
[TOC]
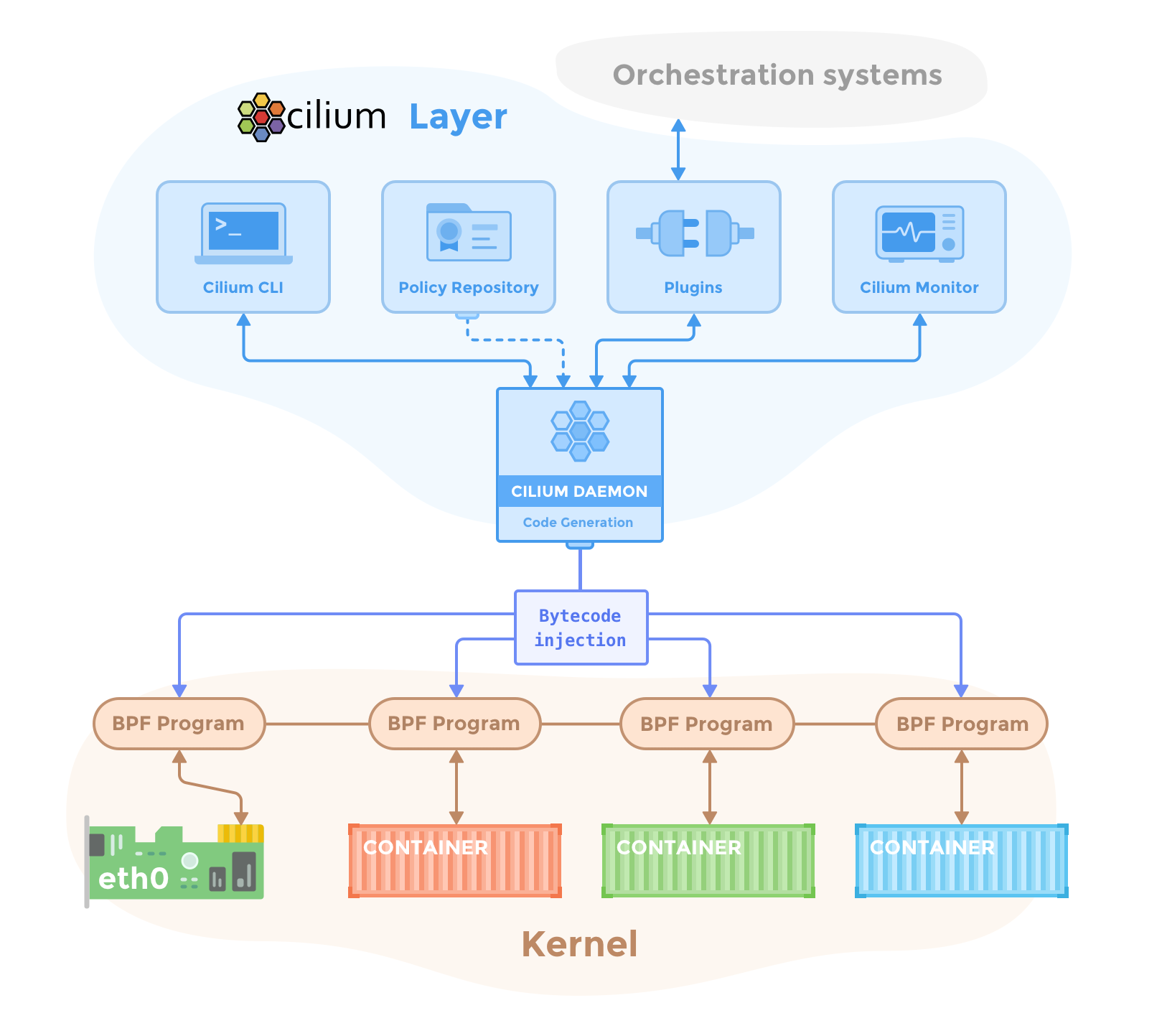
Cilium 和 Hubble 的部署由在集群中运行的以下组件组成:
# Cilium
## Agent
Cilium 代理(cilium-agent)在集群中的每个节点上运行。 在较高级别上,代理通过 Kubernetes 或 API 接受配置,这些配置描述了网络、服务负载平衡、网络策略以及可见性和监控要求。
Cilium 代理侦听来自 Kubernetes 等编排系统的事件,以了解容器或工作负载何时启动和停止。 它管理 Linux 内核用来控制这些容器进出的所有网络访问的 eBPF 程序。
## Client (CLI)
Cilium CLI 客户端 (cilium) 是与 Cilium 代理一起安装的命令行工具。 它与在同一节点上运行的 Cilium 代理的 REST API 进行交互。 CLI 允许检查本地代理的状态和状况。 它还提供了直接访问 eBPF 映射以验证其状态的工具。
>[info] 此处描述的代理内 Cilium CLI 客户端不应与用于在 Kubernetes 集群上快速安装、管理 Cilium 和进行故障排除的命令行工具混淆,后者也称为 cilium。 该工具通常安装在远离集群的地方,并使用 kubeconfig 信息通过 Kubernetes API 访问在集群上运行的 Cilium。
## Operator
Cilium Operator 负责管理集群中的职责,逻辑上应该为整个集群处理一次,而不是为集群中的每个节点处理一次。 Cilium 运营商并不处于任何转发或网络策略决策的关键路径中。 如果 Operator 暂时不可用,集群通常会继续运行。 但是,根据配置的不同,Operator 的可用性故障可能会导致:
- 如果需要 Cilium Operator 分配新的 IP 地址,IP 地址管理 (IPAM) 会出现延迟,从而导致新工作负载的调度出现延迟
- 未能更新 kvstore 心跳密钥将导致代理声明 kvstore 不健康并重新启动。
## CNI Plugin
当 pod 在节点上调度或终止时,Kubernetes 会调用 CNI 插件 (cilium-cni)。 它与节点的 Cilium API 交互,触发必要的数据路径配置,为 pod 提供网络、负载平衡和网络策略。
# Hubble
## Server
Hubble 服务器在每个节点上运行,并从 Cilium 检索基于 eBPF 的可见性。 它被嵌入到 Cilium 代理中以实现高性能和低开销。 它提供 gRPC 服务来检索流和 Prometheus 指标。
## Relay
Relay (hubble-relay) 是一个独立组件,它了解所有正在运行的 Hubble 服务器,并通过连接到各自的 gRPC API 并提供代表集群中所有服务器的 API 来提供集群范围内的可见性。
## Client (CLI)
Hubble CLI (hubble) 是一个命令行工具,能够连接到 hubble-relay 的 gRPC API 或本地服务器来检索流事件。
## Graphical UI (GUI)
图形用户界面 (hubble-ui) 利用基于中继的可见性来提供图形服务依赖关系和连接图。
# eBPF
eBPF 是一个 Linux 内核字节码解释器,最初是为了过滤网络数据包而引入的,例如 tcpdump 和套接字过滤器。 此后,它已通过附加数据结构(例如哈希表和数组)以及附加操作进行了扩展,以支持数据包修改、转发、封装等。内核内验证器可确保 eBPF 程序安全运行,并且 JIT 编译器可转换字节码 CPU 架构特定指令以提高本机执行效率。 eBPF 程序可以在内核中的各个挂钩点运行,例如针对传入和传出数据包。
Cilium 能够探测 Linux 内核的可用功能,并在检测到更新的功能时自动使用它们。
# Data Store
Cilium 需要数据存储来在代理之间传播状态。 它支持以下数据存储:
1. Kubernetes CRDs (Default)
存储任何数据和传播状态的默认选择是使用 Kubernetes 自定义资源定义 (CRD)。 CRD 由 Kubernetes 为集群组件提供,以通过 Kubernetes 资源表示配置和状态。
2. Key-Value Store
状态存储和传播的所有要求都可以通过 Cilium 默认配置中配置的 Kubernetes CRD 来满足。 可以选择将键值存储用作优化,以提高集群的可扩展性,因为通过直接使用键值存储,更改通知和存储要求会更加高效。
目前支持的键值存储有:etcd
> 可以直接利用 Kubernetes 的 etcd 集群,也可以维护专用的 etcd 集群。
- 前言
- 架构
- 部署
- kubeadm部署
- kubeadm扩容节点
- 二进制安装基础组件
- 添加master节点
- 添加工作节点
- 选装插件安装
- Kubernetes使用
- k8s与dockerfile启动参数
- hostPort与hostNetwork异同
- 应用上下线最佳实践
- 进入容器命名空间
- 主机与pod之间拷贝
- events排序问题
- k8s会话保持
- 容器root特权
- CNI插件
- calico
- calicoctl安装
- calico网络通信
- calico更改pod地址范围
- 新增节点网卡名不一致
- 修改calico模式
- calico数据存储迁移
- 启用 kubectl 来管理 Calico
- calico卸载
- cilium
- cilium架构
- cilium/hubble安装
- cilium网络路由
- IP地址管理(IPAM)
- Cilium替换KubeProxy
- NodePort运行DSR模式
- IP地址伪装
- ingress使用
- nginx-ingress
- ingress安装
- ingress高可用
- helm方式安装
- 基本使用
- Rewrite配置
- tls安全路由
- ingress发布管理
- 代理k8s集群外的web应用
- ingress自定义日志
- ingress记录真实IP地址
- 自定义参数
- traefik-ingress
- traefik名词概念
- traefik安装
- traefik初次使用
- traefik路由(IngressRoute)
- traefik中间件(middlewares)
- traefik记录真实IP地址
- cert-manager
- 安装教程
- 颁布者CA
- 创建证书
- 外部存储
- 对接NFS
- 对接ceph-rbd
- 对接cephfs
- 监控平台
- Prometheus
- Prometheus安装
- grafana安装
- Prometheus配置文件
- node_exporter安装
- kube-state-metrics安装
- Prometheus黑盒监控
- Prometheus告警
- grafana仪表盘设置
- 常用监控配置文件
- thanos
- Prometheus
- Sidecar组件
- Store Gateway组件
- Querier组件
- Compactor组件
- Prometheus监控项
- grafana
- Querier对接grafana
- alertmanager
- Prometheus对接alertmanager
- 日志中心
- filebeat安装
- kafka安装
- logstash安装
- elasticsearch安装
- elasticsearch索引生命周期管理
- kibana安装
- event事件收集
- 资源预留
- 节点资源预留
- imagefs与nodefs验证
- 资源预留 vs 驱逐 vs OOM
- scheduler调度原理
- Helm
- Helm安装
- Helm基本使用
- 安全
- apiserver审计日志
- RBAC鉴权
- namespace资源限制
- 加密Secret数据
- 服务网格
- 备份恢复
- Velero安装
- 备份与恢复
- 常用维护操作
- container runtime
- 拉取私有仓库镜像配置
- 拉取公网镜像加速配置
- runtime网络代理
- overlay2目录占用过大
- 更改Docker的数据目录
- Harbor
- 重置Harbor密码
- 问题处理
- 关闭或开启Harbor的认证
- 固定harbor的IP地址范围
- ETCD
- ETCD扩缩容
- ETCD常用命令
- ETCD数据空间压缩清理
- ingress
- ingress-nginx header配置
- kubernetes
- 验证yaml合法性
- 切换KubeProxy模式
- 容器解析域名
- 删除节点
- 修改镜像仓库
- 修改node名称
- 升级k8s集群
- 切换容器运行时
- apiserver接口
- 其他
- 升级内核
- k8s组件性能分析
- ETCD
- calico
- calico健康检查失败
- Harbor
- harbor同步失败
- Kubernetes
- 资源Terminating状态
- 启动容器报错