[TOC]
# XPath快速了解
>`XPath`是用于浏览XML文档元素和属性的语言,通过XPath路径表达式遍历节点元素就如同在磁盘上访问文件夹路径一样的方便精准表达元素和属性。
XPath内置了200多个函数帮助我们处理文本、数字、布尔值、日期和时间等类型数据,它的语法规则已经广泛用于很多语言中。
## XPath术语
- 节点(Node) : 元素、属性、文本、命名空间、处理指令、注释和文档(根)节点。XML文档被当做节点树对待,树的根被称作文档节点或者根节点。
- 基本值(原子值, Atomic value): 无父或无子的节点。
- 项目(Items):基本值或者节点都可以称为一个`item`项目。
- 节点关系: 父(Parent)、子(Children)、同胞(Sibling)、先辈(Ancestor)、后代(Descendant)
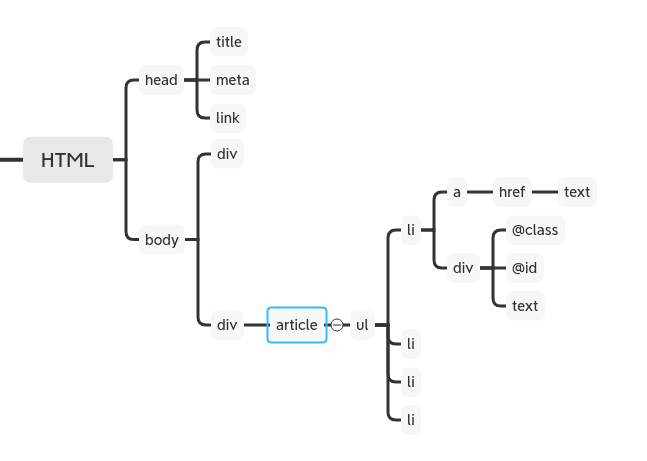
以`articlie`节点为例,父节点为`div`,子节点为`ul` ,孙子节点为 `li` 。
再以`li/div`节点为例, 节点包含节点有 `@class`属性节点, `@id`属性节点和`text`文本无子节点就称为原子值。
## XPath路径表达式语法
我们以下面例子了解语法及含义:
```XML
<?xml version="1.0" encoding="ISO-8859-1"?>
<bookstore>
<book>
<title lang="eng">Harry Potter</title>
<price>29.99</price>
</book>
<book>
<title lang="eng">Learning XML</title>
<price>39.95</price>
</book>
</bookstore>
```
### 选取节点
下面列出了最常用的路径表达式:
| 术语 | 含义 |示例|
| :------------- | :------------- | :------------- |
|node_name|选取`node_name`节点的所有子节点。|bookstore|
|/|从根节点选取。|/html/body/table|
|//|从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。|//div[@class="article"]|
|\.|选取当前节点。|\./a/@href|
|\.\.|选取当前节点的父节点。|\.\./div[@class="article"]|
|@|选取属性。|//div[@class="article"]|
来看下下面的路径表达式例子以及表达式的含义解释:
| 路径表达式 | 含义 |
| :------------- | :------------- |
|bookstore|选取 bookstore 元素的所有子节点。|
|/bookstore|选取根元素 bookstore。注释:假如路径起始于正斜杠( / ),则此路径始终代表到某元素的绝对路径!|
|bookstore/book|选取属于 bookstore 的子元素的所有 book 元素。|
|//book|选取所有 book 子元素,而不管它们在文档中的位置。|
|bookstore//book|选择属于 bookstore 元素的后代的所有 book 元素,而不管它们位于 bookstore 之下的什么位置。|
|//@lang|选取名为 lang 的所有属性。|
### 谓语(Predicates)
谓语用来查找某个特定的节点或者包含某个指定的值的节点。
谓语被嵌在方括号中。
|路径表达式 |结果 |
| :----| :----|
|/bookstore/book[1] |选取属于 bookstore 子元素的第一个 book 元素。 |
|/bookstore/book[last()] |选取属于 bookstore 子元素的最后一个 book 元素。 |
|/bookstore/book[last()-1] |选取属于 bookstore 子元素的倒数第二个 book 元素。 |
|/bookstore/book[position()< 3] |选取最前面的两个属于 bookstore 元素的子元素的 book 元素。 |
|//title[@lang] |选取所有拥有名为 lang 属性的 title 元素。 |
|//title[@lang='eng'] |选取所有 title 元素,且这些元素拥有值为 eng 的 lang 属性。 |
|/bookstore/book[price>35.00] |选取 bookstore 元素的所有 book 元素,且其中的 price 元素的值须大于 35.00。 |
|/bookstore/book[price>35.00]/title |选取 bookstore 元素中的 book 元素的所有 title 元素,且其中的 price 元素的值须大于 35.00。 |
### 选取通配符
|通配符 |描述 |
| :----| :----|
|* |匹配任何元素节点。 |
|@* |匹配任何属性节点。 |
|node() |匹配任何类型的节点。 |
示例:
|路径表达式 |结果 |
| :----| :----|
|/bookstore/* |选取 bookstore 元素的所有子元素。 |
|//* |选取文档中的所有元素。 |
### 多个节点选取方法
> 过在路径表达式中使用“|”运算符,您可以选取若干个路径。
|路径表达式 |结果 |
| :----| :----|
|//book/title \| //book/price |选取 book 元素的所有 title 和 price 元素。 |
|//title \| //price |选取文档中的所有 title 和 price 元素。 |
## XPath轴(Axes)
轴可定义相对于当前节点的节点集。
|轴名称(axisname) |含义 |
| :----| :----|
|ancestor |选取当前节点的所有先辈(父、祖父等)。 |
|ancestor-or-self |选取当前节点的所有先辈(父、祖父等)以及当前节点本身。 |
|attribute |选取当前节点的所有属性。 |
|child |选取当前节点的所有子元素。 |
|descendant |选取当前节点的所有后代元素(子、孙等)。 |
|descendant-or-self |选取当前节点的所有后代元素(子、孙等)以及当前节点本身。 |
|following |选取文档中当前节点的结束标签之后的所有节点。 |
|namespace |选取当前节点的所有命名空间节点。 |
|parent |选取当前节点的父节点。 |
|preceding |选取文档中当前节点的开始标签之前的所有节点。 |
|preceding-sibling |选取当前节点之前的所有同级节点。 |
|self |选取当前节点。 |
实际上轴的这些名称可以通过:`.` , `..` , `@` , `//` 表达出来,很少会使用这些名称。
### 节点测试(nodetest)
> 想了解更多,可以来了解[w3中关于note-tests详细说明](https://www.w3.org/TR/2017/REC-xpath-31-20170321/#node-tests)
定义:节点测试的另一种形式称为 种类测试,可以根据节点的种类,名称和类型注释选择节点。
种类测试的语法和语义在2.5.4 SequenceType语法和2.5.5 SequenceType中进行了描述。
在节点测试中使用同类测试时,仅选择指定轴上与种类测试匹配的那些节点。
下面显示的是可能在路径表达式中使用的种类测试的几个示例:
|节点测试名 | 含义|
| :----| :----|
|node() |匹配任何节点。 |
|text() |匹配任何文本节点。 |
|comment() |匹配任何评论节点。 |
|namespace-node() |匹配任何名称空间节点。 |
|element() |匹配任何元素节点。 |
|schema-element(person)|匹配,其名称是任何元素节点 person(或者是中置换组 为首person),其类型标注相同(或衍生自)声明的类型的的person 元素中的在范围内的元素声明。|
|element(person)|匹配名称为的任何元素节点 person,无论其类型注释如何。|
|element(person, surgeon)|匹配任何名称为person,类型注释为 surgeon或从中派生的非空元素节点surgeon。|
|element(*, surgeon)|匹配其类型注释为surgeon(或从中派生surgeon)的任何非修剪元素节点,无论其名称如何。|
|attribute() |匹配任何属性节点。 |
|attribute(price) |匹配属性名为price的属性节点,无论其类型注释如何。 |
|attribute(*,xs:decimal) |匹配任何类型注释为xs:decimal(或从中派生xs:decimal)的属性,无论其名称如何。 |
|document-node() |匹配任何文档节点。 |
|document-node(element(book)) |匹配任何内容由满足种类测试的 元素元素组成的文档节点,该元素元素element(book)与零个或多个注释和处理指令交织在一起。|
其中我们比较常用的可能就是`text()`,提取节点文本信息返回结果为`列表格式`(保留文本的空白符)。
另外需要说明的是`XPath`的`string(arg)`函数,这个函数返回节点内部的字符串信息,也就是返回了`字符串类型数据`。
我们来说下`text()`和`fn:string(arg)`的区别:
1. 含义不同: `text()`是`种类测试`,`string(arg)`是`XPath函数`,所以可以在`XPath`表达式中使用结合使用`text()`,而`string()`不能。
2. 返回结果集类型不同: `text()`返回的是文本列表类型(一个节点也会返回一个元素的列表),`string()`返回的是字符串类型。
### 位置路径表达式
位置路径可以是绝对的,也可以是相对的。
绝对路径起始于正斜杠( / ),而相对路径不会这样。在两种情况中,位置路径均包括一个或多个步,每个步均被斜杠分割:
绝对位置路径:
```
/step/step/...
```
相对位置路径:
```
step/step/...
```
每个步均根据当前节点集之中的节点来进行计算。
*** 步(step)包括:***
- 轴(axis) : 定义所选节点与当前节点之间的树关系
- 节点测试(node-test) : 识别某个轴内部的节点
- 零个或者更多谓语(predicate): 更深入地提炼所选的节点集
路径表达式中的一步(`step`)的语法:
```
轴名称::节点测试[谓语]
axisname::nodetest[predicate]
```
**实例**
|例子 |结果 |
| :----| :----|
|child::book |选取所有属于当前节点的子元素的 book 节点。 |
|attribute::lang |选取当前节点的 lang 属性。 |
|child:: * |选取当前节点的所有子元素。 |
|attribute:: * |选取当前节点的所有属性。 |
|child::text() |选取当前节点的所有文本子节点。 |
|child::node() |选取当前节点的所有子节点。 |
|descendant::book |选取当前节点的所有 book 后代。 |
|ancestor::book |选择当前节点的所有 book 先辈。 |
|ancestor-or-self::book |选取当前节点的所有 book 先辈以及当前节点(如果此节点是 book 节点) |
|child:: */child::price |选取当前节点的所有 price 孙节点。 |
## XPath运算符
> XPath 表达式可返回节点集、字符串、逻辑值以及数字。
有了运算符就可以构建逻辑表达式来复杂化我们的匹配条件了。
|运算符 |描述 | 实例 |返回值 |
| :----| :----| :----| :----|
|\| |计算两个节点集 |//book \| //cd |返回所有拥有 book 和 cd 元素的节点集 |
|+ |加法 |6 + 4 |10 |
|- |减法 |6 - 4 |2 |
|* |乘法 |6 * 4 |24 |
|div |除法 |8 div 4 |2 |
|= |等于 |price=9.80 |如果 price 是 9.80,则返回 true。如果 price 是 9.90,则返回 false。 |
|!= |不等于 |price!=9.80 |如果 price 是 9.90,则返回 true。如果 price 是 9.80,则返回 false。 |
|< |小于 |price<9.80 |如果 price 是 9.00,则返回 true。如果 price 是 9.90,则返回 false。 |
|<= |小于或等于 |price<=9.80 |如果 price 是 9.00,则返回 true。如果 price 是 9.90,则返回 false。 |
|> |大于 |price>9.80 |如果 price 是 9.90,则返回 true。如果 price 是 9.80,则返回 false。 |
|>= |大于或等于 |price>=9.80 |如果 price 是 9.90,则返回 true。如果 price 是 9.70,则返回 false。 |
|or |或 |price=9.80 or price=9.70 |如果 price 是 9.80,则返回 true。如果 price 是 9.50,则返回 false。 |
|and |与 |price>9.00 and price<9.90 |如果 price 是 9.80,则返回 true。如果 price 是 8.50,则返回 false。 |
|mod |计算除法的余数 |5 mod 2 |1 |
---
## XPath函数
1. 模糊查询`fn:contains(string1,string2)` :如果 string1 包含 string2,则返回 true,否则返回 false。
2. 小写转换`fn:lower-case(string)` : 把 string 参数转换为小写。
3. 字符翻译`fn:translate(string1,string2,string3)`, 把 string1 中的 string2 替换为 string3。 例子:translate('12:30','0123','abcd'),结果:'bc:da'。
4. 字符串替换:`fn:replace(string,pattern,replace)`, 把指定的模式替换为 replace 参数,并返回结果。例子:replace("Bella Italia", "l", "\*") 结果:'Be\*\*a Ita\*ia'。
5. 字符串转换函数`fn:string(arg)` , 返回参数的字符串值。参数可以是`数字`、`逻辑值`或`节点集`。
更多函数可以访问[w3schools_xsl_functions](https://www.w3schools.com/xml/xsl_functions.asp)查看。
学到这里,如果怕记不住那就多练习,还可以记住这个 [XPath cheetsheet](https://www.learnhard.cn/cheetsheet/xpath.html) 网页,需要的时候快速查看一下。
## XPath实例练习
1. 按照节点属性定位
```
//a[text()='登录']
//div[contains(@class,'blog-content-box')]
//span[@id='name' or text()='name']
```
2. 提取某节点下所有文本信息
例如: `<div id="test2">美女,<font color=red>你的微信是多少?</font><div>`
```
# 获取字符串数据("美女,你的微信是多少")
data = selector.xpath('//div[@id="test2"]')[0]
info = data.xpath('string(.)')
# 获取字符串列表["美女,","你的微信是多少"]
info = selector.xpath('//div[@id="test2"]/text()')
```
3. 取属性值(`@attr_name`)
```
# 获取超链接的属性href地址
value1 = html.xpath('//a/@href')
value2 = html.xpath('//img/@src')
value3 = html.xpath('//div[2]/span/@id')
```
- 课程大纲
- 入门篇
- 爬虫是什么
- 为什么要学习爬虫
- 爬虫的基本原理
- TCP/IP协议族的基本知识
- HTTP协议基础知识
- HTML基础知识
- HTML_DOM基础知识
- urllib3库的基本使用
- requests库的基本使用
- Web页面数据解析处理方法
- re库正则表达式的基础使用
- CSS选择器参考手册
- XPath快速了解
- 实战练习:百度贴吧热议榜
- 进阶篇
- 服务端渲染(CSR)页面抓取方法
- 客户端渲染(CSR)页面抓取方法
- Selenium库的基本使用
- Selenium库的高级使用
- Selenium调用JavaScript方法
- Selenium库的远程WebDriver
- APP移动端数据抓取基础知识
- HTTP协议代理抓包分析方法
- Appium测试Android应用基础环境准备
- Appium爬虫编写实战学习
- Appium的元素相关的方法
- Appium的Device相关操作方法
- Appium的交互操作方法
- 代理池的使用与搭建
- Cookies池的搭建与用法
- 数据持久化-数据库的基础操作方法(mysql/redis/mongodb)
- 执行JS之execjs库使用
- 高级篇
- Scrapy的基本知识
- Scrapy的Spider详细介绍
- Scrapy的Selector选择器使用方法
- Scrapy的Item使用方法
- Scrapy的ItemPipeline使用方法
- Scrapy的Shell调试方法
- Scrapy的Proxy设置方法
- Scrapy的Referer填充策略
- Scrapy的服务端部署方法
- Scrapy的分布式爬虫部署方法
- Headless浏览器-pyppeteer基础知识
- Headless浏览器-pyppeteer常用的设置方法
- Headless浏览器-反爬应对办法
- 爬虫设置技巧-UserAgent设置
- 反爬策略之验证码处理方法
- 反爬识别码之点击文字图片的自动识别方法
- 反爬字体处理方法总结
- 防止反爬虫的设置技巧总结
- 实战篇
- AJAX接口-CSDN技术博客文章标题爬取
- AJAX接口-拉购网职位搜索爬虫
- 执行JS示例方法一之动漫图片地址获取方法
- JS执行方法示例二完整mangabz漫画爬虫示例
- 应用实践-SOCKS代理池爬虫
- 落霞小说爬虫自动制作epub电子书
- 一种简单的适用于分布式模式知乎用户信息爬虫实现示例
- 法律安全说明