
实时数仓主要是为了解决传统数仓数据时效性低的问题,实时数仓通常会用在实时的OLAP分析、实时的数据看板、业务指标实时监控等场景。虽然关于实时数仓的架构及技术选型与传统的离线数仓会存在差异,但是关于数仓建设的基本方法论是一致的。本文会分享基于Flink SQL从0到1搭建一个实时数仓的demo,涉及数据采集、存储、计算、可视化整个处理流程。通过本文你可以了解到:
* 实时数仓的基本架构
* 实时数仓的数据处理流程
* Flink1.11的SQL新特性
* Flink1.11存在的bug
* 完整的操作案例
> 古人学问无遗力,少壮工夫老始成。
>
> 纸上得来终觉浅,绝知此事要躬行。
## 案例简介
本文会以电商业务为例,展示实时数仓的数据处理流程。另外,本文旨在说明实时数仓的构建流程,所以不会涉及太复杂的数据计算。为了保证案例的可操作性和完整性,本文会给出详细的操作步骤。为了方便演示,本文的所有操作都是在Flink SQL Cli中完成的。
## 架构设计
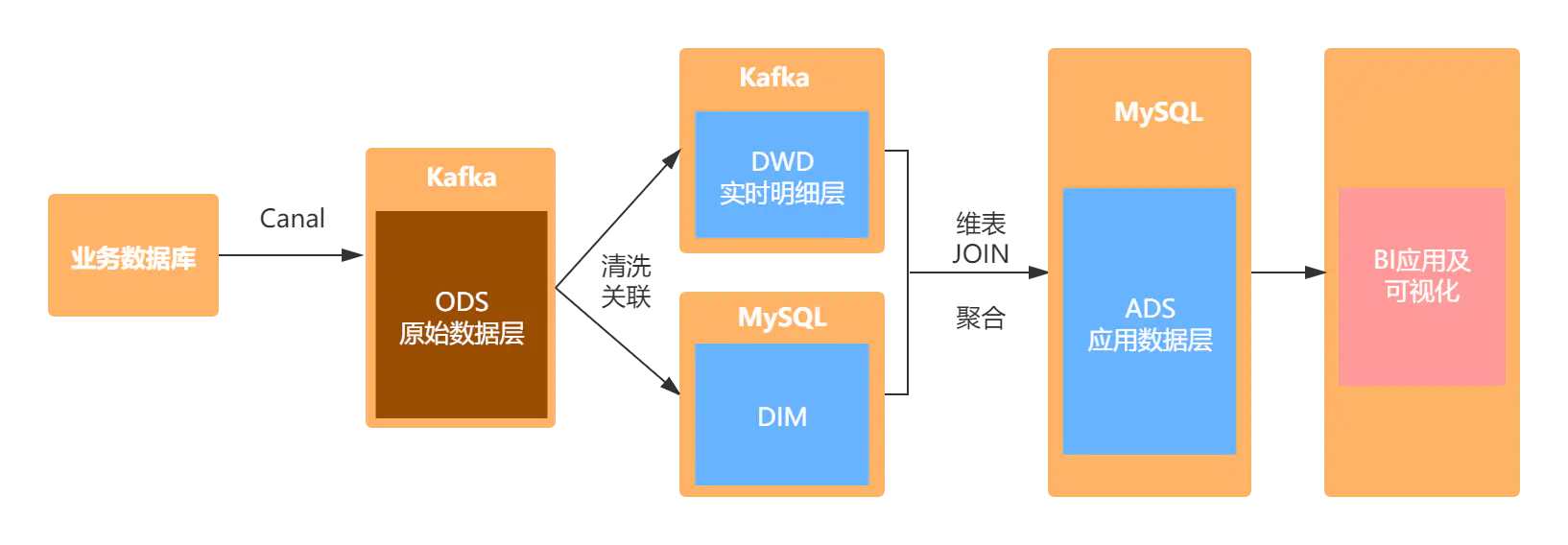
具体的架构设计如图所示:首先通过canal解析MySQL的binlog日志,将数据存储在Kafka中。然后使用Flink SQL对原始数据进行清洗关联,并将处理之后的明细宽表写入kafka中。维表数据存储在MySQL中,通过Flink SQL对明细宽表与维表进行JOIN,将聚合后的数据写入MySQL,最后通过FineBI进行可视化展示。
image
## 业务数据准备
* 订单表(order\_info)
~~~sql
CREATE TABLE `order_info` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '编号',
`consignee` varchar(100) DEFAULT NULL COMMENT '收货人',
`consignee_tel` varchar(20) DEFAULT NULL COMMENT '收件人电话',
`total_amount` decimal(10,2) DEFAULT NULL COMMENT '总金额',
`order_status` varchar(20) DEFAULT NULL COMMENT '订单状态',
`user_id` bigint(20) DEFAULT NULL COMMENT '用户id',
`payment_way` varchar(20) DEFAULT NULL COMMENT '付款方式',
`delivery_address` varchar(1000) DEFAULT NULL COMMENT '送货地址',
`order_comment` varchar(200) DEFAULT NULL COMMENT '订单备注',
`out_trade_no` varchar(50) DEFAULT NULL COMMENT '订单交易编号(第三方支付用)',
`trade_body` varchar(200) DEFAULT NULL COMMENT '订单描述(第三方支付用)',
`create_time` datetime DEFAULT NULL COMMENT '创建时间',
`operate_time` datetime DEFAULT NULL COMMENT '操作时间',
`expire_time` datetime DEFAULT NULL COMMENT '失效时间',
`tracking_no` varchar(100) DEFAULT NULL COMMENT '物流单编号',
`parent_order_id` bigint(20) DEFAULT NULL COMMENT '父订单编号',
`img_url` varchar(200) DEFAULT NULL COMMENT '图片路径',
`province_id` int(20) DEFAULT NULL COMMENT '地区',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8 COMMENT='订单表';
~~~
* 订单详情表(order\_detail)
~~~sql
CREATE TABLE `order_detail` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '编号',
`order_id` bigint(20) DEFAULT NULL COMMENT '订单编号',
`sku_id` bigint(20) DEFAULT NULL COMMENT 'sku_id',
`sku_name` varchar(200) DEFAULT NULL COMMENT 'sku名称(冗余)',
`img_url` varchar(200) DEFAULT NULL COMMENT '图片名称(冗余)',
`order_price` decimal(10,2) DEFAULT NULL COMMENT '购买价格(下单时sku价格)',
`sku_num` varchar(200) DEFAULT NULL COMMENT '购买个数',
`create_time` datetime DEFAULT NULL COMMENT '创建时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8 COMMENT='订单详情表';
~~~
* 商品表(sku\_info)
~~~sql
CREATE TABLE `sku_info` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'skuid(itemID)',
`spu_id` bigint(20) DEFAULT NULL COMMENT 'spuid',
`price` decimal(10,0) DEFAULT NULL COMMENT '价格',
`sku_name` varchar(200) DEFAULT NULL COMMENT 'sku名称',
`sku_desc` varchar(2000) DEFAULT NULL COMMENT '商品规格描述',
`weight` decimal(10,2) DEFAULT NULL COMMENT '重量',
`tm_id` bigint(20) DEFAULT NULL COMMENT '品牌(冗余)',
`category3_id` bigint(20) DEFAULT NULL COMMENT '三级分类id(冗余)',
`sku_default_img` varchar(200) DEFAULT NULL COMMENT '默认显示图片(冗余)',
`create_time` datetime DEFAULT NULL COMMENT '创建时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8 COMMENT='商品表';
~~~
* 商品一级类目表(base\_category1)
~~~sql
CREATE TABLE `base_category1` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '编号',
`name` varchar(10) NOT NULL COMMENT '分类名称',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8 COMMENT='一级分类表';
~~~
* 商品二级类目表(base\_category2)
~~~sql
CREATE TABLE `base_category2` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '编号',
`name` varchar(200) NOT NULL COMMENT '二级分类名称',
`category1_id` bigint(20) DEFAULT NULL COMMENT '一级分类编号',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8 COMMENT='二级分类表';
~~~
* 商品三级类目表(base\_category3)
~~~sql
CREATE TABLE `base_category3` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '编号',
`name` varchar(200) NOT NULL COMMENT '三级分类名称',
`category2_id` bigint(20) DEFAULT NULL COMMENT '二级分类编号',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8 COMMENT='三级分类表';
~~~
* 省份表(base\_province)
~~~sql
CREATE TABLE `base_province` (
`id` int(20) DEFAULT NULL COMMENT 'id',
`name` varchar(20) DEFAULT NULL COMMENT '省名称',
`region_id` int(20) DEFAULT NULL COMMENT '大区id',
`area_code` varchar(20) DEFAULT NULL COMMENT '行政区位码'
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
~~~
* 区域表(base\_region)
~~~sql
CREATE TABLE `base_region` (
`id` int(20) NOT NULL COMMENT '大区id',
`region_name` varchar(20) DEFAULT NULL COMMENT '大区名称',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
~~~
> 注意:以上的建表语句是在MySQL中完成的,完整的建表及模拟数据生成脚本见:
>
> 链接:[https://pan.baidu.com/s/1fcMgDHGKedOpzqLbSRUGwA](https://links.jianshu.com/go?to=https%3A%2F%2Fpan.baidu.com%2Fs%2F1fcMgDHGKedOpzqLbSRUGwA) 提取码:zuqw
## 数据处理流程
### ODS层数据同步
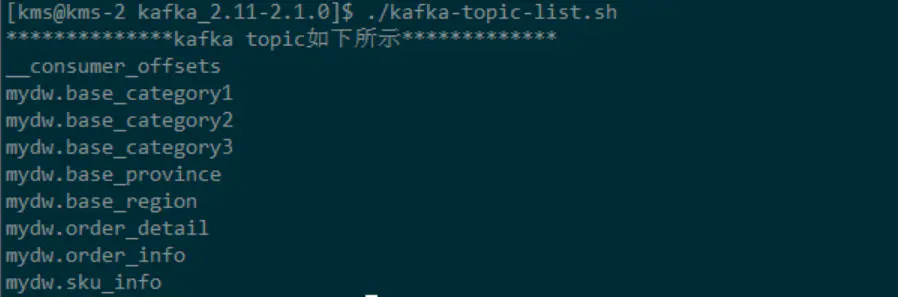
关于ODS层的数据同步参见我的另一篇文章[基于Canal与Flink实现数据实时增量同步(一)](https://links.jianshu.com/go?to=https%3A%2F%2Fmp.weixin.qq.com%2Fs%2FooPAScXAw2soqlgEoSbRAw)。主要使用canal解析MySQL的binlog日志,然后将其写入到Kafka对应的topic中。由于篇幅限制,不会对具体的细节进行说明。同步之后的结果如下图所示:
image
### DIM层维表数据准备
本案例中将维表存储在了MySQL中,实际生产中会用HBase存储维表数据。我们主要用到两张维表:**区域维表**和**商品维表**。处理过程如下:
* 区域维表
首先将`mydw.base_province`和`mydw.base_region`这个主题对应的数据抽取到MySQL中,主要使用Flink SQL的Kafka数据源对应的canal-json格式,注意:在执行装载之前,需要先在MySQL中创建对应的表,本文使用的MySQL数据库的名字为**dim**,用于存放维表数据。如下:
~~~sql
-- -------------------------
-- 省份
-- kafka Source
-- -------------------------
DROP TABLE IF EXISTS `ods_base_province`;
CREATE TABLE `ods_base_province` (
`id` INT,
`name` STRING,
`region_id` INT ,
`area_code`STRING
) WITH(
'connector' = 'kafka',
'topic' = 'mydw.base_province',
'properties.bootstrap.servers' = 'kms-3:9092',
'properties.group.id' = 'testGroup',
'format' = 'canal-json' ,
'scan.startup.mode' = 'earliest-offset'
) ;
-- -------------------------
-- 省份
-- MySQL Sink
-- -------------------------
DROP TABLE IF EXISTS `base_province`;
CREATE TABLE `base_province` (
`id` INT,
`name` STRING,
`region_id` INT ,
`area_code`STRING,
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://kms-1:3306/dim',
'table-name' = 'base_province', -- MySQL中的待插入数据的表
'driver' = 'com.mysql.jdbc.Driver',
'username' = 'root',
'password' = '123qwe',
'sink.buffer-flush.interval' = '1s'
);
-- -------------------------
-- 省份
-- MySQL Sink Load Data
-- -------------------------
INSERT INTO base_province
SELECT *
FROM ods_base_province;
-- -------------------------
-- 区域
-- kafka Source
-- -------------------------
DROP TABLE IF EXISTS `ods_base_region`;
CREATE TABLE `ods_base_region` (
`id` INT,
`region_name` STRING
) WITH(
'connector' = 'kafka',
'topic' = 'mydw.base_region',
'properties.bootstrap.servers' = 'kms-3:9092',
'properties.group.id' = 'testGroup',
'format' = 'canal-json' ,
'scan.startup.mode' = 'earliest-offset'
) ;
-- -------------------------
-- 区域
-- MySQL Sink
-- -------------------------
DROP TABLE IF EXISTS `base_region`;
CREATE TABLE `base_region` (
`id` INT,
`region_name` STRING,
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://kms-1:3306/dim',
'table-name' = 'base_region', -- MySQL中的待插入数据的表
'driver' = 'com.mysql.jdbc.Driver',
'username' = 'root',
'password' = '123qwe',
'sink.buffer-flush.interval' = '1s'
);
-- -------------------------
-- 区域
-- MySQL Sink Load Data
-- -------------------------
INSERT INTO base_region
SELECT *
FROM ods_base_region;
~~~
经过上面的步骤,将创建维表所需要的原始数据已经存储到了MySQL中,接下来就需要在MySQL中创建维表,我们使用上面的两张表,创建一张视图:`dim_province`作为维表:
~~~sql
-- ---------------------------------
-- DIM层,区域维表,
-- 在MySQL中创建视图
-- ---------------------------------
DROP VIEW IF EXISTS dim_province;
CREATE VIEW dim_province AS
SELECT
bp.id AS province_id,
bp.name AS province_name,
br.id AS region_id,
br.region_name AS region_name,
bp.area_code AS area_code
FROM base_region br
JOIN base_province bp ON br.id= bp.region_id
;
~~~
这样我们所需要的维表:dim\_province就创建好了,只需要在维表join时,使用Flink SQL创建JDBC的数据源,就可以使用该维表了。同理,我们使用相同的方法创建商品维表,具体如下:
~~~sql
-- -------------------------
-- 一级类目表
-- kafka Source
-- -------------------------
DROP TABLE IF EXISTS `ods_base_category1`;
CREATE TABLE `ods_base_category1` (
`id` BIGINT,
`name` STRING
)WITH(
'connector' = 'kafka',
'topic' = 'mydw.base_category1',
'properties.bootstrap.servers' = 'kms-3:9092',
'properties.group.id' = 'testGroup',
'format' = 'canal-json' ,
'scan.startup.mode' = 'earliest-offset'
) ;
-- -------------------------
-- 一级类目表
-- MySQL Sink
-- -------------------------
DROP TABLE IF EXISTS `base_category1`;
CREATE TABLE `base_category1` (
`id` BIGINT,
`name` STRING,
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://kms-1:3306/dim',
'table-name' = 'base_category1', -- MySQL中的待插入数据的表
'driver' = 'com.mysql.jdbc.Driver',
'username' = 'root',
'password' = '123qwe',
'sink.buffer-flush.interval' = '1s'
);
-- -------------------------
-- 一级类目表
-- MySQL Sink Load Data
-- -------------------------
INSERT INTO base_category1
SELECT *
FROM ods_base_category1;
-- -------------------------
-- 二级类目表
-- kafka Source
-- -------------------------
DROP TABLE IF EXISTS `ods_base_category2`;
CREATE TABLE `ods_base_category2` (
`id` BIGINT,
`name` STRING,
`category1_id` BIGINT
)WITH(
'connector' = 'kafka',
'topic' = 'mydw.base_category2',
'properties.bootstrap.servers' = 'kms-3:9092',
'properties.group.id' = 'testGroup',
'format' = 'canal-json' ,
'scan.startup.mode' = 'earliest-offset'
) ;
-- -------------------------
-- 二级类目表
-- MySQL Sink
-- -------------------------
DROP TABLE IF EXISTS `base_category2`;
CREATE TABLE `base_category2` (
`id` BIGINT,
`name` STRING,
`category1_id` BIGINT,
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://kms-1:3306/dim',
'table-name' = 'base_category2', -- MySQL中的待插入数据的表
'driver' = 'com.mysql.jdbc.Driver',
'username' = 'root',
'password' = '123qwe',
'sink.buffer-flush.interval' = '1s'
);
-- -------------------------
-- 二级类目表
-- MySQL Sink Load Data
-- -------------------------
INSERT INTO base_category2
SELECT *
FROM ods_base_category2;
-- -------------------------
-- 三级类目表
-- kafka Source
-- -------------------------
DROP TABLE IF EXISTS `ods_base_category3`;
CREATE TABLE `ods_base_category3` (
`id` BIGINT,
`name` STRING,
`category2_id` BIGINT
)WITH(
'connector' = 'kafka',
'topic' = 'mydw.base_category3',
'properties.bootstrap.servers' = 'kms-3:9092',
'properties.group.id' = 'testGroup',
'format' = 'canal-json' ,
'scan.startup.mode' = 'earliest-offset'
) ;
-- -------------------------
-- 三级类目表
-- MySQL Sink
-- -------------------------
DROP TABLE IF EXISTS `base_category3`;
CREATE TABLE `base_category3` (
`id` BIGINT,
`name` STRING,
`category2_id` BIGINT,
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://kms-1:3306/dim',
'table-name' = 'base_category3', -- MySQL中的待插入数据的表
'driver' = 'com.mysql.jdbc.Driver',
'username' = 'root',
'password' = '123qwe',
'sink.buffer-flush.interval' = '1s'
);
-- -------------------------
-- 三级类目表
-- MySQL Sink Load Data
-- -------------------------
INSERT INTO base_category3
SELECT *
FROM ods_base_category3;
-- -------------------------
-- 商品表
-- Kafka Source
-- -------------------------
DROP TABLE IF EXISTS `ods_sku_info`;
CREATE TABLE `ods_sku_info` (
`id` BIGINT,
`spu_id` BIGINT,
`price` DECIMAL(10,0),
`sku_name` STRING,
`sku_desc` STRING,
`weight` DECIMAL(10,2),
`tm_id` BIGINT,
`category3_id` BIGINT,
`sku_default_img` STRING,
`create_time` TIMESTAMP(0)
) WITH(
'connector' = 'kafka',
'topic' = 'mydw.sku_info',
'properties.bootstrap.servers' = 'kms-3:9092',
'properties.group.id' = 'testGroup',
'format' = 'canal-json' ,
'scan.startup.mode' = 'earliest-offset'
) ;
-- -------------------------
-- 商品表
-- MySQL Sink
-- -------------------------
DROP TABLE IF EXISTS `sku_info`;
CREATE TABLE `sku_info` (
`id` BIGINT,
`spu_id` BIGINT,
`price` DECIMAL(10,0),
`sku_name` STRING,
`sku_desc` STRING,
`weight` DECIMAL(10,2),
`tm_id` BIGINT,
`category3_id` BIGINT,
`sku_default_img` STRING,
`create_time` TIMESTAMP(0),
PRIMARY KEY (tm_id) NOT ENFORCED
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://kms-1:3306/dim',
'table-name' = 'sku_info', -- MySQL中的待插入数据的表
'driver' = 'com.mysql.jdbc.Driver',
'username' = 'root',
'password' = '123qwe',
'sink.buffer-flush.interval' = '1s'
);
-- -------------------------
-- 商品
-- MySQL Sink Load Data
-- -------------------------
INSERT INTO sku_info
SELECT *
FROM ods_sku_info;
~~~
经过上面的步骤,我们可以将创建商品维表的基础数据表同步到MySQL中,同样需要提前创建好对应的数据表。接下来我们使用上面的基础表在mySQL的dim库中创建一张视图:`dim_sku_info`,用作后续使用的维表。
~~~sql
-- ---------------------------------
-- DIM层,商品维表,
-- 在MySQL中创建视图
-- ---------------------------------
CREATE VIEW dim_sku_info AS
SELECT
si.id AS id,
si.sku_name AS sku_name,
si.category3_id AS c3_id,
si.weight AS weight,
si.tm_id AS tm_id,
si.price AS price,
si.spu_id AS spu_id,
c3.name AS c3_name,
c2.id AS c2_id,
c2.name AS c2_name,
c3.id AS c1_id,
c3.name AS c1_name
FROM
(
sku_info si
JOIN base_category3 c3 ON si.category3_id = c3.id
JOIN base_category2 c2 ON c3.category2_id =c2.id
JOIN base_category1 c1 ON c2.category1_id = c1.id
);
~~~
至此,我们所需要的维表数据已经准备好了,接下来开始处理DWD层的数据。
### DWD层数据处理
经过上面的步骤,我们已经将所用的维表已经准备好了。接下来我们将对ODS的原始数据进行处理,加工成DWD层的明细宽表。具体过程如下:
~~~sql
-- -------------------------
-- 订单详情
-- Kafka Source
-- -------------------------
DROP TABLE IF EXISTS `ods_order_detail`;
CREATE TABLE `ods_order_detail`(
`id` BIGINT,
`order_id` BIGINT,
`sku_id` BIGINT,
`sku_name` STRING,
`img_url` STRING,
`order_price` DECIMAL(10,2),
`sku_num` INT,
`create_time` TIMESTAMP(0)
) WITH(
'connector' = 'kafka',
'topic' = 'mydw.order_detail',
'properties.bootstrap.servers' = 'kms-3:9092',
'properties.group.id' = 'testGroup',
'format' = 'canal-json' ,
'scan.startup.mode' = 'earliest-offset'
) ;
-- -------------------------
-- 订单信息
-- Kafka Source
-- -------------------------
DROP TABLE IF EXISTS `ods_order_info`;
CREATE TABLE `ods_order_info` (
`id` BIGINT,
`consignee` STRING,
`consignee_tel` STRING,
`total_amount` DECIMAL(10,2),
`order_status` STRING,
`user_id` BIGINT,
`payment_way` STRING,
`delivery_address` STRING,
`order_comment` STRING,
`out_trade_no` STRING,
`trade_body` STRING,
`create_time` TIMESTAMP(0) ,
`operate_time` TIMESTAMP(0) ,
`expire_time` TIMESTAMP(0) ,
`tracking_no` STRING,
`parent_order_id` BIGINT,
`img_url` STRING,
`province_id` INT
) WITH(
'connector' = 'kafka',
'topic' = 'mydw.order_info',
'properties.bootstrap.servers' = 'kms-3:9092',
'properties.group.id' = 'testGroup',
'format' = 'canal-json' ,
'scan.startup.mode' = 'earliest-offset'
) ;
-- ---------------------------------
-- DWD层,支付订单明细表dwd_paid_order_detail
-- ---------------------------------
DROP TABLE IF EXISTS dwd_paid_order_detail;
CREATE TABLE dwd_paid_order_detail
(
detail_id BIGINT,
order_id BIGINT,
user_id BIGINT,
province_id INT,
sku_id BIGINT,
sku_name STRING,
sku_num INT,
order_price DECIMAL(10,0),
create_time TIMESTAMP(0),
pay_time TIMESTAMP(0)
) WITH (
'connector' = 'kafka',
'topic' = 'dwd_paid_order_detail',
'scan.startup.mode' = 'earliest-offset',
'properties.bootstrap.servers' = 'kms-3:9092',
'format' = 'changelog-json'
);
-- ---------------------------------
-- DWD层,已支付订单明细表
-- 向dwd_paid_order_detail装载数据
-- ---------------------------------
INSERT INTO dwd_paid_order_detail
SELECT
od.id,
oi.id order_id,
oi.user_id,
oi.province_id,
od.sku_id,
od.sku_name,
od.sku_num,
od.order_price,
oi.create_time,
oi.operate_time
FROM
(
SELECT *
FROM ods_order_info
WHERE order_status = '2' -- 已支付
) oi JOIN
(
SELECT *
FROM ods_order_detail
) od
ON oi.id = od.order_id;
~~~
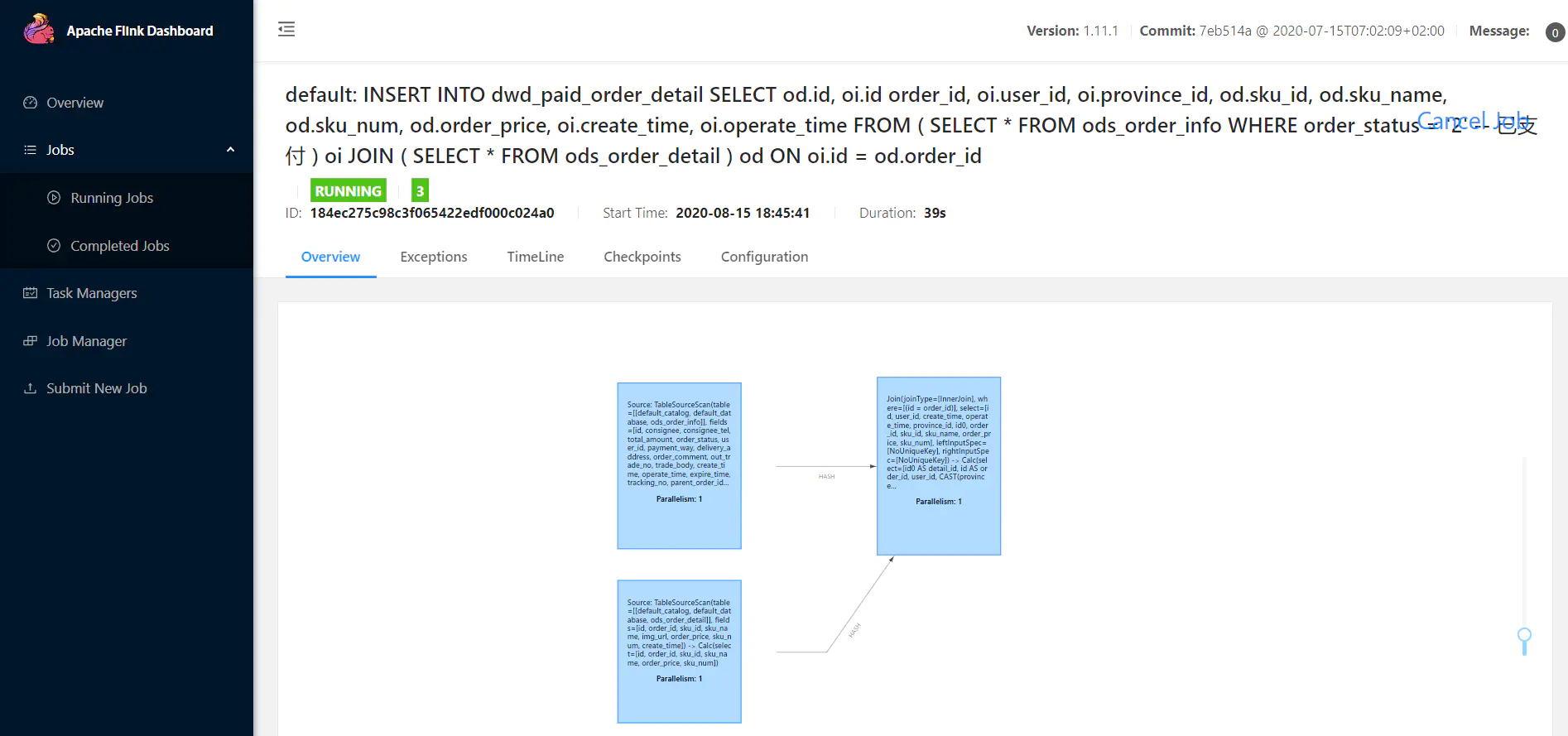
image
### ADS层数据
经过上面的步骤,我们创建了一张dwd\_paid\_order\_detail明细宽表,并将该表存储在了Kafka中。接下来我们将使用这张明细宽表与维表进行JOIN,得到我们ADS应用层数据。
* **ads\_province\_index**
首先在MySQL中创建对应的ADS目标表:**ads\_province\_index**
~~~sql
CREATE TABLE ads.ads_province_index(
province_id INT(10),
area_code VARCHAR(100),
province_name VARCHAR(100),
region_id INT(10),
region_name VARCHAR(100),
order_amount DECIMAL(10,2),
order_count BIGINT(10),
dt VARCHAR(100),
PRIMARY KEY (province_id, dt)
) ;
~~~
向MySQL的ADS层目标装载数据:
~~~sql
-- Flink SQL Cli操作
-- ---------------------------------
-- 使用 DDL创建MySQL中的ADS层表
-- 指标:1.每天每个省份的订单数
-- 2.每天每个省份的订单金额
-- ---------------------------------
CREATE TABLE ads_province_index(
province_id INT,
area_code STRING,
province_name STRING,
region_id INT,
region_name STRING,
order_amount DECIMAL(10,2),
order_count BIGINT,
dt STRING,
PRIMARY KEY (province_id, dt) NOT ENFORCED
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://kms-1:3306/ads',
'table-name' = 'ads_province_index',
'driver' = 'com.mysql.jdbc.Driver',
'username' = 'root',
'password' = '123qwe'
);
-- ---------------------------------
-- dwd_paid_order_detail已支付订单明细宽表
-- ---------------------------------
CREATE TABLE dwd_paid_order_detail
(
detail_id BIGINT,
order_id BIGINT,
user_id BIGINT,
province_id INT,
sku_id BIGINT,
sku_name STRING,
sku_num INT,
order_price DECIMAL(10,2),
create_time STRING,
pay_time STRING
) WITH (
'connector' = 'kafka',
'topic' = 'dwd_paid_order_detail',
'scan.startup.mode' = 'earliest-offset',
'properties.bootstrap.servers' = 'kms-3:9092',
'format' = 'changelog-json'
);
-- ---------------------------------
-- tmp_province_index
-- 订单汇总临时表
-- ---------------------------------
CREATE TABLE tmp_province_index(
province_id INT,
order_count BIGINT,-- 订单数
order_amount DECIMAL(10,2), -- 订单金额
pay_date DATE
)WITH (
'connector' = 'kafka',
'topic' = 'tmp_province_index',
'scan.startup.mode' = 'earliest-offset',
'properties.bootstrap.servers' = 'kms-3:9092',
'format' = 'changelog-json'
);
-- ---------------------------------
-- tmp_province_index
-- 订单汇总临时表数据装载
-- ---------------------------------
INSERT INTO tmp_province_index
SELECT
province_id,
count(distinct order_id) order_count,-- 订单数
sum(order_price * sku_num) order_amount, -- 订单金额
TO_DATE(pay_time,'yyyy-MM-dd') pay_date
FROM dwd_paid_order_detail
GROUP BY province_id,TO_DATE(pay_time,'yyyy-MM-dd')
;
-- ---------------------------------
-- tmp_province_index_source
-- 使用该临时汇总表,作为数据源
-- ---------------------------------
CREATE TABLE tmp_province_index_source(
province_id INT,
order_count BIGINT,-- 订单数
order_amount DECIMAL(10,2), -- 订单金额
pay_date DATE,
proctime as PROCTIME() -- 通过计算列产生一个处理时间列
) WITH (
'connector' = 'kafka',
'topic' = 'tmp_province_index',
'scan.startup.mode' = 'earliest-offset',
'properties.bootstrap.servers' = 'kms-3:9092',
'format' = 'changelog-json'
);
-- ---------------------------------
-- DIM层,区域维表,
-- 创建区域维表数据源
-- ---------------------------------
DROP TABLE IF EXISTS `dim_province`;
CREATE TABLE dim_province (
province_id INT,
province_name STRING,
area_code STRING,
region_id INT,
region_name STRING ,
PRIMARY KEY (province_id) NOT ENFORCED
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://kms-1:3306/dim',
'table-name' = 'dim_province',
'driver' = 'com.mysql.jdbc.Driver',
'username' = 'root',
'password' = '123qwe',
'scan.fetch-size' = '100'
);
-- ---------------------------------
-- 向ads_province_index装载数据
-- 维表JOIN
-- ---------------------------------
INSERT INTO ads_province_index
SELECT
pc.province_id,
dp.area_code,
dp.province_name,
dp.region_id,
dp.region_name,
pc.order_amount,
pc.order_count,
cast(pc.pay_date as VARCHAR)
FROM
tmp_province_index_source pc
JOIN dim_province FOR SYSTEM_TIME AS OF pc.proctime as dp
ON dp.province_id = pc.province_id;
~~~
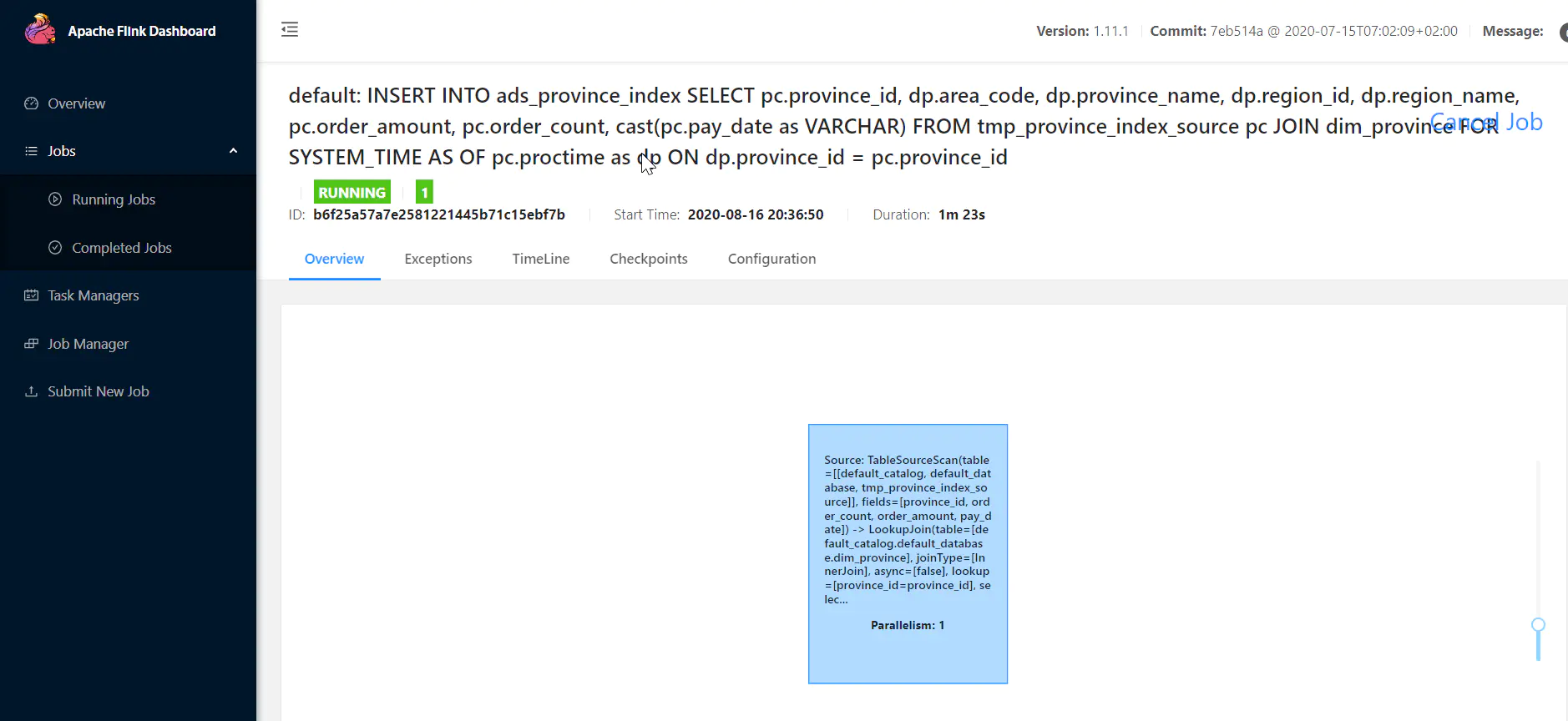
当提交任务之后:观察Flink WEB UI:
image
查看ADS层的ads\_province\_index表数据:
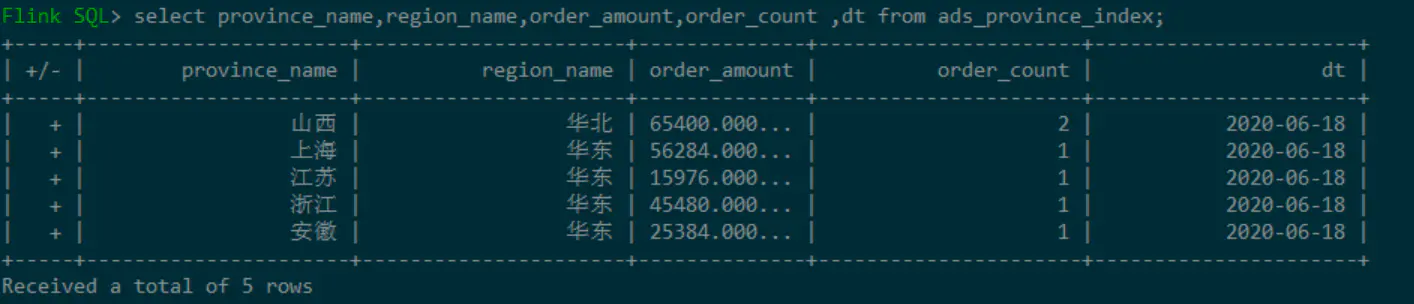
image
* **ads\_sku\_index**
首先在MySQL中创建对应的ADS目标表:**ads\_sku\_index**
~~~sql
CREATE TABLE ads_sku_index
(
sku_id BIGINT(10),
sku_name VARCHAR(100),
weight DOUBLE,
tm_id BIGINT(10),
price DOUBLE,
spu_id BIGINT(10),
c3_id BIGINT(10),
c3_name VARCHAR(100) ,
c2_id BIGINT(10),
c2_name VARCHAR(100),
c1_id BIGINT(10),
c1_name VARCHAR(100),
order_amount DOUBLE,
order_count BIGINT(10),
sku_count BIGINT(10),
dt varchar(100),
PRIMARY KEY (sku_id,dt)
);
~~~
向MySQL的ADS层目标装载数据:
~~~sql
-- ---------------------------------
-- 使用 DDL创建MySQL中的ADS层表
-- 指标:1.每天每个商品对应的订单个数
-- 2.每天每个商品对应的订单金额
-- 3.每天每个商品对应的数量
-- ---------------------------------
CREATE TABLE ads_sku_index
(
sku_id BIGINT,
sku_name VARCHAR,
weight DOUBLE,
tm_id BIGINT,
price DOUBLE,
spu_id BIGINT,
c3_id BIGINT,
c3_name VARCHAR ,
c2_id BIGINT,
c2_name VARCHAR,
c1_id BIGINT,
c1_name VARCHAR,
order_amount DOUBLE,
order_count BIGINT,
sku_count BIGINT,
dt varchar,
PRIMARY KEY (sku_id,dt) NOT ENFORCED
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://kms-1:3306/ads',
'table-name' = 'ads_sku_index',
'driver' = 'com.mysql.jdbc.Driver',
'username' = 'root',
'password' = '123qwe'
);
-- ---------------------------------
-- dwd_paid_order_detail已支付订单明细宽表
-- ---------------------------------
CREATE TABLE dwd_paid_order_detail
(
detail_id BIGINT,
order_id BIGINT,
user_id BIGINT,
province_id INT,
sku_id BIGINT,
sku_name STRING,
sku_num INT,
order_price DECIMAL(10,2),
create_time STRING,
pay_time STRING
) WITH (
'connector' = 'kafka',
'topic' = 'dwd_paid_order_detail',
'scan.startup.mode' = 'earliest-offset',
'properties.bootstrap.servers' = 'kms-3:9092',
'format' = 'changelog-json'
);
-- ---------------------------------
-- tmp_sku_index
-- 商品指标统计
-- ---------------------------------
CREATE TABLE tmp_sku_index(
sku_id BIGINT,
order_count BIGINT,-- 订单数
order_amount DECIMAL(10,2), -- 订单金额
order_sku_num BIGINT,
pay_date DATE
)WITH (
'connector' = 'kafka',
'topic' = 'tmp_sku_index',
'scan.startup.mode' = 'earliest-offset',
'properties.bootstrap.servers' = 'kms-3:9092',
'format' = 'changelog-json'
);
-- ---------------------------------
-- tmp_sku_index
-- 数据装载
-- ---------------------------------
INSERT INTO tmp_sku_index
SELECT
sku_id,
count(distinct order_id) order_count,-- 订单数
sum(order_price * sku_num) order_amount, -- 订单金额
sum(sku_num) order_sku_num,
TO_DATE(pay_time,'yyyy-MM-dd') pay_date
FROM dwd_paid_order_detail
GROUP BY sku_id,TO_DATE(pay_time,'yyyy-MM-dd')
;
-- ---------------------------------
-- tmp_sku_index_source
-- 使用该临时汇总表,作为数据源
-- ---------------------------------
CREATE TABLE tmp_sku_index_source(
sku_id BIGINT,
order_count BIGINT,-- 订单数
order_amount DECIMAL(10,2), -- 订单金额
order_sku_num BIGINT,
pay_date DATE,
proctime as PROCTIME() -- 通过计算列产生一个处理时间列
) WITH (
'connector' = 'kafka',
'topic' = 'tmp_sku_index',
'scan.startup.mode' = 'earliest-offset',
'properties.bootstrap.servers' = 'kms-3:9092',
'format' = 'changelog-json'
);
-- ---------------------------------
-- DIM层,商品维表,
-- 创建商品维表数据源
-- ---------------------------------
DROP TABLE IF EXISTS `dim_sku_info`;
CREATE TABLE dim_sku_info (
id BIGINT,
sku_name STRING,
c3_id BIGINT,
weight DECIMAL(10,2),
tm_id BIGINT,
price DECIMAL(10,2),
spu_id BIGINT,
c3_name STRING,
c2_id BIGINT,
c2_name STRING,
c1_id BIGINT,
c1_name STRING,
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://kms-1:3306/dim',
'table-name' = 'dim_sku_info',
'driver' = 'com.mysql.jdbc.Driver',
'username' = 'root',
'password' = '123qwe',
'scan.fetch-size' = '100'
);
-- ---------------------------------
-- 向ads_sku_index装载数据
-- 维表JOIN
-- ---------------------------------
INSERT INTO ads_sku_index
SELECT
sku_id ,
sku_name ,
weight ,
tm_id ,
price ,
spu_id ,
c3_id ,
c3_name,
c2_id ,
c2_name ,
c1_id ,
c1_name ,
sc.order_amount,
sc.order_count ,
sc.order_sku_num ,
cast(sc.pay_date as VARCHAR)
FROM
tmp_sku_index_source sc
JOIN dim_sku_info FOR SYSTEM_TIME AS OF sc.proctime as ds
ON ds.id = sc.sku_id
;
~~~
当提交任务之后:观察Flink WEB UI:
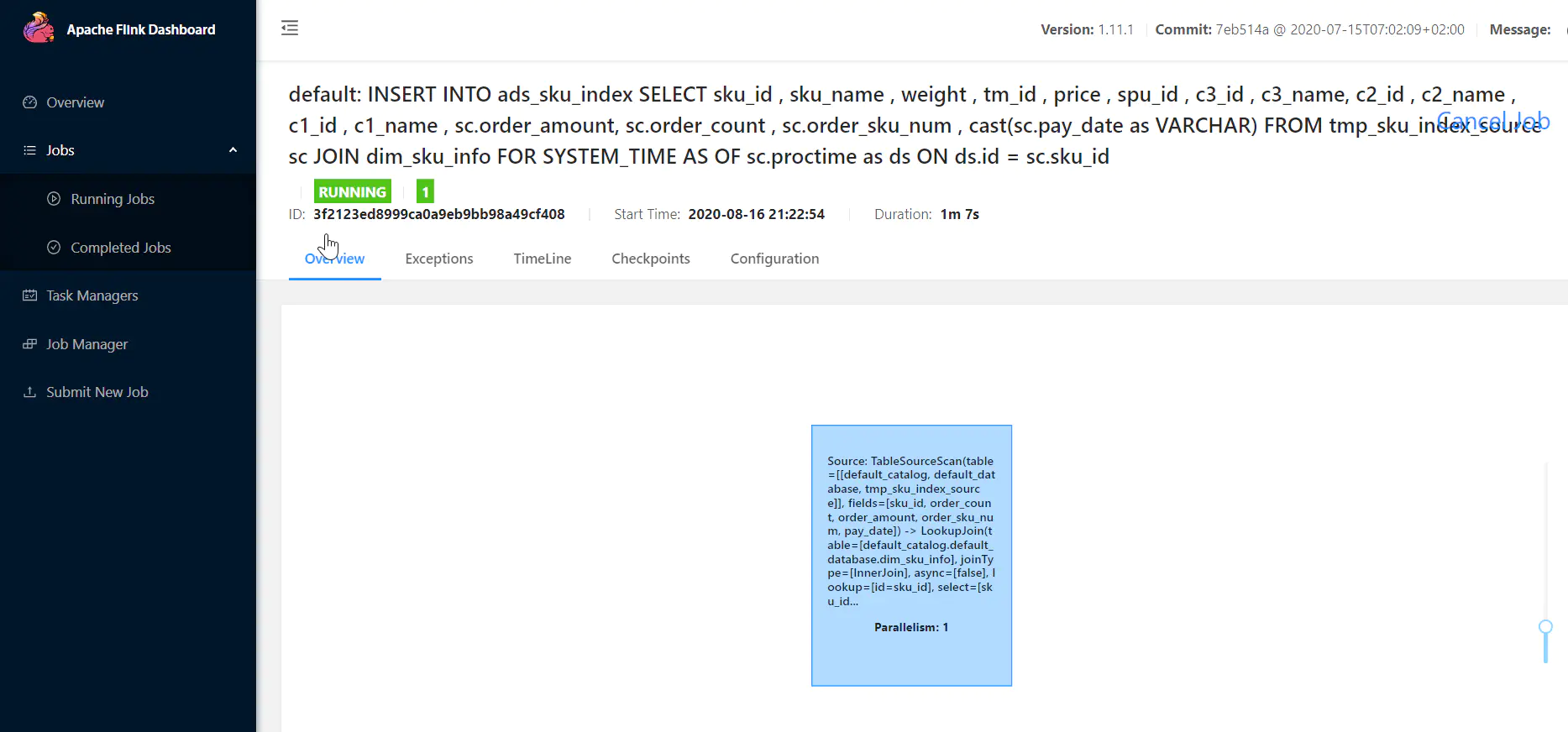
image
查看ADS层的ads\_sku\_index表数据:
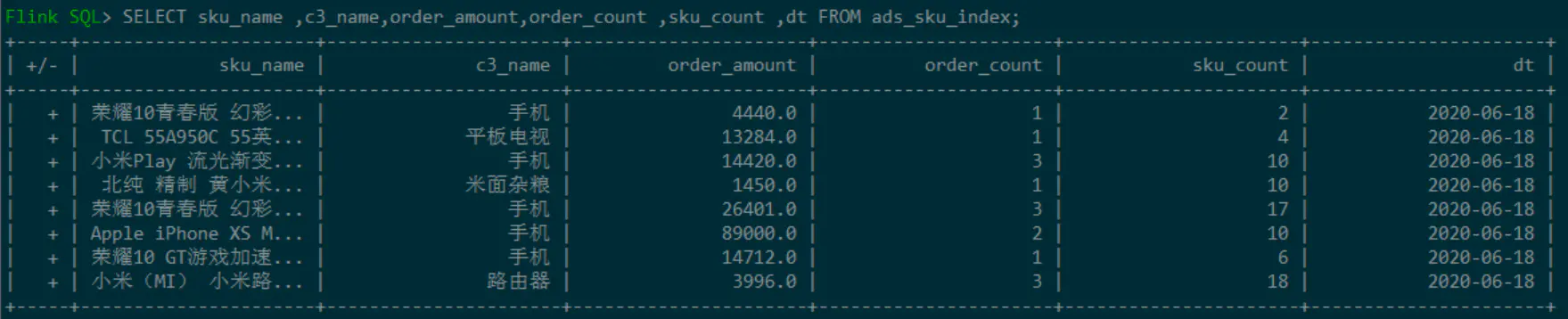
image
### FineBI结果展示
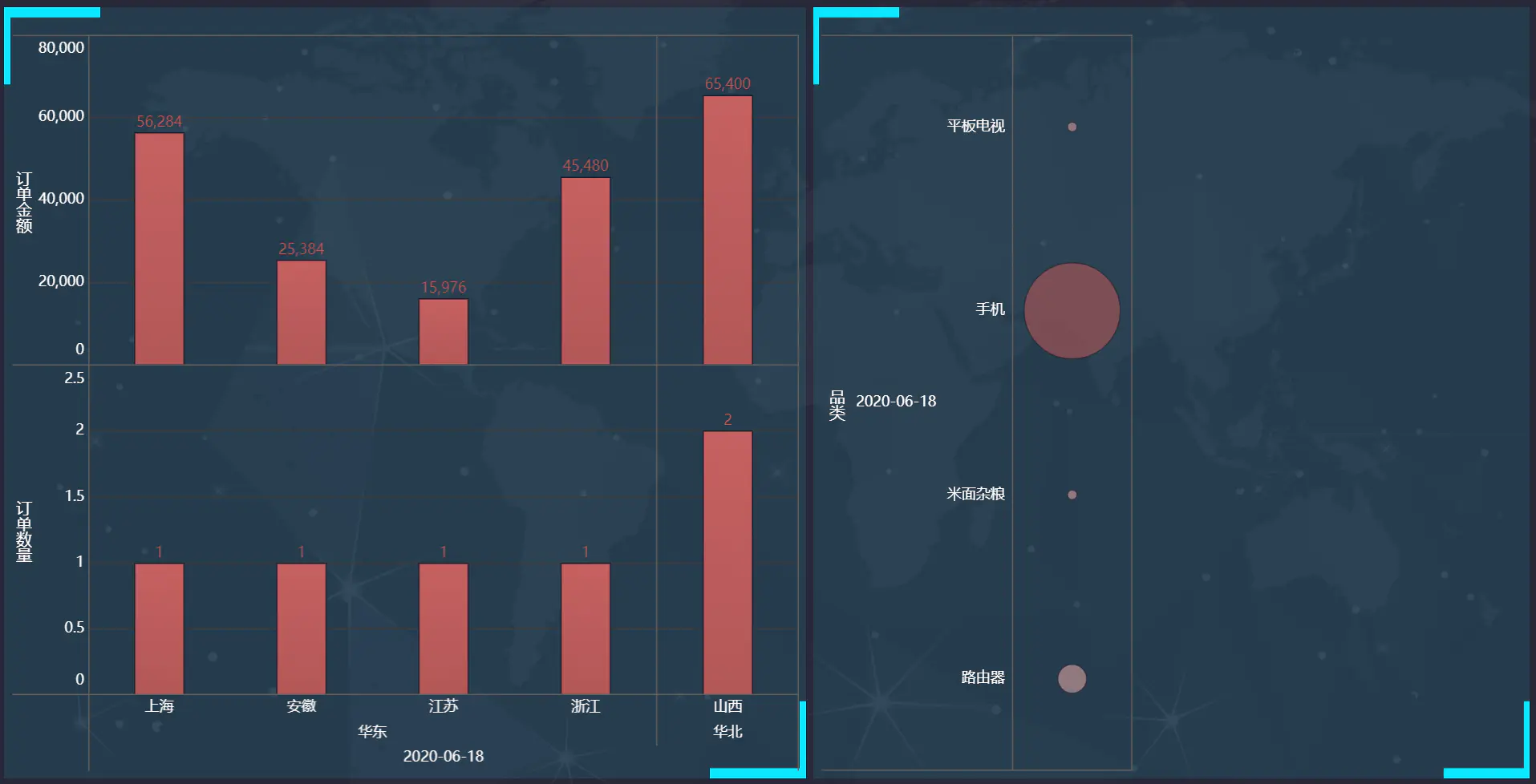
## 其他注意点
### Flink1.11.0存在的bug
当在代码中使用Flink1.11.0版本时,如果将一个change-log的数据源insert到一个upsert sink时,会报如下异常:
~~~bash
[ERROR] Could not execute SQL statement. Reason:
org.apache.flink.table.api.TableException: Provided trait [BEFORE_AND_AFTER] can't satisfy required trait [ONLY_UPDATE_AFTER]. This is a bug in planner, please file an issue.
Current node is TableSourceScan(table=[[default_catalog, default_database, t_pick_order]], fields=[order_no, status])
~~~
该bug目前已被修复,修复可以在Flink1.11.1中使用。
## 总结
本文主要分享了构建一个实时数仓的demo案例,通过本文可以了解实时数仓的数据处理流程,在此基础之上,对Flink SQL的CDC会有更加深刻的认识。另外,本文给出了非常详细的使用案例,你可以直接上手进行操作,在实践中探索实时数仓的构建流程。
- php开发
- 常用技巧
- 字符数组对象
- php换行替换,PHP替换回车换行符的三种方法
- PHP 数组转字符串,与字符串转数组
- php将img中的宽高删除,PHP删除HTML中宽高样式的详解
- php去除换行(回车换行)的三种方法
- php 过滤word 样式
- php如何设置随机数
- 2个比较经典的PHP加密解密函数分享
- php怎么去除小数点后多余的0
- php中判断是一维数组还是二维数组的解决方案
- php 获取数组中出现次数最多的值(重复最多的值)与出现的次数
- PHP过滤掉换行符、特殊空格、制表符等
- PHP中json_endoce转义反斜杠的问题
- PHP过滤Emoji表情和特殊符号的方法
- PHP完美的提取链接正则
- php很牛的图片采集
- 日期处理
- php 获取今日、昨日、上周、本月的起始时间戳和结束时间戳的方法非常简单
- PHP指定时间戳/日期加一天,一年,一周,一月
- 使用php 获取时间今天明天昨天时间戳的详解
- php获得当月的节假日函数(包含周末,年度节假日)
- PHP获取本月起始和截止时间戳
- php 获取每月开始结束时间,php 获取指定月份的开始结束时间戳
- PHP获取今天,昨天,本月,上个月,本年 起始时间戳
- php、mysql查询当天,本周,本月的用法
- php获取两个时间戳之间相隔多少天多少小时多少分多少秒
- 毫秒级时间戳和日期格式转换
- php-倒计时
- 请求提交上传
- php+put+post,Curl和PHP-如何通过PUT,POST,GET通过curl传递json
- PHP put提交和获取数据
- PHP curl put方式上传文件
- 数据导入导出
- PHP快速导入大量数据到数据库的方法
- PHP快速导出百万级数据到CSV或者EXCEL文件
- PHP解析大型Excel表格的库:box/spout
- PHP导入(百万级)Excel表格数据
- PHP如何切割excel大文件
- 使用 PHP_XLSXWriter 代替 PHPExcel 10W+ 数据秒级导出
- 安装php扩展XLSXWriter
- 解决php导入excel表格时获取日期变成浮点数的方法
- xml处理
- PHP XML和数组互相转换
- php解析xml字符串
- php 生成vcf通讯录
- 文件操作相关
- php获取文件后缀的9种方法
- PHP判断远程文件是否存在
- PHP获取文件修改时间,访问时间,inode修改时间
- php获取远程文件大小教程
- php 读取文件并以文件方式下载
- php 把数字转化为大写中文
- 请求响应
- PHP 获取当前访问的URL
- 压缩
- php生成zip压缩包
- PHPMailer
- 整理PHPMailer 发送邮件 邮件内容为html 可以添加多个附件等
- 通达oa
- OA管理员密码忘了怎么办,这里教你分分钟搞定…
- 跨域
- php解决多站点跨域
- php设置samesite cookie,有效防止CSRF
- Chrome 配置samesite=none方式
- Cookie 的 SameSite 属性
- 图片
- php pdf首页截图,PHP_PHP中使用Imagick读取pdf并生成png缩略图实例,pdf生成png首页缩略图
- PHP -- 七牛云 在线视频 获取某一帧作为封面图
- PHP图片压缩方法
- 如何解决PHP curl或file_get_contents下载图片损坏或无法打开的问题
- php远程下载文章中图片并保存源文件名不变
- 详解PHP如何下载采集图片到本地(附代码实例)
- php如何将webp格式图片转为jpeg
- PHP获取远程图片的宽高和体积大小
- php 软件版本号比较
- 使用PHP通过SMTP发送电邮
- 常用正则表达式
- php如何用正则表达式匹配中文
- 用于分割字符串的 PHP preg_match_all 正则表达式
- 性能优化
- php.ini配置调优
- PHP 几种常见超时的设置方法
- PHP函数in_array、array_key_exists和isset效率分析
- php array push 和array_merge 效率谁高,php 通过array_merge()和array+array合并数组的区别和效率比较...
- php 两个数组取交集、并集、差集
- 设置PHP最大连接数及php-fpm 高并发 参数调整
- 小工具
- php 获取代码执行时间和消耗的内存
- PHP如何判断某项扩展是否开启
- centos7.x下php 导出扩展 XLSXWriter 安装
- php生成mysql数据库字典
- PHP 实现 word/excel/ppt 转换为 PDF
- composer的使用
- showdoc sqlite3 找回管理员密码
- php怎么将数组转为xml
- PHP抖音最新视频提取代码
- yii
- Yii2 如何获取Header参数?
- swoole
- Linux下搭建swoole服务的基本步骤
- 相关学习资料
- 带你学习swoole_process详解
- 按照官方文档 在win10下安装 docker for windows easyswoole镜像 挂载目录
- php常用框架
- Hyperf
- 常用算法PHP版
- thinkphp6
- TP6 事件绑定、监听、订阅
- Thinkphp 模板中输出HTML的变量
- Thinkphp6(操作SQL数据库)
- thinkphp6 mysql查询语句对于为null和为空字符串给出特定值处理
- Thinkphp 6 - 连接配置多个数据库并实现自由切换(详细过程及实例demo)
- TP框架中的Db::name 和 dB::table 以及 db('') 的区别
- thinkphp6.0模型篇之模型的软删除
- thinkphp6自定义日志驱动,增加显示全部请求信息
- 其他系统
- 微擎数据库字段字典
- Flutter实现微信支付和iOS IAP支付
- Flutter上线项目实战——苹果内购
- PHP接入苹果支付
- 调试
- php如何获取当前脚本所有加载的文件
- php跟踪所有调用方法,日志方法
- 解析phpstorm + xdebug 远程断点调试
- PHP XDEBUG调试 PHPSTORM配置
- 异常处理
- PHP 出现 502 解决方案
- php 语法解析错误 syntax error unexpected namespace T_NAMESPACE
- Composer 安装与使用
- 数据库相关
- php pdo怎么设置utf8
- php 如何根据最新聊天对用户进行排序
- php lic&fpm
- 让php程序在linux后台执行
- PHPcli模式和fpm模式优缺点在哪里?
- 运行模式
- php运行模式之cli模式
- 自己库
- php批量获取所有公众号粉丝openid
- 地图
- php 判断点在多边形内,php百度地图api判断地址是否在多边形区域内
- PHP,Mysql-根据一个给定经纬度的点,进行附近地点查询
- MySQL 根据经纬度查找排序
- PHP+MySQL获取坐标范围内的数据
- 【百度地图】删除指定覆盖物
- 百度地图多点+画连接线+数字标注
- laravel5.8
- laravel5.8(四)引入自定义常量文件及公共函数文件
- Lumen 查询执行SQL
- 使你的 Laravel 项目模块化
- Laravel 多条件 AND , OR条件组合查询
- Laravel 查询 多个or或者and条件
- laravel redis操作大全
- laravel中外部定义whereIn的用法和where中使用in
- lumen5.8
- 创建laravel5.8 lumen前后台api项目--记录请求和响应日志
- Laravel和Lumen开启SQL日志记录
- Laravel 5.8 常用操作(路径+日志+分页+其他操作)
- 升级php7.4 laravel lumen报错Trying to access array offset on value of type null
- Laravel 任务调度(计划任务,定时任务)
- laravel的command定时任务时间的设置
- Laravel任务调度的简单使用
- laravel单数据库执行事务和多数据库执行事务
- laravel中锁以及事务的简单使用
- 申请其他相关
- 小程序地理位置接口申请
- PHP高并发
- php 高并发下 秒杀处理思路
- 记录 PHP高并发 商品秒杀 问题的 Redis解决方案
- thinkphp3.2
- thinkphp3.2 数据库 AND OR连缀使用
- laravel
- laravel的联表查询with方法的使用
- laravel获取请求路由对应的控制器和方法
- Laravel 模型关联建立与查询
- Laravel多表(3张表以上)with[]关联查询,对关联的模型做条件查询(has,跟join一样结果 )
- Laravel模型属性的隐藏属性、显示属性和临时暴露隐藏属性用法介绍
- aravel获取当前的url以及当前的基础域名方法汇总
- Laravel 模型实现多库查询或者多表映射
- 关于 Laravel 的 with 多表查询问题
- Laravel 模型过滤(Filter)设计
- 懒加载、预加载、with()、load() 傻傻分不清楚?
- laravel模型$castsl属性
- Laravel Query Builder 复杂查询案例:子查询实现分区查询 partition by
- Laravel 模型关联、关联查询、预加载使用实例
- laravel 中with关联查询限定查询字段
- laravel 原生字段查询 whereRaw 和 where(DB::raw(''))
- lavarel - where条件分组查询(orWhere)
- 通过 Laravel 查询构建器实现复杂的查询语句
- 两个结果集合并成一个
- Laravel 对某一列进行筛选然后求和 sum()
- laravel怎么优雅的拼接where,处理whereIn与where数组查询的问题
- laravel查询时判断是否存在数据
- laravel中的whereNull和whereNotNull
- laravel框架中的子查询
- Laravel框架中 orwhere 多条件查询的使用
- Laravel中where的高级使用方法
- laravel复杂的数据库查询(事例)
- laravel多条件查询方法(and,or嵌套查询)
- Laravel 的 where or 查询
- Laravel 进行where 多个or和and的条件查询可用
- 数据库
- mysql
- mysql联合索引(复合索引)详解
- MYSQL 清空表和截断表
- MySQL快速生成大量测试数据(100万、1000万、1亿)
- 提高mysql千万级大数据SQL查询优化30条经验(Mysql索引优化注意)
- MySQL常用命令
- MySQL(三)|《千万级大数据查询优化》第一篇:创建高性能的索引
- MySQL(一)|性能分析方法、SQL性能优化和MySQL内部配置优化
- MySQL(二)|深入理解MySQL的四种隔离级别及加锁实现原理
- MySQL(四)|《千万级大数据查询优化》第一篇:创建高性能的索引(补充)
- MySQL(五)|《千万级大数据查询优化》第二篇:查询性能优化(1)
- MySQL(六)|《千万级大数据查询优化》第二篇:查询性能优化(2)
- MySQL(七)|MySQL分库分表的那点事
- Mysql索引优化 Mysql通过索引提升查询效率(第二棒)
- MySQL查询的性能优化(查询缓存、排序跟索引)
- 【总结】MySQL数据库
- MySQL存储引擎、事务日志并发访问以及隔离级别
- 技巧
- 数据库 SQL查询重复记录 方法
- 替换数据库中某个字段中的部分字符
- mysql开启bin log 并查看bin log日志(linux)
- 分表分区
- 千万级别数据的mysql数据表优化
- MYSQL百万级数据,如何优化
- MySQL备份和恢复
- MySQL间隙锁死锁问题
- 小技巧
- 基础
- MySQL中sql_mode参数
- mysql数据库异常
- this is incompatible with sql_mode=only_full_group_by
- mysql安全
- MySQL数据库被比特币勒索及安全调整
- MongoDB
- sql查询
- MYSQL按时间段分组查询当天,每小时,15分钟数据分组
- 高级
- 基于 MySQL + Tablestore 分层存储架构的大规模订单系统实践-架构篇
- 数据库安全
- 服务器被黑,MySQL 数据库遭比特币勒索!该如何恢复?
- 数千台MySQL数据库遭黑客比特币勒索,该怎么破?
- MySQL 数据库规范
- MySQL数据库开发的36条铁律
- Elasticsearch
- 安装与配置
- ElasticSearch关闭重启命令
- 设置ES默认分词器IK analyzer
- 查询
- elasticsearch 模糊查询不分词,实现 mysql like
- elasticSearch多条件高级检索语句,包含多个must、must_not、should嵌套示例,并考虑nested对象的特殊检索
- elasticSearch按字段普通检索,结果高亮
- Elasticsearch 如何实现查询/聚合不区分大小写?
- 索引更新&刷新
- refresh与批量操作的效率
- Elasticsearch 删除type
- 分词器
- ElasticSearch最全分词器比较及使用方法
- 异常错误
- 解决ES因内存不足而无法查询的错误,Data too large, data for [<http_request>]
- linux
- 基本知识
- CentOS7.5 通过wget下载文件到指定目录
- 【CentOS】vi命令
- centos7查看硬盘使用情况
- CentOS7 查看目录大小
- Centos 7下查看当前目录大小及文件个数
- 普通用户sudo\su 到root免密码
- 普通用户切换到root用户下的免密配置方法
- linux 获取进程启动参数,linux查看进程启动及运行时间
- Linux 查看进程
- linux删除文件后不释放磁盘的问题
- Linux查找大文件命令
- linux 如何关闭正在执行的php脚本
- linux三剑客(grep、sed、awk)基本使用
- centos 卸载软件
- centos查看内存、cpu占用、占用前10,前X
- Centos 查看系统状态
- 异常
- 问题解决:Failed to download metadata for repo ‘appstream‘: Cannot prepare internal mirrorlist:...
- php相关
- centos 安装phpize
- Centos7.2下phpize安装php扩展
- 切换版本
- 运营工具
- 资深Linux运维工程师常用的10款软件/工具介绍
- 一款良心的终端连接工具
- 六款Linux常用远程连接工具介绍,看看哪一款最适合你
- Finalshell
- Linux Finalshell连接centos7和文件无显示问题
- WSL2:我在原生的Win10玩转Linux系统
- MobaXterm
- 运维
- linux服务器上定时自动备份数据库,并保留最新5天的数据
- Centos系统开启及关闭端口
- CentOS7开放和关闭端口命令
- Linux中查看所有正在运行的进程
- 防火墙firewall-cmd命令详解
- centos 7.8阿里云服务器挂载 数据盘
- Linux Finalshell连接centos7和文件无显示问题
- Centos7系统端口被占用问题的解决方法
- vi
- 如何在Vim/Vi中复制,剪切和粘贴
- 命令
- [Linux kill进程] kill 进程pid的使用详解
- 备份还原
- Linux的几种备份、恢复系统方式
- Linux系统全盘备份方法
- 相关软件安装
- linux下 lua安装
- python
- 升级pip之后出现sys.stderr.write(f“ERROR: {exc}“)
- lua
- centos源码部署lua-5.3
- deepin
- deepin20.6设置默认的root密码
- 任务相关
- 宝塔定时任务按秒执行
- CentOS 7 定时任务 crontab 入门
- centos7定时任务crontab
- Linux下定时任务的查看及取消
- Linux(CentOS7)定时执行任务Crond详细说明
- Linux 查看所有定时任务
- linux查看所有用户定时任务
- Linux 定时任务(超详细)
- 防火墙
- Centos7开启防火墙及特定端口
- CentOS防火墙操作:开启端口、开启、关闭、配置
- 生成 SSH 密钥(windows+liunx)
- 阿里云,挂载云盘
- 前端
- layui
- layui多文件上传
- layer.msg()弹框,弹框后继续运行
- radio取值
- layui-数据表格排序
- Layui select选择框添加搜索选项功能
- 保持原来样式
- layui表格单元如何自动换行
- layui-laydate时间日历控件使用方法详解
- layui定时刷新数据表格
- layer 延时设置
- layer.open 回调函数
- 【Layui内置方法】layer.msg延时关闭msg对话框(代码案例)
- layui多图上传图片顺序错乱及重复上传解决
- layer.confirm关闭弹窗
- vue
- Vue跨域解决方法
- vue 4.xx.xx版本降级至2.9.6
- vue-cli 2.x升级到3.x版本, 和3.x降级到2.x版本命令
- 最新版Vue或者指定版本
- Vue2.6.11按需模块安装配置
- jQuery
- jQuery在页面加载时动态修改图片尺寸的方法
- jquery操作select(取值,设置选中)
- 日历
- FullCalendar中文文档:Event日程事件
- js
- JS 之 重定向
- javascript截取video视频第一帧作为封面方案
- HTML <video> preload 属性
- jQuery使用ajax提交post数据
- JS截取视频靓丽的帧作为封面
- H5案例分享:移动端touch事件判断滑屏手势的方向
- JS快速获取图片宽高的方法
- win
- Windows环境下curl的使用
- Cygwin
- Windows下安装Cygwin及apt-cyg
- Cygwin 安装、CMake 安装
- mklink命令 详细使用
- Nginx
- Nginx高级篇-性能优化
- Nginx常用命令(Linux)
- linux+docker+nginx如何配置环境并配置域名访问
- Nginx的启动(start),停止(stop)命令
- linux 查看nginx 安装路径
- 安装配置
- Linux 查看 nginx 安装目录和配置文件路径
- 【NGINX入门】3.Nginx的缓存服务器proxy_cache配置
- thinkphp6.0 伪静态失效404(win下)
- 深入
- nginx rewrite及多upstream
- Nginx负载均衡(upstream)
- 专业术语
- 耦合?依赖?耦合和依赖的关系?耦合就是依赖
- PHP常用六大设计模式
- 高可用
- 分布式与集群
- Nginx 实践案例:反向代理单台web;反向代理多组web并实现负载均衡
- 容器
- Docker
- 30 分钟快速入门 Docker 教程
- linux查看正在运行的容器,说说Docker 容器常用命令
- Windows 安装Docker至D盘
- 配置
- win10 快速搭建 lnmp+swoole 环境 ,部署laravel6 与 swoole框架laravel-s项目1
- win10 快速搭建 lnmp+swoole 环境 ,部署laravel6 与 swoole框架laravel-s项目2
- docker 容器重命名
- Linux docker常用命令
- 使用
- docker 搭建php 开发环境 添加扩展redis、swoole、xdebug
- docker 单机部署redis集群
- Docker 退出容器不停止容器运行 并重新进入正在运行的容器
- 进入退出docker容器
- Docker的容器设置随Docker的启动而启动
- 使用异常处理
- docker容器中bash: vi: command not found
- OCI runtime exec failed: exec failed:解决方法
- docker启动容器慢,很慢,特别慢的坑
- 解决windows docker开发thinkphp6启动慢的问题
- 【Windows Docker】docker挂载解决IO速度慢的问题
- Docker的网络配置,导致Docker使用网路很慢的问题及解决办法
- golang工程部署到docker容器
- Docker 容器设置自启动
- 如何优雅地删除Docker镜像和容器(超详细)
- 5 个好用的 Docker 图形化管理工具
- Docker 可能会用到的命令
- Kubernetes
- 消息队列
- RabbitMQ
- php7.3安装使用rabbitMq
- Windows环境PHP如何使用RabbitMQ
- RabbitMQ学习笔记:4369、5672、15672、25672默认端口号修改
- Window10 系统 RabbitMQ的安装和简单使用
- RabbitMQ默认端口
- RabbitMQ可视化界面登录不了解决方案
- RocketMQ
- Kafka
- ActiveMQ
- mqtt
- phpMQTT详解以及处理使用过程中内存耗死问题
- MQTT--物联网(IoT)消息推送协议
- php实现mqtt发布/发送 消息到主题
- Mqtt.js 的WSS链接
- emqx
- 如何在 PHP 项目中使用 MQTT
- emqx 修改dashboard 密码
- 其他
- Windows 系统中单机最大TCP的连接数详解
- EMQX
- Linux系统EMQX设置开机自启
- Centos7 EMQX部署
- docker安装 EMQX 免费版 docker安装并配置持久化到服务器
- 实时数仓
- 网易云音乐基于 Flink + Kafka 的实时数仓建设实践
- 实时数仓-基于Flink1.11的SQL构建实时数仓探索实践
- 安全
- 网站如何保护用户的密码
- 关于web项目sessionID欺骗的问题
- php的sessionid可以伪造,不要用来做防刷新处理了
- DVWA-Weak Session IDs (弱会话)漏洞利用方式
- 保证接口数据安全的10种方案
- cookie和session的窃取
- 万能密码漏洞
- 黑客如何快速查找网站后台地址方法整理
- 网站后台万能密码/10大常用弱口令
- 万能密码漏洞02
- 大多数网站后台管理的几个常见的安全问题注意防范
- token可以被窃取吗_盗取token
- token被劫持[token被劫持如何保证接口安全性]
- PHP给后台管理系统加安全防护机制的一些方案
- php - 重新生成 session ID
- 隐藏响应中的server和X-Powered-By
- PHP会话控制之如何正确设置session_name
- Session攻击001
- PHP防SQL注入代码,PHP 预防CSRF、XSS、SQL注入攻击
- php25个安全实践
- php架构师 系统管理员必须知道的PHP安全实践
- 版本控制
- Linux服务器关联Git,通过执行更新脚本实现代码同步
- PHP通过exec执行git pull
- git 在linux部署并从windows上提交代码到linux
- git上传到linux服务器,git一键部署代码到远程服务器(linux)
- linux更新git命令,使用Linux定时脚本更新服务器的git代码
- git異常
- 如何解决remote: The project you were looking for could not be found
- git status显示大量文件修改的原因是什么
- PHPstorm批量修改文件换行符CRLF为LF
- git使用
- git常用命令大全
- centos git保存账户密码
- GIT 常用命令
- git怎样还原修改
- Git 如何放弃所有本地修改的方法
- Git忽略文件模式改变
- git: 放弃所有本地修改
- Git三种方法从远程仓库拉取指定的某一个分支
- 杂七杂八
- h5视频
- H5浏览器支持播放格式:H264 AVCA的MP4格式,不能转换为mpeg-4格式,
- iOS无法播放MP4视频文件的解决方案 mp4视频iphone播放不了怎么办
- h5点播播放mp4视频遇到的坑,ios的h5不能播放视频等
- 【Linux 并发请求数】支持多少并发请求数
- Linux下Apache服务器并发优化
- 缓存
- redis
- Linux启动PHP的多进程任务与守护redis队列
- 重启redis命令
- golang