
- PHP书写规则
- 代码缩进
- 大括号{ }书写规则
- 变量赋值对齐
- if条件判断规范
- 避免嵌入式赋值
- 函数和方法的注释
- 项目规范
- 业务逻辑logic
- model模型
- 控制器
- view视图
- 定制项目开发
- 接口输出变量格式
- mysql设计规范
- 二维码系列
- php 用phprqcode 生成简单的二维码
- 小程序二维码
- 其他小工具
- 获取单个汉字拼音首字母
- js 调起打印多出一张空白的问题?
- php 2张图片合拼
- 判断一个汉字可以等于1个字符,2个字符,3个字符
- 微信小程序获取页面路径
- 小程序js、canvas实现矩形圆角、圆形头像图片
- php phpMailer 发送邮件(亲测有效)
- 系统配置表
- php 用tcpdf 生成pdf
- PHP mkdir():创建目录
- php 通过svg动态生成生成后缀图标
- php 本地安装SSL证书
- php 生成首字母头像
- php 接口数据压缩返回,减少带宽
- PHP向二维数组多维数组追加相同元素
- php 指定时间戳上加上一天,一个月,一年的方法
- Spreadsheet 表格生成
- php 多维数组排序 多维数组按照某个字段排序
- php根据开始和结束时间获取期间日期
- php 获取本周、上周、本月、上月及指定时间所在周、月的起止时间
- php GeoIP2通过ip获取国家和地区城市
- 奇葩报错问题
- session赋值报错
- 服务器配置lnmp
- 开启mysql binglog 日志
- lnmp 开启远程访问3306
- 开启mysql 慢日志查询
- 开通Liunx 3306 端口(远程连接开放)
- 搭建lnmp
- liunx 多台服务器搭建共享文件夹图片文件夹
- liunx 操作命令1
- nginx专区
- 禁止外部ip访问
- 强制跳转到https
- mysql专区
- 版本5.7报错 only_full_group_by
- 把同一张表的一个字段的内容复制到另一个字段里
- lnmp关闭严格模式
- mysql 两张不同结构的表连表查询,合并,并分页,排序 教你如何实现UNION
- mysql 查询一张表中某个字段不同状态的数量统计
- mysql数据库快速插入百万条级别的测试数据
- MySQL EXPLAIN 详解,可用EXPLAIN来分析优化数据库sql语句
- mysql 三星索引
- mysql 返回数据排名查询获取排名的方法,亲测有效
- mysql使用查询出来的值并且更新update新的表报错?叫你一招
- mysql 怎样自定义in查询操作排序
- mysql 百万级别和千万级数据分页查询性能优化
- mysql 查询某个字段按照逗号分割返回
- mysql 用sql命令导入数据库
- mysql 根据某个字段的值匹配替换某个值
- Mysql中分组后取最新的一条数据排序
- Certbot-免费的https证书
- session_start()报错问题
- 文件大打不开?代码实现分割
- windows服务器专区
- apache 突然重启动不了
- windows 定时任务
- liunx专区
- liunx 定时器检查php是否能访问,重启
- liunx 操作命令
- 定时器 tp5 命令行
- liunx查看端口是否开放
- liunx上传或者下载本地文件
- 前端
- jq克隆html
- Jquery添加元素(append,prepend,after,before四种方法区别对比)
- 小程序switch样式修改
- css div 里面模块 平均展开
- 安全小学堂
- 验证码一次一码
- 实战thinkphp6
- 前言
- 中间件
- 开启多语言
- RabbitMQ 专区
- 下载RabbitMQ
- ftp专区
- Linux安装vsftpd及配置详解
- 小程序栏目
- 微信小程序封装统一接口请求api数据
- 云数据库
- 小程序云开发更新云函数数组的某一项,并且某个是变量代替
- php面试总结
- Mysql面试
- PHP面试知识
- Thinkphp框架小知识
- fastadmin 文档
- fastadmin js 渲染 动态下拉(SelectPage)组件
- fastadmin 列表搜索栏 支持三级联动 地区选项
- fastadmin searchList组件自定义数据返回
- 开发工具
- phpstorm 一直在Indexing,一直加载索引,无法正常使用
- PHP专区
- session 工作流程
- Redis
- php redis 基本操作
- SourceTree 3.3.9跳过注册安装
- composer 专区
- 手把手教你写一个composer包
- freessl证书申请