
### 联合索引
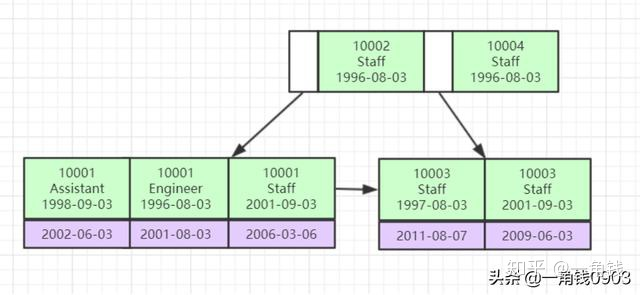
联合索引的底层存储结构
比较相等时,先比较第一列的值,如果相等,再继续比较第二列,以此类推
#### 为什么要使用联合索引
* 减少开销:建一个联合索引(col1,col2,col3),实际相当于建了(col1),(col1,col2),(col1,col2,col3)三个索引。每多一个索引,都会增加写操作的开销和磁盘空间的开销。对于大量数据的表,使用联合索引会大大的减少开销;-- 待学习
* 覆盖索引:对联合索引(col1,col2,col3),如果有如下的sql: select col1,col2,col3 from test where col1=1 and col2=2。那么MySQL可以直接通过遍历索引取得数据,而无需回表,这减少了很多的随机io操作。减少io操作,特别的随机io其实是dba主要的优化策略。所以,在真正的实际应用中,覆盖索引是主要的提升性能的优化手段之一;
* 效率高:索引列越多,通过索引筛选出的数据越少。有1000W条数据的表,有如下sql:select*from table where col1=1 and col2=2 and col3=3,假设假设每个条件可以筛选出10%的数据,如果只有单值索引,那么通过该索引能筛选出1000W*10%=100w条数据,然后再回表从100w条数据中找到符合col2=2 and col3= 3的数据,然后再排序,再分页;如果是联合索引,通过索引筛选出1000w*10%*10% *10%=1w,效率提升可想而知
- 概述
- CAP理论
- BASE理论
- ACID
- 分布式系统相关技术
- 主流数据库连接池
- 基础
- 系统单点
- 负载均衡
- HTTP重定向负载均衡
- DNS域名解析负载均衡
- 反向代理负载均衡
- IP负载均衡
- 数据链路层负载均衡
- 负载均衡算法
- 轮询法(Round Robin)
- 加权轮询(Weight Round Robin)
- 随机算法(Random)
- 源地址Hash算法
- 加权随机法(Weight Random)
- 最小连接数法(Least Connections)
- 接入层负载均衡
- 软件架构
- 性能
- 性能测试指标
- 响应时间
- 并发数
- 吞吐量
- 性能计数器
- 性能测试方法
- 性能测试报告
- 性能优化
- Web前端性能优化
- 应用服务器性能优化
- 可用性
- 服务降级
- 伸缩性
- 扩展性
- 事件驱动架构
- 安全性
- 信息加密技术
- 分布式系统概述
- 自动化
- 分布式唯一ID
- 幂等设计
- 分布式锁
- 脑裂
- 一致性原理
- Paxos
- Zab
- Raft
- 分布式远程服务调用
- RMI
- Spring RMI
- WebService
- SOA服务架构
- 微服务架构
- 微服务的九大特性
- 服务注册和发现
- 解决方案及组件
- 分布式网关
- 注册中心
- Zookeeper
- ZNode
- Watch接口
- 持久节点-配置中心实现原理
- 临时节点-注册中心
- Zookeeper选举
- Zookeeper角色
- ZooKeeper工作原理
- 选主流程
- 同步流程
- Leader工作流程
- Follower工作流程
- 常见限流算法
- 计数器算法
- 漏桶算法
- 令牌桶算法
- 滑动窗口
- 计数器&滑动窗口
- 断路器
- 大流量高并发高可用
- 高可用
- 高并发/大流量
- 分布式缓存系统
- 基本概念
- 缓存命中率
- 缓存最大元素
- 缓存回收策略
- 回收算法
- 缓存穿透与缓存雪崩
- CDN缓存
- 缓存分类
- memcached
- 客户端路由原理
- 内存管理机制
- Redis
- Redis数据模型
- redisObject/Redis type/Redis encoding
- 命令的类型检查和多态
- skiplist跳跃表
- 为什么使用跳跃表
- redis-内存管理机制
- Redis淘汰策略
- Redis持久化策略
- Redis并发竞争
- redis主从复制
- Redis集群实现方案
- Redis Cluster
- redis事务
- Redis-Sentinel
- Redis适用场景
- Redis客户端
- redis rehash原理
- dict数据结构
- 触发rehash的条件
- 渐进式rehash
- 渐进式rehash过程
- Redis多线程版本
- 缓存实际应用
- 堆缓存-Guava Cache
- 主要参数
- Caffeine
- Spring注解缓存
- 分布式存储
- Database
- AUTOCOMMIT
- 脏读&幻读&不可重复读
- 子查询
- 连接
- 内连接
- 自连接
- 自然连接
- 外连接
- 组合查询
- 隔离级别
- 数据库范式
- 索引实现机制
- 数据库拆分
- 表分区
- 分库
- 分表
- MySQL
- MySQL基础架构
- 锁分类
- 排它锁&独占锁
- 共享锁
- 间隙锁
- 表级锁
- 存储引擎
- 磁盘IO
- 磁盘结构图
- 磁盘数据读写原理
- MySQL索引原理
- B+树索引
- 局部性原理
- 索引数据结构
- 联合索引
- 最左前缀匹配原则
- 建索引的几大原则
- 数据文件和索引文件
- 执行计划explain
- 常见问题
- 数据页
- MYSQL单表存储量计算
- 回表
- 索引覆盖
- 索引下推
- 页分裂和页合并
- InnoDB
- innodb索引
- Innodb引擎的底层实现
- MyISAM
- MyISAM引擎的底层实现
- MVCC
- Next-Key Locks
- MySQL索引类型
- MYSQL复制
- 主从复制
- 读写分离
- MySQL Dual-Master
- 分库分表实现方案
- MySQL事务实现原理
- MYSQL调优
- 性能优化
- HBase
- 不停机分库分表迁移
- RDBMS&NoSQL
- 分布式事务
- 协议或事务模型
- X/Open XA协议
- 分布式事务编程接口规范JTA
- TCC模型
- 解决方案
- 两阶段提交2PC
- 三阶段提交3PC
- Seata
- 分布式事务Seata产品模块
- AT模式
- TCC模式
- Saga模式
- XA模式
- 基于消息中间件的最终一致性事务方案
- 消息队列
- AMQP
- JMS
- ActiveMQ
- RabbitMQ
- RocketMQ
- RocketMQ基本概念
- 主要特性
- 分区顺序消息
- 全局顺序消息
- 消息可靠性
- 定时消息
- 消息重试
- 死信队列
- 分布式事务消息
- RocketMQ架构
- Producer
- Consumer
- NameServer
- Broker
- RocketMQ设计
- 消息存储
- 页缓存与内存映射
- 消息刷盘
- 通信机制
- console控制台
- RocketMQ部署架构
- Kafka
- Pulsar
- MQ消息重复消费与丢失
- 主流消息队列比较
- 分布式调度系统
- 分布式搜索
- 分布式计算
- 架构案例
- 秒杀业务
- 秒杀整体架构
- 常见的监控系统
- 小米手机抢购秒杀方案
- 架构师领导艺术
- 架构师箴言
- 技术leader核心职责
- WEB服务器
- Servlet
- Servlet实现
- Servlet生命周期
- Servlet容器工作模式
- Servlet工作原理
- servlet线程安全
- CGI&FastCGI
- CGI
- FastCGI
- FastCGI与CGI特点
- CGI与Servlet比较
- HTTP Server
- Nginx
- Apache
- Nginx与Apache比较
- Application Server
- Tomcat
- Tomcat总体架构
- Connector
- 连接器核心功能
- ProtocolHandler
- EndPoint
- Processor
- Adapter
- Container
- 请求定位Servlet的过程
- Lifecycle生命周期
- Tomcat模块设计
- Tomcat实例
- Tomcat运行原理
- spring & servlet
- Tomcat启动流程
- Tomcat支持的I/O模型
- Tomcat应用层协议
- Tomcat类加载机制
- Tomcat类加载器
- Tomcat类加载器层次
- Apache+Tomcat
- 序列化
- XML&JSON
- JSON
- JAVA原生序列化
- hessian
- 常见中间件
- Canal
- Databus
- ELK日志套件
- 数据库连接池
- spring状态机
- 常见解决方案
- 二维码扫码登录原理
- 前沿技术
- Saas服务
- 服务网格(Service Mesh)
- 云原生
- 常见面试问题
- Redis持久化的几种方式
- Redis的缓存失效策略
- 附录
- 二将军问题
- 常见问题定位步骤
- 如何快速熟悉新系统
- 制定技术方案套路
- NUMA陷阱