[TOC]
# Python爬虫抓取实战一百度贴吧热议榜
> 下面示例比较简单,主要说明下如何查找AJAX数据接口。
1. 打开`Chrome`浏览器 ,按`F12`显示开发者工具,然后访问`https://tieba.baidu.com`网站
2. 找到`Network`页,选中`Filter`漏斗图标,此时可以看到"All|XHR|JS|...."不同类型文件的选择,我们选中`XHR`。
3. 此时下面的URL列表中有个`topicList`,选中后,右侧显示"Preview"预览内容为`JSON`数据,这里正是我们看到的热门话题`Top30`。
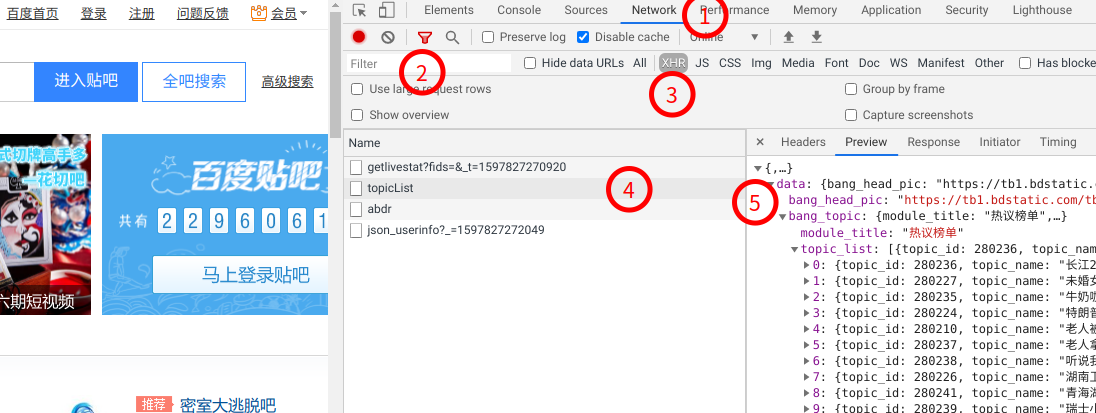
找到这里,我们就定位到了数据源请求链接地址为: `https://jump.bdimg.com/hottopic/browse/topicList` , 接下来我们就是通过`Python`脚本访问并获取响应数据。
```Python
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import requests as req
import html
headers = {
'user-agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36',
}
# 获取贴吧信息:
# 排名序号|标题|摘要|热度|链接图片
def tieba_hot():
url='https://jump.bdimg.com/hottopic/browse/topicList'
# JSON数据接口
resp = req.get(url, headers = headers)
data = resp.json()
topic_list = data['data']['bang_topic']['topic_list']
for topic in topic_list:
topic_url = html.unescape(topic['topic_url'])
print('{} |{}|{}\n'.format(topic['idx_num'],topic['topic_name'],topic_url))
if __name__ == '__main__':
tieba_hot()
```
`requests`库请求返回的结果数据是`json`格式数据,我们可以通过`json()`方法提取为`Python`字典类型的数据结果。
然后对话题列表提取`话题排名`、`话题内容`和对应的`URL`地址信息。
**说明:**
`topic_url`中的`\&`字符被转义为`\&`,需要对`HTML实体`进行`反转义`处理,否则访问URL会无法正确访问。
我们使用`html.unescape()`方法来处理一下,只需要将`topic['topic_url']` 改成 `html.unescape(topic['topic_url'])` 即可,其他字段不变。
关于`HTML实体字符转换`的`HTML库`实现源码可以点击这里查看 [Lib/html/__init__.py](https://github.com/python/cpython/blob/3.8/Lib/html/__init__.py)
- 课程大纲
- 入门篇
- 爬虫是什么
- 为什么要学习爬虫
- 爬虫的基本原理
- TCP/IP协议族的基本知识
- HTTP协议基础知识
- HTML基础知识
- HTML_DOM基础知识
- urllib3库的基本使用
- requests库的基本使用
- Web页面数据解析处理方法
- re库正则表达式的基础使用
- CSS选择器参考手册
- XPath快速了解
- 实战练习:百度贴吧热议榜
- 进阶篇
- 服务端渲染(CSR)页面抓取方法
- 客户端渲染(CSR)页面抓取方法
- Selenium库的基本使用
- Selenium库的高级使用
- Selenium调用JavaScript方法
- Selenium库的远程WebDriver
- APP移动端数据抓取基础知识
- HTTP协议代理抓包分析方法
- Appium测试Android应用基础环境准备
- Appium爬虫编写实战学习
- Appium的元素相关的方法
- Appium的Device相关操作方法
- Appium的交互操作方法
- 代理池的使用与搭建
- Cookies池的搭建与用法
- 数据持久化-数据库的基础操作方法(mysql/redis/mongodb)
- 执行JS之execjs库使用
- 高级篇
- Scrapy的基本知识
- Scrapy的Spider详细介绍
- Scrapy的Selector选择器使用方法
- Scrapy的Item使用方法
- Scrapy的ItemPipeline使用方法
- Scrapy的Shell调试方法
- Scrapy的Proxy设置方法
- Scrapy的Referer填充策略
- Scrapy的服务端部署方法
- Scrapy的分布式爬虫部署方法
- Headless浏览器-pyppeteer基础知识
- Headless浏览器-pyppeteer常用的设置方法
- Headless浏览器-反爬应对办法
- 爬虫设置技巧-UserAgent设置
- 反爬策略之验证码处理方法
- 反爬识别码之点击文字图片的自动识别方法
- 反爬字体处理方法总结
- 防止反爬虫的设置技巧总结
- 实战篇
- AJAX接口-CSDN技术博客文章标题爬取
- AJAX接口-拉购网职位搜索爬虫
- 执行JS示例方法一之动漫图片地址获取方法
- JS执行方法示例二完整mangabz漫画爬虫示例
- 应用实践-SOCKS代理池爬虫
- 落霞小说爬虫自动制作epub电子书
- 一种简单的适用于分布式模式知乎用户信息爬虫实现示例
- 法律安全说明