
细心的你可能发现了,本系列课程中竟然出现了三个课时都是在说消息队列,第 10 课时讲了程序级别的消息队列以及延迟消息队列的实现,而第 15 课时讲了常见的消息队列中间件 RabbitMQ、Kafka 等,由此可见消息队列在整个 Java 技术体系中的重要程度。本课时我们将重点来看一下 Redis 是如何实现消息队列的。
我们本课时的面试题是,在 Redis 中实现消息队列的方式有几种?
#### 典型回答
早在 Redis 2.0 版本之前使用 Redis 实现消息队列的方式有两种:
* 使用 List 类型实现
* 使用 ZSet 类型实现
其中使用**List 类型实现的方式最为简单和直接**,它主要是通过 lpush、rpop 存入和读取实现消息队列的,如下图所示:
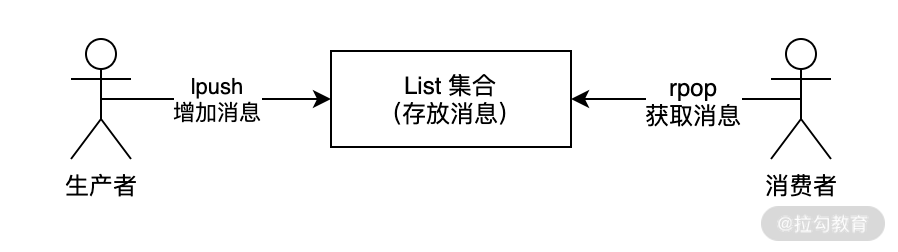
lpush 可以把最新的消息存储到消息队列(List 集合)的首部,而 rpop 可以读取消息队列的尾部,这样就实现了先进先出,如下图所示:
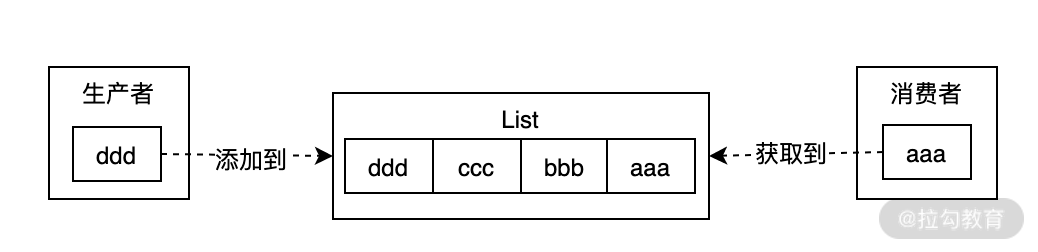
命令行的实现命令如下:
```
127.0.0.1:6379> lpush mq "java" #推送消息 java
(integer) 1
127.0.0.1:6379> lpush mq "msg" #推送消息 msg
(integer) 2
127.0.0.1:6379> rpop mq #接收到消息 java
"java"
127.0.0.1:6379> rpop mq #接收到消息 msg
"mq"
```
其中,mq 相当于消息队列的名称,而 lpush 用于生产并添加消息,而 rpop 用于拉取并消费消息。
使用 List 实现消息队列的优点是消息可以被持久化,List 可以借助 Redis 本身的持久化功能,AOF 或者是 RDB 或混合持久化的方式,用于把数据保存至磁盘,这样当 Redis 重启之后,消息不会丢失。
但使用 List 同样存在一定的问题,比如消息不支持重复消费、没有按照主题订阅的功能、不支持消费消息确认等。
ZSet 实现消息队列的方式和 List 类似,它是利用 zadd 和 zrangebyscore 来实现存入和读取消息的,这里就不重复叙述了。但 ZSet 的实现方式更为复杂一些,因为 ZSet 多了一个分值(score)属性,我们可以使用它来实现更多的功能,比如用它来存储时间戳,以此来实现延迟消息队列等。
ZSet 同样具备持久化的功能,List 存在的问题它也同样存在,不但如此,使用 ZSet 还不能存储相同元素的值。因为它是有序集合,有序集合的存储元素值是不能重复的,但分值可以重复,也就是说当消息值重复时,只能存储一条信息在 ZSet 中。
在 Redis 2.0 之后 Redis 就新增了专门的发布和订阅的类型,Publisher(发布者)和 Subscriber(订阅者)来实现消息队列了,它们对应的执行命令如下:
* 发布消息,publish channel "message"
* 订阅消息,subscribe channel
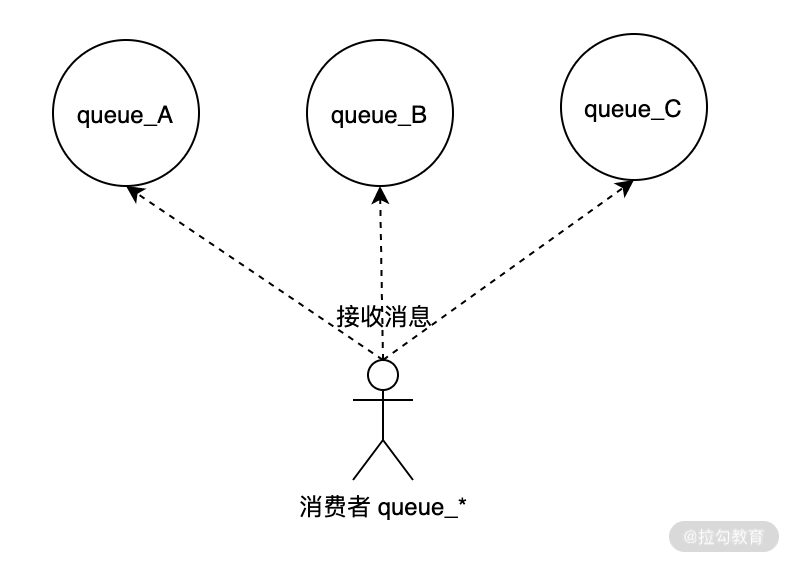
使用发布和订阅的类型,我们可以实现主题订阅的功能,也就是 Pattern Subscribe 的功能。因此我们可以使用一个消费者“queue_*”来订阅所有以“queue_”开头的消息队列,如下图所示:
发布订阅模式的优点很明显,但同样存在以下 3 个问题:
*
无法持久化保存消息,如果 Redis 服务器宕机或重启,那么所有的消息将会丢失;
* 发布订阅模式是“发后既忘”的工作模式,如果有订阅者离线重连之后就不能消费之前的历史消息;
* 不支持消费者确认机制,稳定性不能得到保证,例如当消费者获取到消息之后,还没来得及执行就宕机了。因为没有消费者确认机制,Redis 就会误以为消费者已经执行了,因此就不会重复发送未被正常消费的消息了,这样整体的 Redis 稳定性就被没有办法得到保障了。
然而在 Redis 5.0 之后新增了 Stream 类型,我们就可以使用 Stream 的 xadd 和 xrange 来实现消息的存入和读取了,并且 Stream 提供了 xack 手动确认消息消费的命令,用它我们就可以实现消费者确认的功能了,使用命令如下:
```
127.0.0.1:6379> xack mq group1 1580959593553-0
(integer) 1
```
相关语法如下:
```
xack key group-key ID [ID ...]
```
消费确认增加了消息的可靠性,一般在业务处理完成之后,需要执行 ack 确认消息已经被消费完成,整个流程的执行如下图所示:
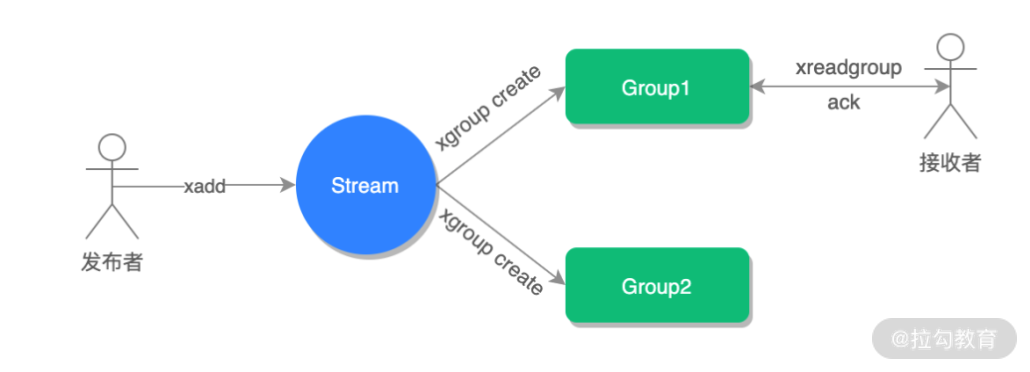
其中“Group”为群组,消费者也就是接收者需要订阅到群组才能正常获取到消息。
以上就 Redis 实现消息队列的四种方式,他们分别是:
* 使用 List 实现消息队列;
* 使用 ZSet 实现消息队列;
* 使用发布订阅者模式实现消息队列;
* 使用 Stream 实现消息队列。
#### 考点分析
本课时的题目比较全面的考察了面试者对于 Redis 整体知识框架和新版本特性的理解和领悟。早期版本中比较常用的实现消息队列的方式是 List、ZSet 和发布订阅者模式,使用 Stream 来实现消息队列是近两年才流行起来的方案,并且很多企业也没有使用到 Redis 5.0 这么新的版本。因此只需回答出前三种就算及格了,而 Stream 方式实现消息队列属于附加题,如果面试中能回答上来的话就更好了,它体现了你对新技术的敏感度与对技术的热爱程度,属于面试中的加分项。
和此知识点相关的面试题还有以下几个:
* 在 Java 代码中使用 List 实现消息队列会有什么问题?应该如何解决?
* 在程序中如何使用 Stream 来实现消息队列?
#### 知识扩展
* [ ] 使用 List 实现消息队列
在 Java 程序中我们需要使用 Redis 客户端框架来辅助程序操作 Redis,比如 Jedis 框架。
使用 Jedis 框架首先需要在 pom.xml 文件中添加 Jedis 依赖,配置如下:
```
<!-- https://mvnrepository.com/artifact/redis.clients/jedis -->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>${version}</version>
</dependency>
```
List 实现消息队列的完整代码如下:
```
import redis.clients.jedis.Jedis;
publicclass ListMQTest {
public static void main(String[] args){
// 启动一个线程作为消费者
new Thread(() -> consumer()).start();
// 生产者
producer();
}
/**
* 生产者
*/
public static void producer() {
Jedis jedis = new Jedis("127.0.0.1", 6379);
// 推送消息
jedis.lpush("mq", "Hello, List.");
}
/**
* 消费者
*/
public static void consumer() {
Jedis jedis = new Jedis("127.0.0.1", 6379);
// 消费消息
while (true) {
// 获取消息
String msg = jedis.rpop("mq");
if (msg != null) {
// 接收到了消息
System.out.println("接收到消息:" + msg);
}
}
}
}
```
以上程序的运行结果是:
```
接收到消息:Hello, Java.
```
但是以上的代码存在一个问题,可以看出以上消费者的实现是通过 while 无限循环来获取消息,但如果消息的空闲时间比较长,一直没有新任务,而 while 循环不会因此停止,它会一直执行循环的动作,这样就会白白浪费了系统的资源。
此时我们可以借助 Redis 中的阻塞读来替代 rpop 的方法就可以解决此问题,具体实现代码如下:
```
import redis.clients.jedis.Jedis;
public class ListMQExample {
public static void main(String[] args) throws InterruptedException {
// 消费者
new Thread(() -> bConsumer()).start();
// 生产者
producer();
}
/**
* 生产者
*/
public static void producer() throws InterruptedException {
Jedis jedis = new Jedis("127.0.0.1", 6379);
// 推送消息
jedis.lpush("mq", "Hello, Java.");
Thread.sleep(1000);
jedis.lpush("mq", "message 2.");
Thread.sleep(2000);
jedis.lpush("mq", "message 3.");
}
/**
* 消费者(阻塞版)
*/
public static void bConsumer() {
Jedis jedis = new Jedis("127.0.0.1", 6379);
while (true) {
// 阻塞读
for (String item : jedis.brpop(0,"mq")) {
// 读取到相关数据,进行业务处理
System.out.println(item);
}
}
}
}
```
以上程序的运行结果是:
```
接收到消息:Hello, Java.
```
以上代码是经过改良的,我们使用 brpop 替代 rpop 来读取最后一条消息,就可以解决 while 循环在没有数据的情况下,一直循环消耗系统资源的情况了。brpop 中的 b 是 blocking 的意思,表示阻塞读,也就是当队列没有数据时,它会进入休眠状态,当有数据进入队列之后,它才会“苏醒”过来执行读取任务,这样就可以解决 while 循环一直执行消耗系统资源的问题了。
使用 Stream 实现消息队列
在开始实现消息队列之前,我们必须先创建分组才行,因为消费者需要关联分组信息才能正常运行,具体实现代码如下:
```
import com.google.gson.Gson;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.StreamEntry;
import redis.clients.jedis.StreamEntryID;
import utils.JedisUtils;
import java.util.AbstractMap;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
public class StreamGroupExample {
private static final String _STREAM_KEY = "mq"; // 流 key
private static final String _GROUP_NAME = "g1"; // 分组名称
private static final String _CONSUMER_NAME = "c1"; // 消费者 1 的名称
private static final String _CONSUMER2_NAME = "c2"; // 消费者 2 的名称
public static void main(String[] args) {
// 生产者
producer();
// 创建消费组
createGroup(_STREAM_KEY, _GROUP_NAME);
// 消费者 1
new Thread(() -> consumer()).start();
// 消费者 2
new Thread(() -> consumer2()).start();
}
/**
* 创建消费分组
* @param stream 流 key
* @param groupName 分组名称
*/
public static void createGroup(String stream, String groupName) {
Jedis jedis = JedisUtils.getJedis();
jedis.xgroupCreate(stream, groupName, new StreamEntryID(), true);
}
/**
* 生产者
*/
public static void producer() {
Jedis jedis = JedisUtils.getJedis();
// 添加消息 1
Map<String, String> map = new HashMap<>();
map.put("data", "redis");
StreamEntryID id = jedis.xadd(_STREAM_KEY, null, map);
System.out.println("消息添加成功 ID:" + id);
// 添加消息 2
Map<String, String> map2 = new HashMap<>();
map2.put("data", "java");
StreamEntryID id2 = jedis.xadd(_STREAM_KEY, null, map2);
System.out.println("消息添加成功 ID:" + id2);
}
/**
* 消费者 1
*/
public static void consumer() {
Jedis jedis = JedisUtils.getJedis();
// 消费消息
while (true) {
// 读取消息
Map.Entry<String, StreamEntryID> entry = new AbstractMap.SimpleImmutableEntry<>(_STREAM_KEY,
new StreamEntryID().UNRECEIVED_ENTRY);
// 阻塞读取一条消息(最大阻塞时间120s)
List<Map.Entry<String, List<StreamEntry>>> list = jedis.xreadGroup(_GROUP_NAME, _CONSUMER_NAME, 1,
120 * 1000, true, entry);
if (list != null && list.size() == 1) {
// 读取到消息
Map<String, String> content = list.get(0).getValue().get(0).getFields(); // 消息内容
System.out.println("Consumer 1 读取到消息 ID:" + list.get(0).getValue().get(0).getID() +
" 内容:" + new Gson().toJson(content));
}
}
}
/**
* 消费者 2
*/
public static void consumer2() {
Jedis jedis = JedisUtils.getJedis();
// 消费消息
while (true) {
// 读取消息
Map.Entry<String, StreamEntryID> entry = new AbstractMap.SimpleImmutableEntry<>(_STREAM_KEY,
new StreamEntryID().UNRECEIVED_ENTRY);
// 阻塞读取一条消息(最大阻塞时间120s)
List<Map.Entry<String, List<StreamEntry>>> list = jedis.xreadGroup(_GROUP_NAME, _CONSUMER2_NAME, 1,
120 * 1000, true, entry);
if (list != null && list.size() == 1) {
// 读取到消息
Map<String, String> content = list.get(0).getValue().get(0).getFields(); // 消息内容
System.out.println("Consumer 2 读取到消息 ID:" + list.get(0).getValue().get(0).getID() +
" 内容:" + new Gson().toJson(content));
}
}
}
}
```
以上代码运行结果如下:
```
消息添加成功 ID:1580971482344-0
消息添加成功 ID:1580971482415-0
Consumer 1 读取到消息 ID:1580971482344-0 内容:{"data":"redis"}
Consumer 2 读取到消息 ID:1580971482415-0 内容:{"data":"java"}
```
其中,jedis.xreadGroup() 方法的第五个参数 noAck 表示是否自动确认消息,如果设置 true 收到消息会自动确认 (ack) 消息,否则需要手动确认。
可以看出,同一个分组内的多个 consumer 会读取到不同消息,不同的 consumer 不会读取到分组内的同一条消息。
>
小贴士:Jedis 框架要使用最新版,低版本 block 设置大于 0 时,会出现 bug,抛连接超时异常。
#### 小结
本课时我们讲了 Redis 中消息队列的四种实现方式:List 方式、ZSet 方式、发布订阅者模式、Stream 方式,其中发布订阅者模式不支持消息持久化、而其他三种方式支持持久化,并且 Stream 方式支持消费者确认。我们还使用 Jedis 框架完成了 List 和 Stream 的消息队列功能,需要注意的是在 List 中需要使用 brpop 来读取消息,而不是 rpop,这样可以解决没有任务时 ,while 一直循环浪费系统资源的问题。
#### 课后问答
* 1、Stream 如何手动确认消息呢
讲师回复: Streams 有 xack key group-key ID 可以用来确认消息。
- 前言
- 开篇词
- 开篇词:大厂技术面试“潜规则”
- 模块一:Java 基础
- 第01讲:String 的特点是什么?它有哪些重要的方法?
- 第02讲:HashMap 底层实现原理是什么?JDK8 做了哪些优化?
- 第03讲:线程的状态有哪些?它是如何工作的?
- 第04讲:详解 ThreadPoolExecutor 的参数含义及源码执行流程?
- 第05讲:synchronized 和 ReentrantLock 的实现原理是什么?它们有什么区别?
- 第06讲:谈谈你对锁的理解?如何手动模拟一个死锁?
- 第07讲:深克隆和浅克隆有什么区别?它的实现方式有哪些?
- 第08讲:动态代理是如何实现的?JDK Proxy 和 CGLib 有什么区别?
- 第09讲:如何实现本地缓存和分布式缓存?
- 第10讲:如何手写一个消息队列和延迟消息队列?
- 模块二:热门框架
- 第11讲:底层源码分析 Spring 的核心功能和执行流程?(上)
- 第12讲:底层源码分析 Spring 的核心功能和执行流程?(下)
- 第13讲:MyBatis 使用了哪些设计模式?在源码中是如何体现的?
- 第14讲:SpringBoot 有哪些优点?它和 Spring 有什么区别?
- 第15讲:MQ 有什么作用?你都用过哪些 MQ 中间件?
- 模块三:数据库相关
- 第16讲:MySQL 的运行机制是什么?它有哪些引擎?
- 第17讲:MySQL 的优化方案有哪些?
- 第18讲:关系型数据和文档型数据库有什么区别?
- 第19讲:Redis 的过期策略和内存淘汰机制有什么区别?
- 第20讲:Redis 怎样实现的分布式锁?
- 第21讲:Redis 中如何实现的消息队列?实现的方式有几种?
- 第22讲:Redis 是如何实现高可用的?
- 模块四:Java 进阶
- 第23讲:说一下 JVM 的内存布局和运行原理?
- 第24讲:垃圾回收算法有哪些?
- 第25讲:你用过哪些垃圾回收器?它们有什么区别?
- 第26讲:生产环境如何排除和优化 JVM?
- 第27讲:单例的实现方式有几种?它们有什么优缺点?
- 第28讲:你知道哪些设计模式?分别对应的应用场景有哪些?
- 第29讲:红黑树和平衡二叉树有什么区别?
- 第30讲:你知道哪些算法?讲一下它的内部实现过程?
- 模块五:加分项
- 第31讲:如何保证接口的幂等性?常见的实现方案有哪些?
- 第32讲:TCP 为什么需要三次握手?
- 第33讲:Nginx 的负载均衡模式有哪些?它的实现原理是什么?
- 第34讲:Docker 有什么优点?使用时需要注意什么问题?
- 彩蛋
- 彩蛋:如何提高面试成功率?