[TOC]
# HTTP协议基础知识
了解了`TCP/IP协议族`分层结构后,我们可以学习`HTTP`协议了。
`HTTP`协议属于`应用层`的协议,协议定义的是`客户端`与`服务端`之间通信的数据报文格式,接下来一步一步的学习具体的报文格式及其作用。
成就非凡的侠客,不能只看图练招式,还有`内功心法`。
`HTTP`协议格式就是踏入江湖的第一段`内功心法`。没有它你就很难立足于`Web江湖`。**谨记:耐心!**
## HTTP协议格式
要学习HTTP协议格式,需要分别从下面两个部分了解HTTP协议格式:
1. 请求报文-Request : 客户端/浏览器 发送给 服务端 的报文
2. 应答报文-Response: 服务端 返回给 客户端/浏览器 的报文
**我们来通过下面HTTP交互过程来了解报文格式发送过程:**
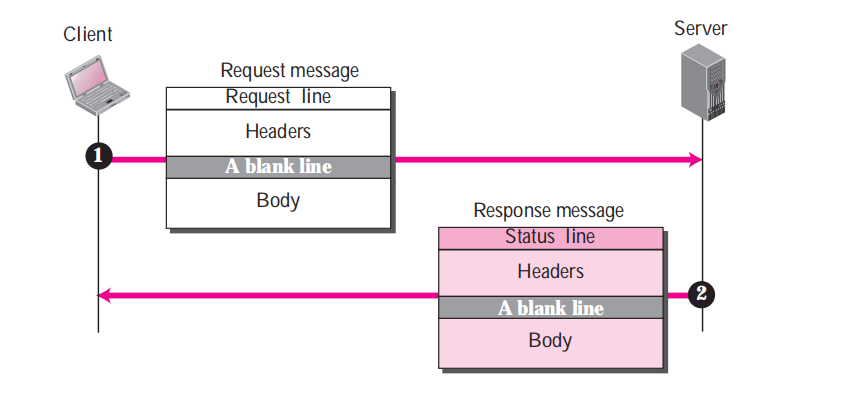
从图中可以看到两种报文发送流程很简单:
- 第一步:客户端/浏览器 发送给 服务端 一条`Request`请求报文,告诉服务器,我要浏览页面"www.example.com/index.html"
- 第二步:服务器 返回给 客户端/浏览器 一条`Response`应答报文,告诉客户端,好的!接收吧,这是你要的数据。
就这样,一次愉快的请求和应答完成了。
---
愉快归愉快,可是浏览器向服务器发送了哪些数据呢?
如果连这点都不清楚,那就没办法成为一名合格的虫师啦。
所谓知己知彼,连这个`知己`都还没搞清楚,何以闯荡**江湖**...
好啦! `耐心`的将两种格式(`心法`)记住,达到`倒背如流`的程度吧!
### Request请求报文格式
> `Request`请求报文就是我们的浏览器发送给服务器的数据格式
**Request请求报文格式如下:**
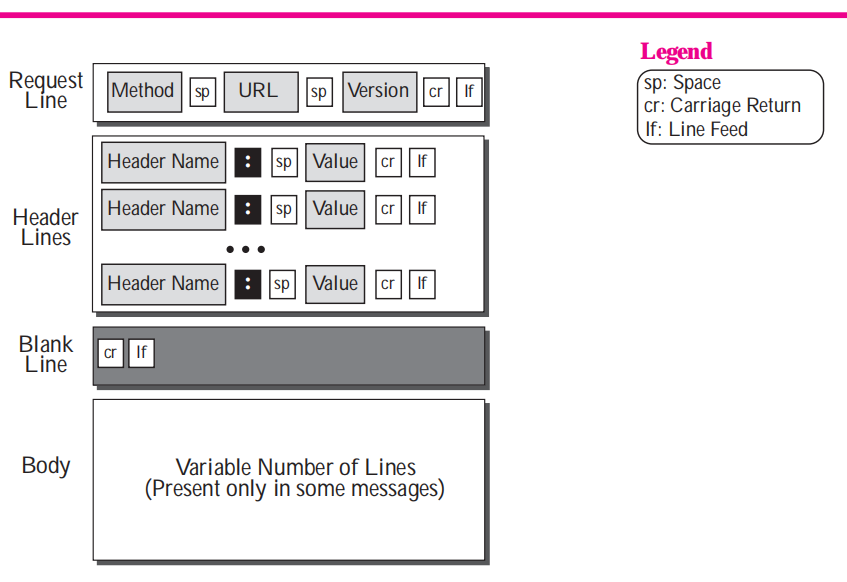
格式其实很简单,主要分成三部分:
- `请求行(RequestLine) `: 包含请求方法、请求资源位置和协议版本信息。
- `头部(Headers)`: 可能多行,以读到一个空行(一行内容为"\r\n")为结束标识。
- `实体正文(Body)`:这里就是实际的请求参数信息或者传输数据,如果不传数据可以没有实体部分。
#### HTTP协议版本-Version
> 版本号字段虽然对一名虫师来说不常用,但是对于历史的变迁与未来的方向都可以在版本中映射出他们在**江湖**中的故事。
- `HTTP/0.9`: 1991年,第一个版本,已过时。
- `HTTP/1.0`: 1996年,第二个版本,替代0.9版本,仍在使用中,仅支持`GET`、`HEAD`和`POST`三种方法。
- `HTTP/1.1`: 1997年,第三个版本,目前使用最为广泛,新增`OPTIONS`,`PUT`,`DELETE`,`TRACE`和`CONNECT`五种方法,默认支持长连接(`keep-alive`),支持分块传输编码。
- `HTTP/2.0`: 2015年5月14日发布`RFC7540`文档,第四个版本,几乎所有的Web浏览器和主要的Web服务器都通过使用应用程序层协议协商(ALPN)扩展的传输层安全性(TLS)来支持,其中需要TLS 1.2或更高版本(**强制性加密支持**)。值得一提的是这个协议参考了Google的`SPDY协议`。增加了对头部基于`霍夫曼编码`压缩的支持,支持TCP连接的多路复用,极大的降低网络延迟和传输数据量。 [维基百科 HTTP/2.0](https://en.wikipedia.org/wiki/HTTP/2)
- `HTTP/3.0`: 2018年被提出,第五个版本,2019年9月Google的Chrome浏览器(79)稳定版本中可以启用。在HTTP/3中,将传输层的`TCP协议`改为使用基于UDP协议的`QUIC(快速UDP网络连接)`协议实现。而这种改动设计最初也来自`Google`。[维基百科 HTTP/3.0](https://en.wikipedia.org/wiki/HTTP/3)
虽然版本在提升,但是协议的格式并没有发生改变,改变的仅仅是压缩算法和传输协议。这对于我们来学习分析格式是没有任何影响的。
#### `HTTP协议`请求方法-Method

#### `HTTP协议`请求Web地址-URL
> 我们常说的网页地址,通常就是指`URL`地址,而`URL`地址格式其实是统一资源标识符`URI`的一种特定形式,例如 "http://www.example.com/index.html" 表示 访问主机"www.example.com"上的`index.html`文件。
看似简单的`URL`其实包含了一种标准格式`URI`的规范:
```
URI = scheme:[//authority]path[?query][#fragment]
authority = [userinfo@]host[:port]
```

- `schema`: 标识协议类型,例如 http/https/ftp/mailto/jdbc
- `authority` : 认证访问信息,以"//"开头,包括主机地址`host`,可选端口,可选的用户信息`userinfo`(用户密码认证信息)
- `path` : 访问资源路径,以"/"开始表示绝对路径,每层目录都使用"/"分割。
- `query`: 查询条件参数设置,前面以"?"开头,每个条件参数格式为"key=value",相邻参数以"&"符号分割开,例如"/get_proxy?check_count=100&type=http"
- `fragment`: 分片ID, 以"#"开头,通常在`web`页面中用来同一页面的目录导航快速定位章节位置。
下面的示例都是`URL`地址:
```
http://www.example.com:8080/admin/login.html
http://www.example.com/query/?q=spider
ftp://ftpuser:ftppass@www.example.com:21
```
> 注: 以后了解了数据访问知识后,你会发现`URI`格式不仅仅用于访问`Web页面`(http),访问`数据库`(odbc,jdbc)、`FTP`(ftp)以及`邮箱`(mailto)都是可以使用的。
#### `HTTP协议` 的请求首部-Headers

#### HTTP协议请求报文示例
> Wireshark是抓包、分析消息的利器,作为虫师必备,下图即一条访问`http://localhost:5030/get/?check_count=100`请求示例。
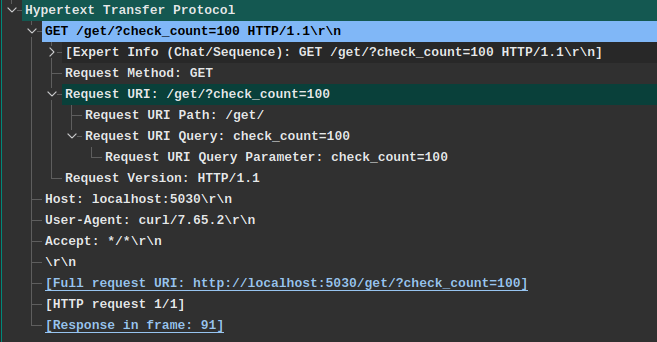
在这条HTTP请求报文中,客户端向服务器发送了这些信息:
- `Method`方法: `GET`
- `URL`请求路径: `/get/?check_count=100` ,实际请求需要结合`Host`字段为完整的URI地址。
- `HTTP版本信息`: `HTTP/1.1`
- `Host`请求服务器主机(如果有端口会附带端口): `localhost:5030`
- `User-Agent`客户端程序标识: `curl/7.65.2`,因为这是我使用`curl`命令发出的请求。
- `Accept`接收媒体格式: `*/*`支持服务端返回任意格式数据.
当这条请求发给`服务器`后,服务器就会知道 一个来自`curl/7.65.2`客户端请求`/get/`位置数据,请求参数为`check_count=100`,并且客户端支持接收任意格式的数据内容。
---
### Response应答报文格式
> 学习应答报文协议格式后我们可以了解服务器给我们回答的报文数据格式以及包含了哪些字段信息,以及这些字段都表达了服务器的什么含义,这样我们对返回结果可以理解的更加透彻。方便我们在遇到问题时来分析原因。
**Response 应答报文格式**
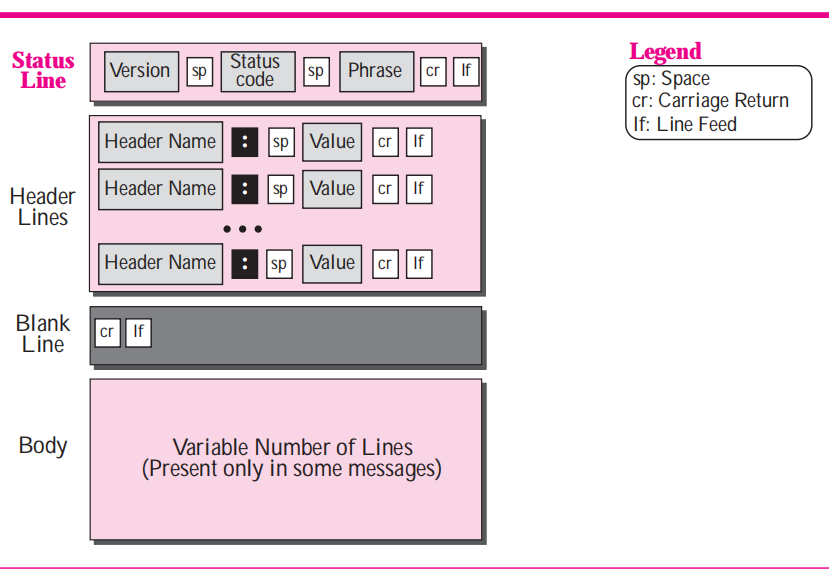
#### 应答返回状态码-`Status Code`
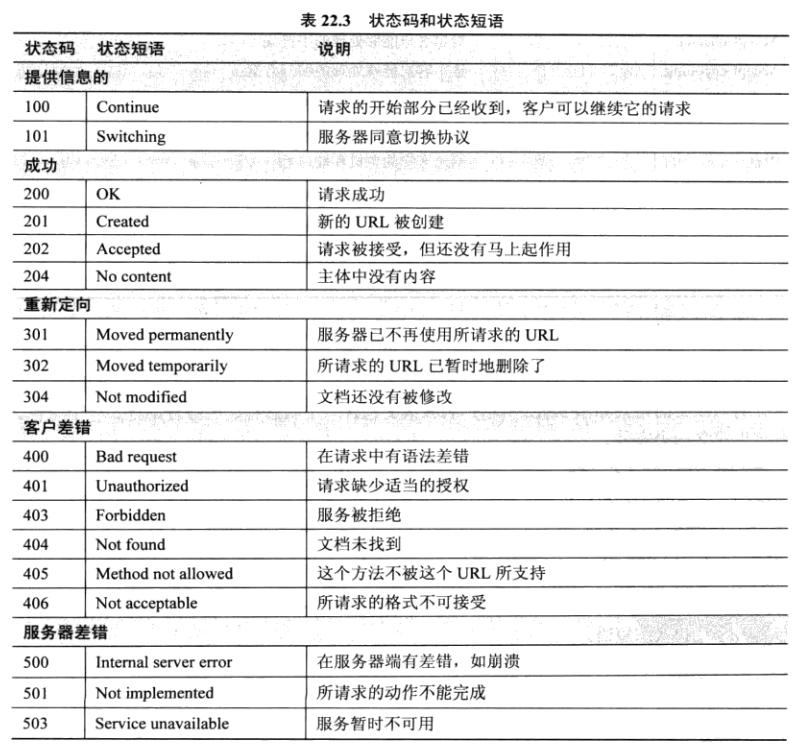
**常见的状态码有:**
- `200`-请求成功。
- `302`-服务请求临时重定向到新URL地址。
- `404`-请求地址无法找到或请求错误都会返回404.
- `503`-服务暂时不可用,可能服务器应答超时或者出了其他内部问题。
#### 应答返回的头部信息-Headers

#### HTTP协议应答报文示例
> 这段消息是上面请求报文的应答报文,都是来自Wireshark抓包结果。
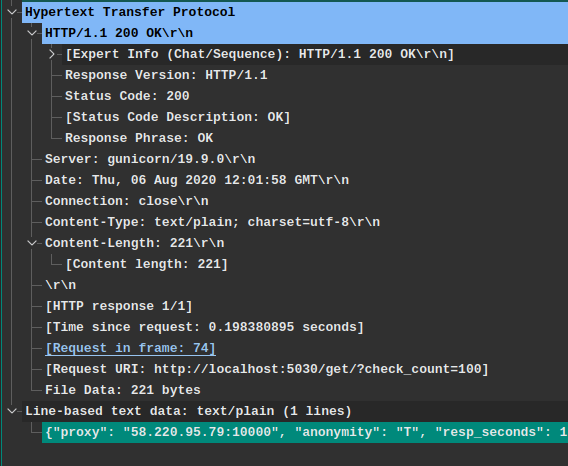
从这条HTTP报文可以了解到:
- HTTP协议版本(`Response Version`): HTTP/1.1
- 状态码(`Status Code`): 200
- 服务器软件(`Server`): gunicorn/19.9.0
- 响应时间(`Date`): "Thu, 06 Aug 2020 12:01:58 GMT"
- TCP链接状态(`Connection`): 关闭状态(不是长连接)
- 返回的内容类型(`Content-Type`): "text/plain; charset=utf-8" 文本类型,并且使用`utf-8`编码规则
- 返回的内容长度(`Content-Length`): 221字节
- 文本内容(空行"\r\n"后面的内容): "{proxy:....}"
>注意: 这里看到的一些信息是`Wireshark`软件的辅助解释信息,比如 `Request in frame:74` 这并不是此报文包含的信息,而是`Wireshark`根据TCP请求序号关联的一次消息交互结果,这个关联结果意思是此应答报文对应抓包文件中的第`74`帧的请求,双击后我们就可以跳到请求帧查看客户端发出的请求内容。如下图所示:

## 总结
看到这里,表明你已经了解了`HTTP`协议的两种报文格式。
可以自我练习一下,使用Wireshark工具监听本机的浏览器访问某个网站过程中的交互过程。
你会发现,`HTTP`协议网站交互内容一览无余,而使用`HTTPS`协议的网站交互内容是无法查看,这就是加密的作用。
## HTTPS协议-安全的HTTP协议
> HTTP基础上加了TLS传输安全层,这个层通过浏览器和服务器的协商掌握一个只有两人知道的对称加密秘钥key,使用key对明文的`HTTP`内容加密传输。
对于秘钥协商的过程简单来说就是:
1. 服务端先发送公钥给浏览器
2. 浏览器使用公钥加密自己的`key`,并传回服务端
3. 服务端使用私钥解密,获得浏览器的`key`。
4. 二者开心的使用`key`加密数据实现安全交互。
这里服务端的`公钥`和`私钥`是一对`非对称加密类型`秘钥,谁都可以知道`公钥`并使用它加密数据,但是`私钥`只有服务端自己保存。
使用`公钥`解密的数据只能被对应的`私钥`解密,而不能被`公钥`解密。这样就保证了网络数据的安全。
但是`非对称加密`方式加密长文本数据相对与`对称加密`算法较慢,这又是它的劣势,因此`HTTPS`同时使用了这两种算法。
1. 使用`非对称加密`算法传递`对称加密`算法的秘钥。
2. 使用共享后的`对称加密`算法`秘钥`进行数据加密、解密。
下面图片是`Wireshark`分析的一段`HTTPS`握手协商交换秘钥的过程:
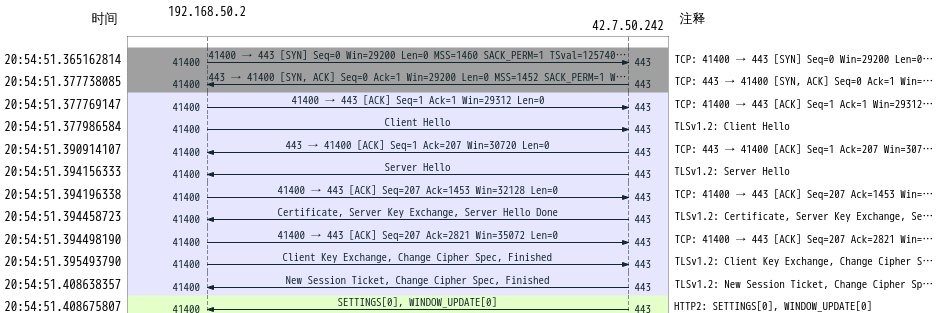
具体过程就不细说了,接下来我们说一下如何使用`Wireshark`查看解密后的`HTTPS`协议的报文内容。
### Wireshark抓包解析HTTPS消息方法
> 下面方法是记录对称加密算法中的两个随机数,生成对称加密算法的关键参数,知道了这两个参数就可以生成对称秘钥并解密`HTTPS`协议报文。
1. 环境变量设置: `export SSLKEYLOGFILE="~/.sslkeylogfile.txt"`
2. 命令行执行`chrome`或者其他浏览器都可以。随便访问一个`HTTPS`协议网站就会保存sslkey到文件中
3. 使用`SSLKEYLOGFILE`变量指定文件到`Wireshark`中设置一下,设置方法为: `菜单栏Edit` ==> `Preferences` ==> `Protocols` ==> `TLS`,找到`(Pre)-Master-Secretlog filename`中选择刚才设置的`~/.sslkeylogfile.txt`文件,点击确定。
此时再看看监听获取的`HTTPS`消息是不是已经被解密了呢?
---
~END~
- 课程大纲
- 入门篇
- 爬虫是什么
- 为什么要学习爬虫
- 爬虫的基本原理
- TCP/IP协议族的基本知识
- HTTP协议基础知识
- HTML基础知识
- HTML_DOM基础知识
- urllib3库的基本使用
- requests库的基本使用
- Web页面数据解析处理方法
- re库正则表达式的基础使用
- CSS选择器参考手册
- XPath快速了解
- 实战练习:百度贴吧热议榜
- 进阶篇
- 服务端渲染(CSR)页面抓取方法
- 客户端渲染(CSR)页面抓取方法
- Selenium库的基本使用
- Selenium库的高级使用
- Selenium调用JavaScript方法
- Selenium库的远程WebDriver
- APP移动端数据抓取基础知识
- HTTP协议代理抓包分析方法
- Appium测试Android应用基础环境准备
- Appium爬虫编写实战学习
- Appium的元素相关的方法
- Appium的Device相关操作方法
- Appium的交互操作方法
- 代理池的使用与搭建
- Cookies池的搭建与用法
- 数据持久化-数据库的基础操作方法(mysql/redis/mongodb)
- 执行JS之execjs库使用
- 高级篇
- Scrapy的基本知识
- Scrapy的Spider详细介绍
- Scrapy的Selector选择器使用方法
- Scrapy的Item使用方法
- Scrapy的ItemPipeline使用方法
- Scrapy的Shell调试方法
- Scrapy的Proxy设置方法
- Scrapy的Referer填充策略
- Scrapy的服务端部署方法
- Scrapy的分布式爬虫部署方法
- Headless浏览器-pyppeteer基础知识
- Headless浏览器-pyppeteer常用的设置方法
- Headless浏览器-反爬应对办法
- 爬虫设置技巧-UserAgent设置
- 反爬策略之验证码处理方法
- 反爬识别码之点击文字图片的自动识别方法
- 反爬字体处理方法总结
- 防止反爬虫的设置技巧总结
- 实战篇
- AJAX接口-CSDN技术博客文章标题爬取
- AJAX接口-拉购网职位搜索爬虫
- 执行JS示例方法一之动漫图片地址获取方法
- JS执行方法示例二完整mangabz漫画爬虫示例
- 应用实践-SOCKS代理池爬虫
- 落霞小说爬虫自动制作epub电子书
- 一种简单的适用于分布式模式知乎用户信息爬虫实现示例
- 法律安全说明