
## 15 CopyOnWriteArrayList 源码解析和设计思路
## 引导语
在 ArrayList 的类注释上,JDK 就提醒了我们,如果要把 ArrayList 作为共享变量的话,是线程不安全的,推荐我们自己加锁或者使用 Collections.synchronizedList 方法,其实 JDK 还提供了另外一种线程安全的 List,叫做 CopyOnWriteArrayList,这个 List 具有以下特征:
1. 线程安全的,多线程环境下可以直接使用,无需加锁;
2. 通过锁 + 数组拷贝 + volatile 关键字保证了线程安全;
3. 每次数组操作,都会把数组拷贝一份出来,在新数组上进行操作,操作成功之后再赋值回去。
### 1 整体架构
从整体架构上来说,CopyOnWriteArrayList 数据结构和 ArrayList 是一致的,底层是个数组,只不过 CopyOnWriteArrayList 在对数组进行操作的时候,基本会分四步走:
1. 加锁;
2. 从原数组中拷贝出新数组;
3. 在新数组上进行操作,并把新数组赋值给数组容器;
4. 解锁。
除了加锁之外,CopyOnWriteArrayList 的底层数组还被 volatile 关键字修饰,意思是一旦数组被修改,其它线程立马能够感知到,代码如下:
private transient volatile Object[] array;
整体上来说,CopyOnWriteArrayList 就是利用锁 + 数组拷贝 + volatile 关键字保证了 List 的线程安全。
#### 1.1 类注释
我们看看从 CopyOnWriteArrayList 的类注释上能得到哪些信息:
1. 所有的操作都是线程安全的,因为操作都是在新拷贝数组上进行的;
2. 数组的拷贝虽然有一定的成本,但往往比一般的替代方案效率高;
3. 迭代过程中,不会影响到原来的数组,也不会抛出 ConcurrentModificationException 异常。
接着我们来看下 CopyOnWriteArrayList 的核心方法源码。
### 2 新增
新增有很多种情况,比如说:新增到数组尾部、新增到数组某一个索引位置、批量新增等等,操作的思路还是我们开头说的四步,我们拿新增到数组尾部的方法举例,来看看底层源码的实现:
```
// 添加元素到数组尾部 public boolean add(E e) { final ReentrantLock lock = this.lock; // 加锁 lock.lock(); try { // 得到所有的原数组 Object[] elements = getArray(); int len = elements.length; // 拷贝到新数组里面,新数组的长度是 + 1 的,因为新增会多一个元素 Object[] newElements = Arrays.copyOf(elements, len + 1); // 在新数组中进行赋值,新元素直接放在数组的尾部 newElements[len] = e; // 替换掉原来的数组 setArray(newElements); return true; // finally 里面释放锁,保证即使 try 发生了异常,仍然能够释放锁 } finally { lock.unlock(); } }
```
从源码中,我们发现整个 add 过程都是在持有锁的状态下进行的,通过加锁,来保证同一时刻只能有一个线程能够对同一个数组进行 add 操作。
除了加锁之外,还会从老数组中创建出一个新数组,然后把老数组的值拷贝到新数组上,这时候就有一个问题:都已经加锁了,为什么需要拷贝数组,而不是在原来数组上面进行操作呢,原因主要为:
1. volatile 关键字修饰的是数组,如果我们简单的在原来数组上修改其中某几个元素的值,是无法触发可见性的,我们必须通过修改数组的内存地址才行,也就说要对数组进行重新赋值才行。
2. 在新的数组上进行拷贝,对老数组没有任何影响,只有新数组完全拷贝完成之后,外部才能访问到,降低了在赋值过程中,老数组数据变动的影响。
简单 add 操作是直接添加到数组的尾部,接着我们来看下指定位置添加元素的关键源码(部分源码):
```
// len:数组的长度、index:插入的位置 int numMoved = len - index; // 如果要插入的位置正好等于数组的末尾,直接拷贝数组即可 if (numMoved == 0) newElements = Arrays.copyOf(elements, len + 1); else { // 如果要插入的位置在数组的中间,就需要拷贝 2 次 // 第一次从 0 拷贝到 index。 // 第二次从 index+1 拷贝到末尾。 newElements = new Object[len + 1]; System.arraycopy(elements, 0, newElements, 0, index); System.arraycopy(elements, index, newElements, index + 1, numMoved); } // index 索引位置的值是空的,直接赋值即可。 newElements[index] = element; // 把新数组的值赋值给数组的容器中 setArray(newElements);
```
从源码中可以看到,当插入的位置正好处于末尾时,只需要拷贝一次,当插入的位置处于中间时,此时我们会把原数组一分为二,进行两次拷贝操作。
最后还有个批量新增操作,源码我们就不贴了,底层也是拷贝数组的操作。
#### 2.1 小结
从 add 系列方法可以看出,CopyOnWriteArrayList 通过加锁 + 数组拷贝+ volatile 来保证了线程安全,每一个要素都有着其独特的含义:
1. 加锁:保证同一时刻数组只能被一个线程操作;
2. 数组拷贝:保证数组的内存地址被修改,修改后触发 volatile 的可见性,其它线程可以立马知道数组已经被修改;
3. volatile:值被修改后,其它线程能够立马感知最新值。
三个要素缺一不可,比如说我们只使用 1 和 3 ,去掉 2,这样当我们修改数组中某个值时,并不会触发 volatile 的可见特性的,只有当数组内存地址被修改后,才能触发把最新值通知给其他线程的特性。
### 3 删除
接着我们来看下指定数组索引位置删除的源码:
```
// 删除某个索引位置的数据 public E remove(int index) { final ReentrantLock lock = this.lock; // 加锁 lock.lock(); try { Object[] elements = getArray(); int len = elements.length; // 先得到老值 E oldValue = get(elements, index); int numMoved = len - index - 1;
// 如果要删除的数据正好是数组的尾部,直接删除 if (numMoved == 0) setArray(Arrays.copyOf(elements, len - 1)); else { // 如果删除的数据在数组的中间,分三步走 // 1. 设置新数组的长度减一,因为是减少一个元素 // 2. 从 0 拷贝到数组新位置 // 3. 从新位置拷贝到数组尾部 Object[] newElements = new Object[len - 1]; System.arraycopy(elements, 0, newElements, 0, index); System.arraycopy(elements, index + 1, newElements, index, numMoved); setArray(newElements); } return oldValue; } finally { lock.unlock(); } }
```
步骤分为三步:
1. 加锁;
2. 判断删除索引的位置,从而进行不同策略的拷贝;
3. 解锁。
代码整体的结构风格也比较统一:锁 + try finally +数组拷贝,锁被 final 修饰的,保证了在加锁过程中,锁的内存地址肯定不会被修改,finally 保证锁一定能够被释放,数组拷贝是为了删除其中某个位置的元素。
### 4 批量删除
数组的批量删除很有意思,接下来我们来看下 CopyOnWriteArrayList 的批量删除的实现过程:
```
// 批量删除包含在 c 中的元素 public boolean removeAll(Collection<?> c) { if (c == null) throw new NullPointerException(); final ReentrantLock lock = this.lock; lock.lock(); try { Object[] elements = getArray(); int len = elements.length; // 说明数组有值,数组无值直接返回 false if (len != 0) { // newlen 表示新数组的索引位置,新数组中存在不包含在 c 中的元素 int newlen = 0; Object[] temp = new Object[len]; // 循环,把不包含在 c 里面的元素,放到新数组中 for (int i = 0; i < len; ++i) { Object element = elements[i]; // 不包含在 c 中的元素,从 0 开始放到新数组中 if (!c.contains(element)) temp[newlen++] = element; } // 拷贝新数组,变相的删除了不包含在 c 中的元素 if (newlen != len) { setArray(Arrays.copyOf(temp, newlen)); return true; } } return false; } finally { lock.unlock();
} }
```
从源码中,我们可以看到,我们并不会直接对数组中的元素进行挨个删除,而是先对数组中的值进行循环判断,把我们不需要删除的数据放到临时数组中,最后临时数组中的数据就是我们不需要删除的数据。
不知道大家有木有似曾相识的感觉,ArrayList 的批量删除的思想也是和这个类似的,所以我们在需要删除多个元素的时候,最好都使用这种批量删除的思想,而不是采用在 for 循环中使用单个删除的方法,单个删除的话,在每次删除的时候都会进行一次数组拷贝(删除最后一个元素时不会拷贝),很消耗性能,也耗时,会导致加锁时间太长,并发大的情况下,会造成大量请求在等待锁,这也会占用一定的内存。
### 5 其它方法
#### 5.1 indexOf
indexOf 方法的主要用处是查找元素在数组中的下标位置,如果元素存在就返回元素的下标位置,元素不存在的话返回 -1,不但支持 null 值的搜索,还支持正向和反向的查找,我们以正向查找为例,通过源码来说明一下其底层的实现方式:
```
// o:我们需要搜索的元素 // elements:我们搜索的目标数组 // index:搜索的开始位置 // fence:搜索的结束位置 private static int indexOf(Object o, Object[] elements, int index, int fence) { // 支持对 null 的搜索 if (o == null) { for (int i = index; i < fence; i++)
// 找到第一个 null 值,返回下标索引的位置 if (elements[i] == null) return i; } else { // 通过 equals 方法来判断元素是否相等 // 如果相等,返回元素的下标位置 for (int i = index; i < fence; i++) if (o.equals(elements[i])) return i; } return -1; }
```
indexOf 方法在 CopyOnWriteArrayList 内部使用也比较广泛,比如在判断元素是否存在时(contains),在删除元素方法中校验元素是否存在时,都会使用到 indexOf 方法,indexOf 方法通过一次 for 循环来查找元素,我们在调用此方法时,需要注意如果找不到元素时,返回的是 -1,所以有可能我们会对这个特殊值进行判断。
#### 5.2 迭代
在 CopyOnWriteArrayList 类注释中,明确说明了,在其迭代过程中,即使数组的原值被改变,也不会抛出 ConcurrentModificationException 异常,其根源在于数组的每次变动,都会生成新的数组,不会影响老数组,这样的话,迭代过程中,根本就不会发生迭代数组的变动,我们截几个图说明一下:
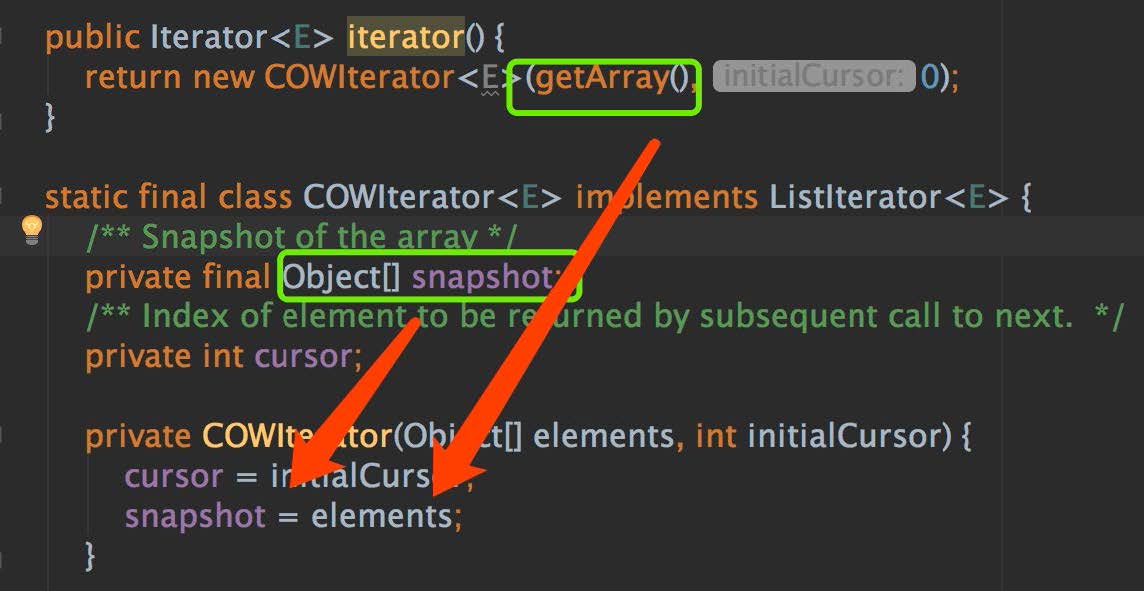
1. 迭代是直接持有原有数组的引用,也就是说迭代过程中,一旦原有数组的值内存地址发生变化,必然会影响到迭代过程,下图源码演示的是 CopyOnWriteArrayList 的迭代方法,我们
可以看到迭代器是直接持有原数组的引用:
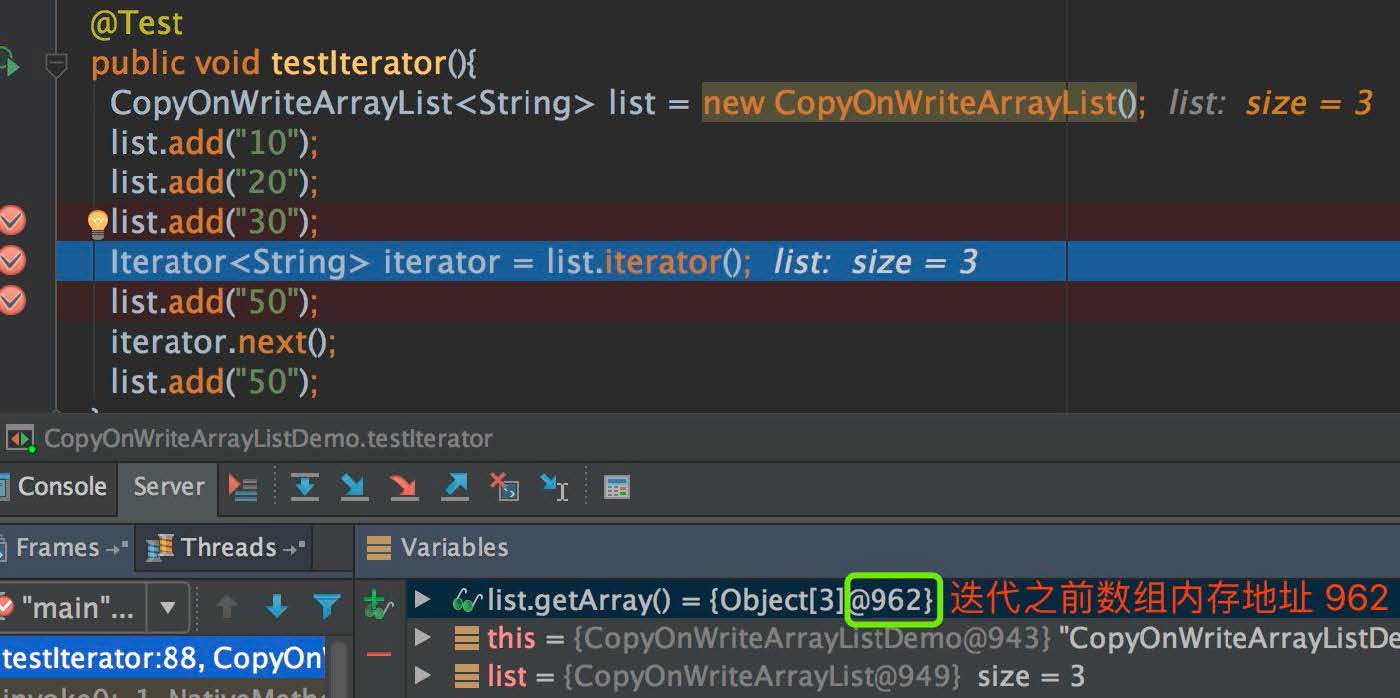
2. 我们写了一个 demo,在 CopyOnWriteArrayList 迭代之后,往 CopyOnWriteArrayList 里面新增值,从下图中可以看到在 CopyOnWriteArrayList 迭代之前,数组的内存地址是 962,请记住这个数字:
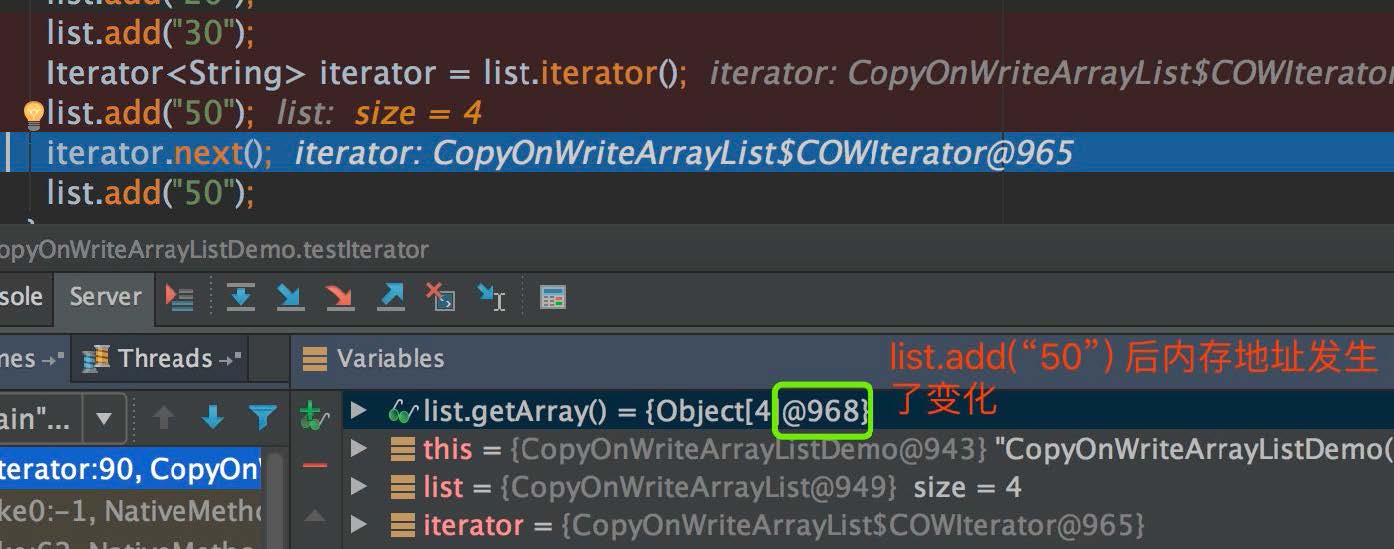
3. CopyOnWriteArrayList 迭代之后,我们使用 add(“50”) 代码给数组新增一个数据后,数组内存地址发生了变化,内存地址从原来的 962 变成了 968,这是因为 CopyOnWriteArrayList
的 add 操作,会生成新的数组,所以数组的内存地址发生了变化:
4. 迭代继续进行时,我们发现迭代器中的地址仍然是迭代之前引用的地址,是 962,而不是新的数组的内存地址:
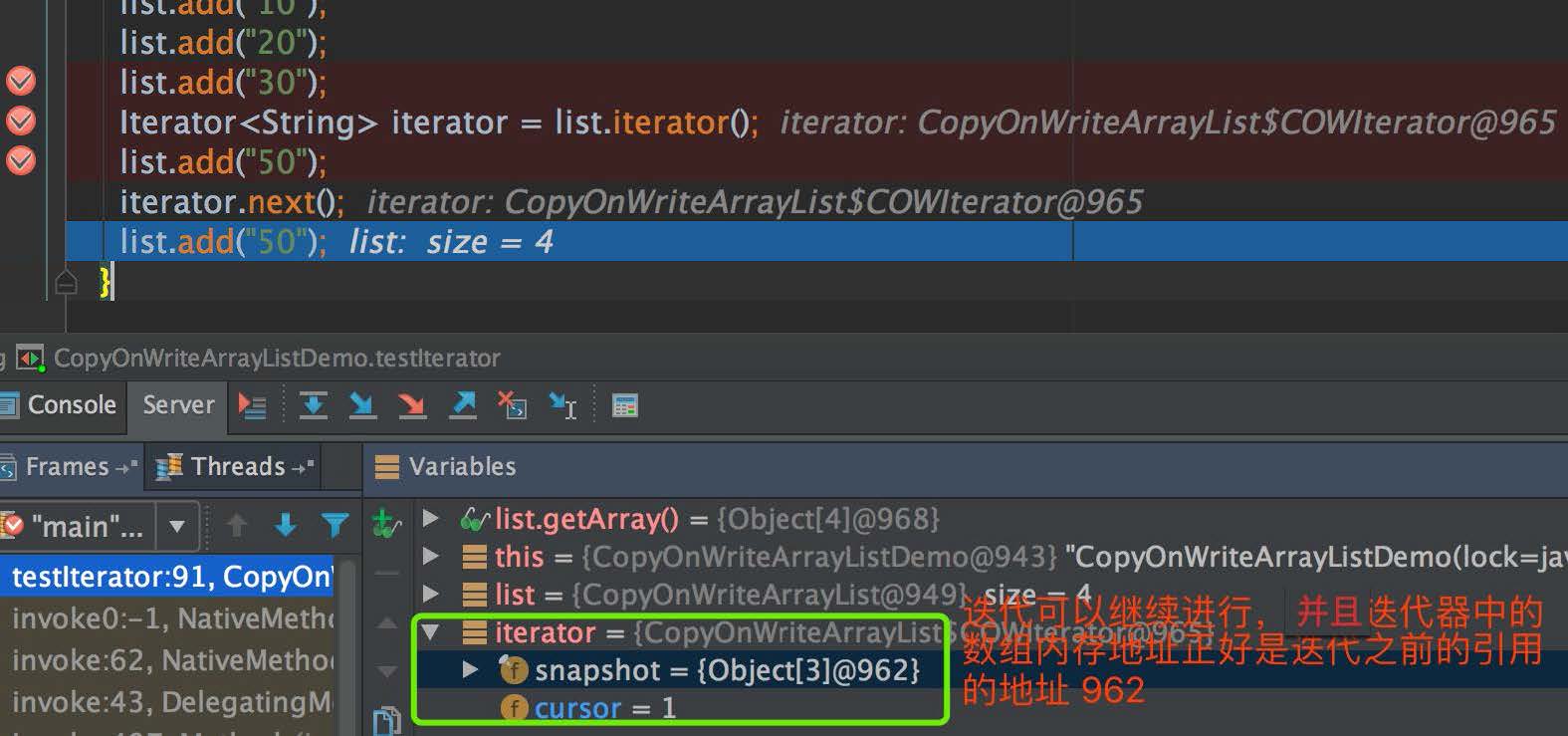
从上面 4 张截图,我们可以得到迭代过程中,即使 CopyOnWriteArrayList 的结构发生变动了,也不会抛出 ConcurrentModificationException 异常的原因:CopyOnWriteArrayList 迭代持有的是老数组的引用,而 CopyOnWriteArrayList 每次的数据变动,都会产生新的数组,对老数组的值不会产生影响,所以迭代也可以正常进行。
### 6 总结
当我们需要在线程不安全场景下使用 List 时,建议使用 CopyOnWriteArrayList,CopyOnWriteArrayList 通过锁 + 数组拷贝 + volatile 之间的相互配合,实现了 List 的线程安全,我们抛弃 Java 的这种实现,如果让我们自己实现,你又将如何实现呢?
- 前言
- 第1章 基础
- 01 开篇词:为什么学习本专栏
- 02 String、Long 源码解析和面试题
- 03 Java 常用关键字理解
- 04 Arrays、Collections、Objects 常用方法源码解析
- 第2章 集合
- 05 ArrayList 源码解析和设计思路
- 06 LinkedList 源码解析
- 07 List 源码会问哪些面试题
- 08 HashMap 源码解析
- 09 TreeMap 和 LinkedHashMap 核心源码解析
- 10 Map源码会问哪些面试题
- 11 HashSet、TreeSet 源码解析
- 12 彰显细节:看集合源码对我们实际工作的帮助和应用
- 13 差异对比:集合在 Java 7 和 8 有何不同和改进
- 14 简化工作:Guava Lists Maps 实际工作运用和源码
- 第3章 并发集合类
- 15 CopyOnWriteArrayList 源码解析和设计思路
- 16 ConcurrentHashMap 源码解析和设计思路
- 17 并发 List、Map源码面试题
- 18 场景集合:并发 List、Map的应用场景
- 第4章 队列
- 19 LinkedBlockingQueue 源码解析
- 20 SynchronousQueue 源码解析
- 21 DelayQueue 源码解析
- 22 ArrayBlockingQueue 源码解析
- 23 队列在源码方面的面试题
- 24 举一反三:队列在 Java 其它源码中的应用
- 25 整体设计:队列设计思想、工作中使用场景
- 26 惊叹面试官:由浅入深手写队列
- 第5章 线程
- 27 Thread 源码解析
- 28 Future、ExecutorService 源码解析
- 29 押宝线程源码面试题
- 第6章 锁
- 30 AbstractQueuedSynchronizer 源码解析(上)
- 31 AbstractQueuedSynchronizer 源码解析(下)
- 32 ReentrantLock 源码解析
- 33 CountDownLatch、Atomic 等其它源码解析
- 34 只求问倒:连环相扣系列锁面试题
- 35 经验总结:各种锁在工作中使用场景和细节
- 36 从容不迫:重写锁的设计结构和细节
- 第7章 线程池
- 37 ThreadPoolExecutor 源码解析
- 38 线程池源码面试题
- 39 经验总结:不同场景,如何使用线程池
- 40 打动面试官:线程池流程编排中的运用实战
- 第8章 Lambda 流
- 41 突破难点:如何看 Lambda 源码
- 42 常用的 Lambda 表达式使用场景解析和应用
- 第9章 其他
- 43 ThreadLocal 源码解析
- 44 场景实战:ThreadLocal 在上下文传值场景下的实践
- 45 Socket 源码及面试题
- 46 ServerSocket 源码及面试题
- 47 工作实战:Socket 结合线程池的使用
- 第10章 专栏总结
- 48 一起看过的 Java 源码和面试真题