
“锁”是我们实际工作和面试中无法避开的话题之一,正确使用锁可以保证高并发环境下程序的正确执行,也就是说只有使用锁才能保证多人同时访问时程序不会出现问题。
我们本课时的面试题是,什么是分布式锁?如何实现分布式锁?
#### 典型回答
第 06 课时讲了单机锁的一些知识,包括悲观锁、乐观锁、可重入锁、共享锁和独占锁等内容,但它们都属于单机锁也就是程序级别的锁,如果在分布式环境下使用就会出现锁不生效的问题,因此我们需要使用分布式锁来解决这个问题。
分布式锁是控制分布式系统之间同步访问共享资源的一种方式。是为了解决分布式系统中,不同的系统或是同一个系统的不同主机共享同一个资源的问题,它通常会采用互斥来保证程序的一致性,这就是分布式锁的用途以及执行原理。
分布式锁示意图,如下图所示:
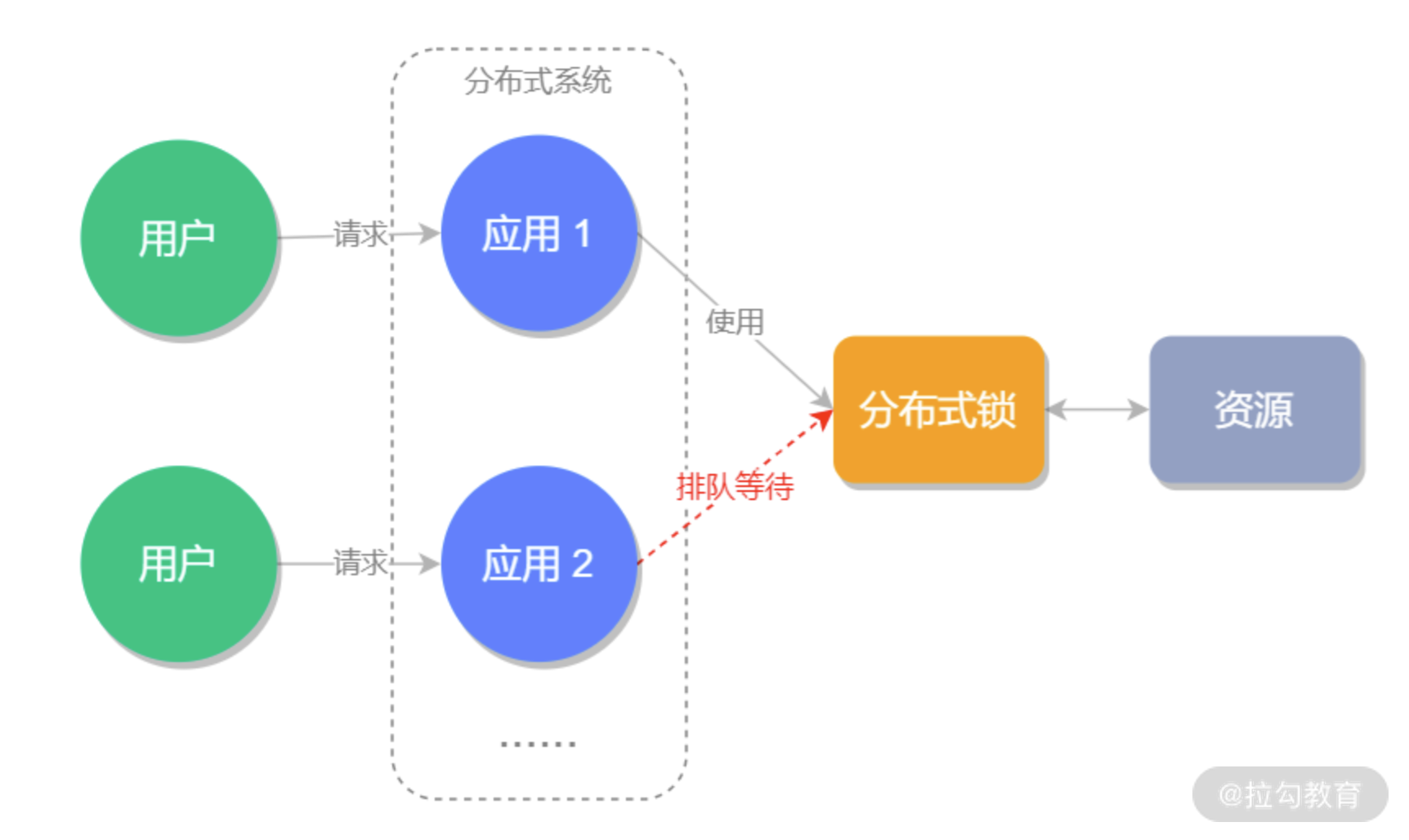
分布式锁的常见实现方式有四种:
* 基于 MySQL 的悲观锁来实现分布式锁,这种方式使用的最少,因为这种实现方式的性能不好,且容易造成死锁;
* 基于 Memcached 实现分布式锁,可使用 add 方法来实现,如果添加成功了则表示分布式锁创建成功;
* 基于 Redis 实现分布式锁,这也是本课时要介绍的重点,可以使用 setnx 方法来实现;
* 基于 ZooKeeper 实现分布式锁,利用 ZooKeeper 顺序临时节点来实现。
由于 MySQL 的执行效率问题和死锁问题,所以这种实现方式会被我们先排除掉,而 Memcached 和 Redis 的实现方式比较类似,但因为 Redis 技术比较普及,所以会优先使用 Redis 来实现分布式锁,而 ZooKeeper 确实可以很好的实现分布式锁。但此技术在中小型公司的普及率不高,尤其是非 Java 技术栈的公司使用的较少,如果只是为了实现分布式锁而重新搭建一套 ZooKeeper 集群,显然实现成本和维护成本太高,所以综合以上因素,我们本文会采用 Redis 来实现分布式锁。
之所以可以使用以上四种方式来实现分布式锁,是因为以上四种方式都属于程序调用的“外部系统”,而分布式的程序是需要共享“外部系统”的,这就是分布式锁得以实现的基本前提。
#### 考点分析
分布式锁的问题看似简单,但却有很多细节需要注意,比如,需要考虑分布式锁的超时问题,如果不设置超时时间的话,可能会导致死锁的产生,所以在对待这个“锁”的问题上,一定不能马虎。和此知识点相关的面试还有以下这些:
* 单机锁有哪些?它为什么不能在分布式环境下使用?
* Redis 是如何实现分布式锁的?可能会遇到什么问题?
* 分布式锁超时的话会有什么问题?如何解决?
#### 知识扩展
* [ ] 单机锁
程序中使用的锁叫单机锁,我们日常中所说的“锁”都泛指单机锁,其分类有很多,大体可分为以下几类:
* 悲观锁,是数据对外界的修改采取保守策略,它认为线程很容易把数据修改掉,因此在整个数据被修改的过程中都会采取锁定状态,直到一个线程使用完,其他线程才可以继续使用,典型应用是 synchronized;
* 乐观锁,和悲观锁的概念恰好相反,乐观锁认为一般情况下数据在修改时不会出现冲突,所以在数据访问之前不会加锁,只是在数据提交更改时,才会对数据进行检测,典型应用是 ReadWriteLock 读写锁;
* 可重入锁,也叫递归锁,指的是同一个线程在外面的函数获取了锁之后,那么内层的函数也可以继续获得此锁,在 Java 语言中 ReentrantLock 和 synchronized 都是可重入锁;
* 独占锁和共享锁,只能被单线程持有的锁叫做独占锁,可以被多线程持有的锁叫共享锁,独占锁指的是在任何时候最多只能有一个线程持有该锁,比如 ReentrantLock 就是独占锁;而 ReadWriteLock 读写锁允许同一时间内有多个线程进行读操作,它就属于共享锁。
单机锁之所以不能应用在分布式系统中是因为,在分布式系统中,每次请求可能会被分配在不同的服务器上,而单机锁是在单台服务器上生效的。如果是多台服务器就会导致请求分发到不同的服务器,从而导致锁代码不能生效,因此会造成很多异常的问题,那么单机锁就不能应用在分布式系统中了。
使用 Redis 实现分布式锁
使用 Redis 实现分布式锁主要需要使用 setnx 方法,也就是 set if not exists(不存在则创建),具体的实现代码如下:
```
127.0.0.1:6379> setnx lock true
(integer) 1 #创建锁成功
#逻辑业务处理...
127.0.0.1:6379> del lock
(integer) 1 #释放锁
```
当执行 setnx 命令之后返回值为 1 的话,则表示创建锁成功,否则就是失败。释放锁使用 del 删除即可,当其他程序 setnx 失败时,则表示此锁正在使用中,这样就可以实现简单的分布式锁了。
但是以上代码有一个问题,就是没有设置锁的超时时间,因此如果出现异常情况,会导致锁未被释放,而其他线程又在排队等待此锁就会导致程序不可用。
有人可能会想到使用 expire 来设置键值的过期时间来解决这个问题,例如以下代码:
```
127.0.0.1:6379> setnx lock true
(integer) 1 #创建锁成功
127.0.0.1:6379> expire lock 30 #设置锁的(过期)超时时间为 30s
(integer) 1
#逻辑业务处理...
127.0.0.1:6379> del lock
(integer) 1 #释放锁
```
但这样执行仍然会有问题,因为 setnx lock true 和 expire lock 30 命令是非原子的,也就是一个执行完另一个才能执行。但如果在 setnx 命令执行完之后,发生了异常情况,那么就会导致 expire 命令不会执行,因此依然没有解决死锁的问题。
这个问题在 Redis 2.6.12 之前一直没有得到有效的处理,当时的解决方案是在客户端进行原子合并操作,于是就诞生了很多客户端类库来解决此原子问题,不过这样就增加了使用的成本。因为你不但要添加 Redis 的客户端,还要为了解决锁的超时问题,需额外的增加新的类库,这样就增加了使用成本,但这个问题在 Redis 2.6.12 版本中得到了有效的处理。
在 Redis 2.6.12 中我们可以使用一条 set 命令来执行键值存储,并且可以判断键是否存在以及设置超时时间了,如下代码所示:
```
127.0.0.1:6379> set lock true ex 30 nx
OK #创建锁成功
```
其中,ex 是用来设置超时时间的,而 nx 是 not exists 的意思,用来判断键是否存在。如果返回的结果为“OK”则表示创建锁成功,否则表示此锁有人在使用。
* [ ] 锁超时
从上面的内容可以看出,使用 set 命令之后好像一切问题都解决了,但在这里我要告诉你,其实并没有。例如,我们给锁设置了超时时间为 10s,但程序的执行需要使用 15s,那么在第 10s 时此锁因为超时就会被释放,这时候线程二在执行 set 命令时正常获取到了锁,于是在很短的时间内 2s 之后删除了此锁,这就造成了锁被误删的情况,如下图所示:
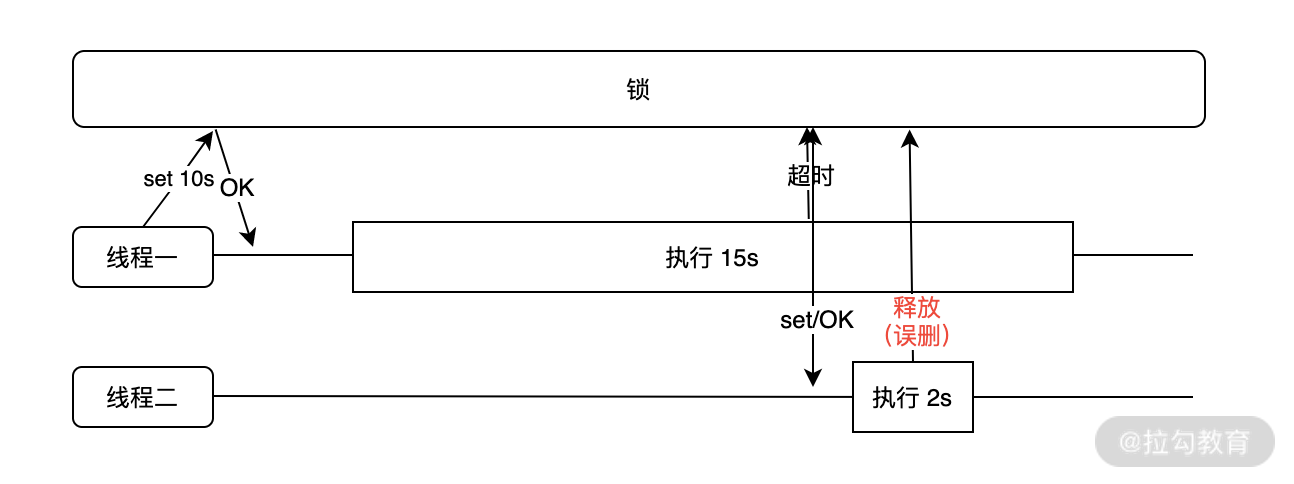
锁被误删的解决方案是在使用 set 命令创建锁时,给 value 值设置一个归属标识。例如,在 value 中插入一个 UUID,每次在删除之前先要判断 UUID 是不是属于当前的线程,如果属于再删除,这样就避免了锁被误删的问题。
注意:在锁的归属判断和删除的过程中,不能先判断锁再删除锁,如下代码所示:
```
if(uuid.equals(uuid)){ // 判断是否是自己的锁
del(luck); // 删除锁
}
```
应该把判断和删除放到一个原子单元中去执行,因此需要借助 Lua 脚本来执行,在 Redis 中执行 Lua 脚本可以保证这批命令的原子性,它的实现代码如下:
```
/**
* 释放分布式锁
* @param jedis Redis客户端
* @param lockKey 锁的 key
* @param flagId 锁归属标识
* @return 是否释放成功
*/
public static boolean unLock(Jedis jedis, String lockKey, String flagId) {
String script = "if redis.call('get', KEYS[1]) == ARGV[1] then return redis.call('del', KEYS[1]) else return 0 end";
Object result = jedis.eval(script, Collections.singletonList(lockKey), Collections.singletonList(flagId));
if ("1L".equals(result)) { // 判断执行结果
return true;
}
return false;
}
```
其中,Collections.singletonList() 方法是将 String 转成 List,因为 jedis.eval() 最后两个参数要求必须是 List 类型。
锁超时可以通过两种方案来解决:
* 把执行耗时的方法从锁中剔除,减少锁中代码的执行时间,保证锁在超时之前,代码一定可以执行完;
* 把锁的超时时间设置的长一些,正常情况下我们在使用完锁之后,会调用删除的方法手动删除锁,因此可以把超时时间设置的稍微长一些。
#### 小结
本课时我们讲了分布式锁的四种实现方式,即 MySQL、Memcached、Redis 和 ZooKeeper,因为 Redis 的普及率比较高,因此对于很多公司来说使用 Redis 实现分布式锁是最优的选择。本课时我们还讲了使用 Redis 实现分布式锁的具体步骤以及实现代码,还讲了在实现过程中可能会遇到的一些问题以及解决方案。
#### 课后问答
* 1、如果业务就是会出现1%的超时呢?怎么处理?
讲师回复: 要看 1% 的业务超出了多少时间,如果超出的不多就增加超时时长,否则就想办法把耗时的业务代码拎出来。
* 2、锁超时那里,感觉图和描述的不是很清楚,线程1的锁因为超时被释放了,线程2获取到锁开始执行,随后因为线程1在线程2前完成了,所以线程1会去删除锁,所以这里产生了线程2的锁被线程1误删的问题,不知道我这样理解的对不
讲师回复: 是这个意思。
* 3、老师,redis集群下是如何实现锁的呢
讲师回复: 实现方法都是一样的
* 4、删除锁时如果判断锁和删除锁两个操作不是原子性的,可能会出现什么问题?
讲师回复: 一个先执行,一个后执行,中间执行过程可能被打断,并且有可能把自己的执行权交由另一个线程执行,就会出现一些非安全性问题。
* 5、假如某个线程获取到锁后,执行时间大于过期时间,是不是执行时间到了才会删除设置的键?还是把超时当成异常,然后直接删除键释放锁?
讲师回复: 过期时间到了也会删除锁,这是 Redis 层面执行的,程序线程执行完了也会删除锁,会有两次删除。正常来说要保证锁的执行时间要尽量的短(不要出现超时的情况),第二,如果超时了要保证线程 A,不能误删线程 B 的锁。
* 6、为什么是删除锁,而不是释放锁?
讲师回复: 其实是一个意思,一个是物理删除一个是逻辑删除,可以这样理解。
* 7、如果占用锁的任务执行超时,任务会怎么处理?
讲师回复: 可能会出现 Redis 已经把过期的锁给删除了,线程 A 执行完之后又把线程 B 的锁给误删了,文章有解决方案哈。
- 前言
- 开篇词
- 开篇词:大厂技术面试“潜规则”
- 模块一:Java 基础
- 第01讲:String 的特点是什么?它有哪些重要的方法?
- 第02讲:HashMap 底层实现原理是什么?JDK8 做了哪些优化?
- 第03讲:线程的状态有哪些?它是如何工作的?
- 第04讲:详解 ThreadPoolExecutor 的参数含义及源码执行流程?
- 第05讲:synchronized 和 ReentrantLock 的实现原理是什么?它们有什么区别?
- 第06讲:谈谈你对锁的理解?如何手动模拟一个死锁?
- 第07讲:深克隆和浅克隆有什么区别?它的实现方式有哪些?
- 第08讲:动态代理是如何实现的?JDK Proxy 和 CGLib 有什么区别?
- 第09讲:如何实现本地缓存和分布式缓存?
- 第10讲:如何手写一个消息队列和延迟消息队列?
- 模块二:热门框架
- 第11讲:底层源码分析 Spring 的核心功能和执行流程?(上)
- 第12讲:底层源码分析 Spring 的核心功能和执行流程?(下)
- 第13讲:MyBatis 使用了哪些设计模式?在源码中是如何体现的?
- 第14讲:SpringBoot 有哪些优点?它和 Spring 有什么区别?
- 第15讲:MQ 有什么作用?你都用过哪些 MQ 中间件?
- 模块三:数据库相关
- 第16讲:MySQL 的运行机制是什么?它有哪些引擎?
- 第17讲:MySQL 的优化方案有哪些?
- 第18讲:关系型数据和文档型数据库有什么区别?
- 第19讲:Redis 的过期策略和内存淘汰机制有什么区别?
- 第20讲:Redis 怎样实现的分布式锁?
- 第21讲:Redis 中如何实现的消息队列?实现的方式有几种?
- 第22讲:Redis 是如何实现高可用的?
- 模块四:Java 进阶
- 第23讲:说一下 JVM 的内存布局和运行原理?
- 第24讲:垃圾回收算法有哪些?
- 第25讲:你用过哪些垃圾回收器?它们有什么区别?
- 第26讲:生产环境如何排除和优化 JVM?
- 第27讲:单例的实现方式有几种?它们有什么优缺点?
- 第28讲:你知道哪些设计模式?分别对应的应用场景有哪些?
- 第29讲:红黑树和平衡二叉树有什么区别?
- 第30讲:你知道哪些算法?讲一下它的内部实现过程?
- 模块五:加分项
- 第31讲:如何保证接口的幂等性?常见的实现方案有哪些?
- 第32讲:TCP 为什么需要三次握手?
- 第33讲:Nginx 的负载均衡模式有哪些?它的实现原理是什么?
- 第34讲:Docker 有什么优点?使用时需要注意什么问题?
- 彩蛋
- 彩蛋:如何提高面试成功率?