
第一次听到“消息队列”这个词时,不知你是不是和我反应一样,感觉很高阶很厉害的样子,其实当我们了解了消息队列之后,发现它与普通的技术类似,当我们熟悉之后,也能很快地上手并使用。
我们本课时的面试题是,消息队列的使用场景有哪些?如何手动实现一个消息队列和延迟消息队列?
#### 典型回答
消息队列的使用场景有很多,最常见的使用场景有以下几个。
* [ ] 1.商品秒杀
比如,我们在做秒杀活动时,会发生短时间内出现爆发式的用户请求,如果不采取相关的措施,会导致服务器忙不过来,响应超时的问题,轻则会导致服务假死,重则会让服务器直接宕机,给用户带来的体验也非常不好。如果这个时候加上了消息队列,服务器接收到用户的所有请求后,先把这些请求全部写入到消息队列中再排队处理,这样就不会导致同时处理多个请求的情况;如果消息队列长度超过可以承载的最大数量,那么我们可以抛弃当前用户的请求,通知前台用户“页面出错啦,请重新刷新”等提示,这样就会有更好的交互体验。
* [ ] 2.系统解耦
使用了消息队列之后,我们可以把系统的业务功能模块化,实现系统的解耦。例如,在没有使用消息队列之前,当前台用户完善了个人信息之后,首先我们需要更新用户的资料,再添加一条用户信息修改日志。但突然有一天产品经理提了一个需求,在前台用户信息更新之后,需要给此用户的增加一定的积分奖励,然后没过几天产品经理又提了一个需求,在前台用户信息更新之后,不但要增加积分奖励,还要增加用户的经验值,但没过几天产品经理的需求又变了,他要求完善资料无需增加用户的积分了,这样反反复复、来来回回的折腾,我想研发的同学一定受不了,但这是互联网公司的常态,那我们有没有一劳永逸的办法呢?
没错,这个时候我们想到了使用消息队列来实现系统的解耦,每个功能的实现独立开,只需要一个订阅或者取消订阅的开关就可以了,当需要增加功能时,只需要打开订阅“用户信息完善”的队列就行,如果过两天不用了,再把订阅的开关关掉就行了,这样我们就不用来来回回的改业务代码了,也就轻松的实现了系统模块间的解耦。
* [ ] 3.日志记录
我们大部分的日志记录行为其实是和前台用户操作的主业务没有直接关系的,只是我们的运营人和经营人员需要拿到这部分用户操作的日志信息,来进行用户行为分析或行为监控。在我们没有使用消息队列之前,笼统的做法是当有用户请求时,先处理用户的请求再记录日志,这两个操作是放在一起的,而前台用户也需要等待日志添加完成之后才能拿到后台的响应信息,这样其实浪费了前台用户的部分时间。此时我们可以使用消息队列,当响应完用户请求之后,只需要把这个操作信息放入消息队列之后,就可以直接返回结果给前台用户了,无序等待日志处理和日志添加完成,从而缩短了前台用户的等待时间。
我们可以通过 JDK 提供的 Queue 来实现自定义消息队列,使用 DelayQueue 实现延迟消息队列。
#### 考点分析
对于消息队列的考察更侧重于消息队列的核心思想,因为只有理解了什么是消息队列?以及什么情况下要用消息队列?才能解决我们日常工作中遇到的问题,而消息队列的具体实现,只需要掌握一个消息中间件的使用即可,因为消息队列中间件的核心实现思路是一致的,不但如此,消息队列中间件的使用也大致类似,只要掌握了一个就能触类旁通的用好其他消息中间件。
和本课时相关的面试题,还有以下这两个:
* 介绍一个你熟悉的消息中间件?
* 如何手动实现消息队列?
#### 知识扩展
* [ ] 1.常用消息中间件 RabbitMQ
目前市面上比较常用的 MQ(Message Queue,消息队列)中间件有 RabbitMQ、Kafka、RocketMQ,如果是轻量级的消息队列可以使用 Redis 提供的消息队列,本课时我们先来介绍一下 RabbitMQ,其他消息中间件将会在第 15 课时中单独介绍。
RabbitMQ 是一个老牌开源的消息中间件,它实现了标准的 AMQP(Advanced Message Queuing Protocol,高级消息队列协议)消息中间件,使用 Erlang 语言开发,支持集群部署,和多种客户端语言混合调用,它支持的主流开发语言有以下这些:
* Java and Spring
* .NET
* Ruby
* Python
* PHP
* JavaScript and Node
* Objective-C and Swift
* Rust
* Scala
* Go
更多支持语言,请点击这里访问官网查看。
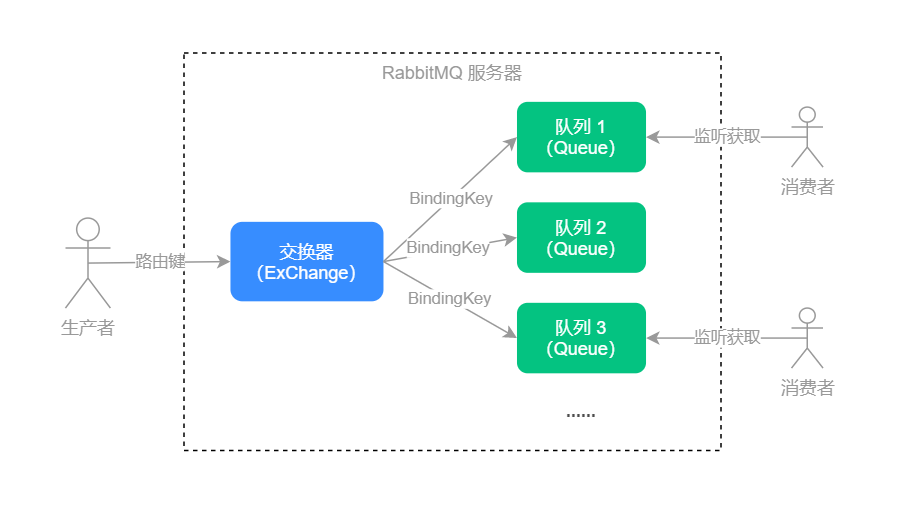
RabbitMQ 中有 3 个重要的概念:生产者、消费者和代理。
* 生产者:消息的创建者,负责创建和推送数据到消息服务器。
* 消费者:消息的接收方,用于处理数据和确认消息。
* 代理:也就是 RabbitMQ 服务本身,它用于扮演“快递”的角色,因为它本身并不生产消息,只是扮演了“快递”的角色,把消息进行暂存和传递。
它们的运行流程,如下图所示:
RabbitMQ 具备以下几个优点:
* 支持持久化,RabbitMQ 支持磁盘持久化功能,保证了消息不会丢失;
* 高并发,RabbitMQ 使用了 Erlang 开发语言,Erlang 是为电话交换机开发的语言,天生自带高并发光环和高可用特性;
* 支持分布式集群,正是因为 Erlang 语言实现的,因此 RabbitMQ 集群部署也非常简单,只需要启动每个节点并使用 --link 把节点加入到集群中即可,并且 RabbitMQ 支持自动选主和自动容灾;
* 支持多种语言,比如 Java、.NET、PHP、Python、JavaScript、Ruby、Go 等;
* 支持消息确认,支持消息消费确认(ack)保证了每条消息可以被正常消费;
* 它支持很多插件,比如网页控制台消息管理插件、消息延迟插件等,RabbitMQ 的插件很多并且使用都很方便。
RabbitMQ 的消息类型,分为以下四种:
* direct(默认类型)模式,此模式为一对一的发送方式,也就是一条消息只会发送给一个消费者;
* headers 模式,允许你匹配消息的 header 而非路由键(RoutingKey),除此之外 headers 和 direct 的使用完全一致,但因为 headers 匹配的性能很差,几乎不会被用到;
* fanout 模式,为多播的方式,会把一个消息分发给所有的订阅者;
* topic 模式,为主题订阅模式,允许使用通配符(#、*)匹配一个或者多个消息,我可以使用“cn.mq.#”匹配到多个前缀是“cn.mq.xxx”的消息,比如可以匹配到“cn.mq.rabbit”、“cn.mq.kafka”等消息。
* [ ] 2.自定义消息队列
我们可使用 Queue 来实现消息队列,Queue 大体可分为以下三类:
* **双端队列(Deque)**是 Queue 的子类也是 Queue 的补充类,头部和尾部都支持元素插入和获取;
* 阻塞队列指的是在元素操作时(添加或删除),如果没有成功,会阻塞等待执行,比如当添加元素时,如果队列元素已满,队列则会阻塞等待直到有空位时再插入;
* 非阻塞队列,和阻塞队列相反,它会直接返回操作的结果,而非阻塞等待操作,双端队列也属于非阻塞队列。
自定义消息队列的实现代码如下:
```
import java.util.LinkedList;
import java.util.Queue;
public class CustomQueue {
// 定义消息队列
private static Queue<String> queue = new LinkedList<>();
public static void main(String[] args) {
producer(); // 调用生产者
consumer(); // 调用消费者
}
// 生产者
public static void producer() {
// 添加消息
queue.add("first message.");
queue.add("second message.");
queue.add("third message.");
}
// 消费者
public static void consumer() {
while (!queue.isEmpty()) {
// 消费消息
System.out.println(queue.poll());
}
}
}
```
以上程序的执行结果是:
```
first message.
second message.
third message.
```
可以看出消息是以先进先出顺序进行消费的。
实现自定义延迟队列需要实现 Delayed 接口,重写 getDelay() 方法,延迟队列完整实现代码如下:
```
import lombok.Getter;
import lombok.Setter;
import java.text.DateFormat;
import java.util.Date;
import java.util.concurrent.DelayQueue;
import java.util.concurrent.Delayed;
import java.util.concurrent.TimeUnit;
/**
* 自定义延迟队列
*/
public class CustomDelayQueue {
// 延迟消息队列
private static DelayQueue delayQueue = new DelayQueue();
public static void main(String[] args) throws InterruptedException {
producer(); // 调用生产者
consumer(); // 调用消费者
}
// 生产者
public static void producer() {
// 添加消息
delayQueue.put(new MyDelay(1000, "消息1"));
delayQueue.put(new MyDelay(3000, "消息2"));
}
// 消费者
public static void consumer() throws InterruptedException {
System.out.println("开始执行时间:" +
DateFormat.getDateTimeInstance().format(new Date()));
while (!delayQueue.isEmpty()) {
System.out.println(delayQueue.take());
}
System.out.println("结束执行时间:" +
DateFormat.getDateTimeInstance().format(new Date()));
}
/**
* 自定义延迟队列
*/
static class MyDelay implements Delayed {
// 延迟截止时间(单位:毫秒)
long delayTime = System.currentTimeMillis();
// 借助 lombok 实现
@Getter
@Setter
private String msg;
/**
* 初始化
* @param delayTime 设置延迟执行时间
* @param msg 执行的消息
*/
public MyDelay(long delayTime, String msg) {
this.delayTime = (this.delayTime + delayTime);
this.msg = msg;
}
// 获取剩余时间
@Override
public long getDelay(TimeUnit unit) {
return unit.convert(delayTime - System.currentTimeMillis(), TimeUnit.MILLISECONDS);
}
// 队列里元素的排序依据
@Override
public int compareTo(Delayed o) {
if (this.getDelay(TimeUnit.MILLISECONDS) > o.getDelay(TimeUnit.MILLISECONDS)) {
return 1;
} else if (this.getDelay(TimeUnit.MILLISECONDS) < o.getDelay(TimeUnit.MILLISECONDS)) {
return -1;
} else {
return 0;
}
}
@Override
public String toString() {
return this.msg;
}
}
}
```
以上程序的执行结果是:
```
开始执行时间:2020-4-2 16:17:28
消息1
消息2
结束执行时间:2020-4-2 16:17:31
```
可以看出,消息 1 和消息 2 都实现了延迟执行的功能。
#### 小结
本课时讲了消息队列的使用场景:商品秒杀、系统解耦和日志记录,我们还介绍了 RabbitMQ 以及它的消息类型和它的特点等内容,同时还使用 Queue 的子类 LinkedList 实现了自定义消息队列,使用 DelayQueue 实现了自定义延迟消息队列。
#### 课后问答
* 1、
- 前言
- 开篇词
- 开篇词:大厂技术面试“潜规则”
- 模块一:Java 基础
- 第01讲:String 的特点是什么?它有哪些重要的方法?
- 第02讲:HashMap 底层实现原理是什么?JDK8 做了哪些优化?
- 第03讲:线程的状态有哪些?它是如何工作的?
- 第04讲:详解 ThreadPoolExecutor 的参数含义及源码执行流程?
- 第05讲:synchronized 和 ReentrantLock 的实现原理是什么?它们有什么区别?
- 第06讲:谈谈你对锁的理解?如何手动模拟一个死锁?
- 第07讲:深克隆和浅克隆有什么区别?它的实现方式有哪些?
- 第08讲:动态代理是如何实现的?JDK Proxy 和 CGLib 有什么区别?
- 第09讲:如何实现本地缓存和分布式缓存?
- 第10讲:如何手写一个消息队列和延迟消息队列?
- 模块二:热门框架
- 第11讲:底层源码分析 Spring 的核心功能和执行流程?(上)
- 第12讲:底层源码分析 Spring 的核心功能和执行流程?(下)
- 第13讲:MyBatis 使用了哪些设计模式?在源码中是如何体现的?
- 第14讲:SpringBoot 有哪些优点?它和 Spring 有什么区别?
- 第15讲:MQ 有什么作用?你都用过哪些 MQ 中间件?
- 模块三:数据库相关
- 第16讲:MySQL 的运行机制是什么?它有哪些引擎?
- 第17讲:MySQL 的优化方案有哪些?
- 第18讲:关系型数据和文档型数据库有什么区别?
- 第19讲:Redis 的过期策略和内存淘汰机制有什么区别?
- 第20讲:Redis 怎样实现的分布式锁?
- 第21讲:Redis 中如何实现的消息队列?实现的方式有几种?
- 第22讲:Redis 是如何实现高可用的?
- 模块四:Java 进阶
- 第23讲:说一下 JVM 的内存布局和运行原理?
- 第24讲:垃圾回收算法有哪些?
- 第25讲:你用过哪些垃圾回收器?它们有什么区别?
- 第26讲:生产环境如何排除和优化 JVM?
- 第27讲:单例的实现方式有几种?它们有什么优缺点?
- 第28讲:你知道哪些设计模式?分别对应的应用场景有哪些?
- 第29讲:红黑树和平衡二叉树有什么区别?
- 第30讲:你知道哪些算法?讲一下它的内部实现过程?
- 模块五:加分项
- 第31讲:如何保证接口的幂等性?常见的实现方案有哪些?
- 第32讲:TCP 为什么需要三次握手?
- 第33讲:Nginx 的负载均衡模式有哪些?它的实现原理是什么?
- 第34讲:Docker 有什么优点?使用时需要注意什么问题?
- 彩蛋
- 彩蛋:如何提高面试成功率?