
# 8 可视化分布:经验累积分布函数和 q-q 图
> 原文: [8 Visualizing distributions: Empirical cumulative distribution functions and q-q plots](https://serialmentor.com/dataviz/ecdf-qq.html)
> 校验:[飞龙](https://github.com/wizardforcel)
> 自豪地采用[谷歌翻译](https://translate.google.cn/)
在第七章中,我描述了如何使用直方图或密度图来可视化分布。这两种方法都非常直观且具有视觉吸引力。然而,正如该章中所讨论的,它们有共同的限制,即所得图形在很大程度上取决于用户必须选择的参数,例如直方图的箱宽和密度图的带宽。因此,两者都必须被视为对数据的解释,而不是数据本身的直接可视化。
作为使用直方图或密度图的替代方法,我们可以简单地将所有数据点单独显示为点云。但是,对于非常大的数据集,这种方法变得难以处理,并且在任何情况下,聚合方法中有一些值,突出显示分布的属性而不是单个数据点。为了解决这个问题,统计学家发明了经验累积分布函数(ecdfs)和分位数-分位数(q-q)图。这些类型的可视化不需要任意参数的选择,它们一次显示所有数据。不幸的是,它们比直方图或密度图更不直观,我不认为它们在高科技出版物之外经常使用。不过,他们在统计学家中很受欢迎,我认为任何对数据可视化感兴趣的人都应该熟悉这些技术。
## 8.1 经验累积分布函数
为了说明累积的经验分布函数,我将从一个假设的例子开始,该例子使用我在教室里作为教授大量处理的东西来建模:学生成绩的数据集。假设我们的班有 50 名学生,学生们刚刚完成了考试,他们的得分在 0 到 100 分之间。我们如何才能最好地可视化课堂表现,例如来确定适当的成绩界限?
我们可以绘制得分不超过某个值的学生总数与所有可能的得分。该图将是一个升序函数,从 0 分和 0 人开始,到 100 分和 50 人结束。关于这种可视化的另一种思考方式如下:我们可以按所获得的分数按升序对所有学生进行排名(使得分最低的学生排名最低,得分最高的学生排名最高) ,然后绘制排名与获得的实际得分。结果是经验累积分布函数(ecdf)或简单称为累积分布。每个点代表一个学生,并且线条展示了对于任何的可能得分,观察到的学生的最高排名(图 8.1)。
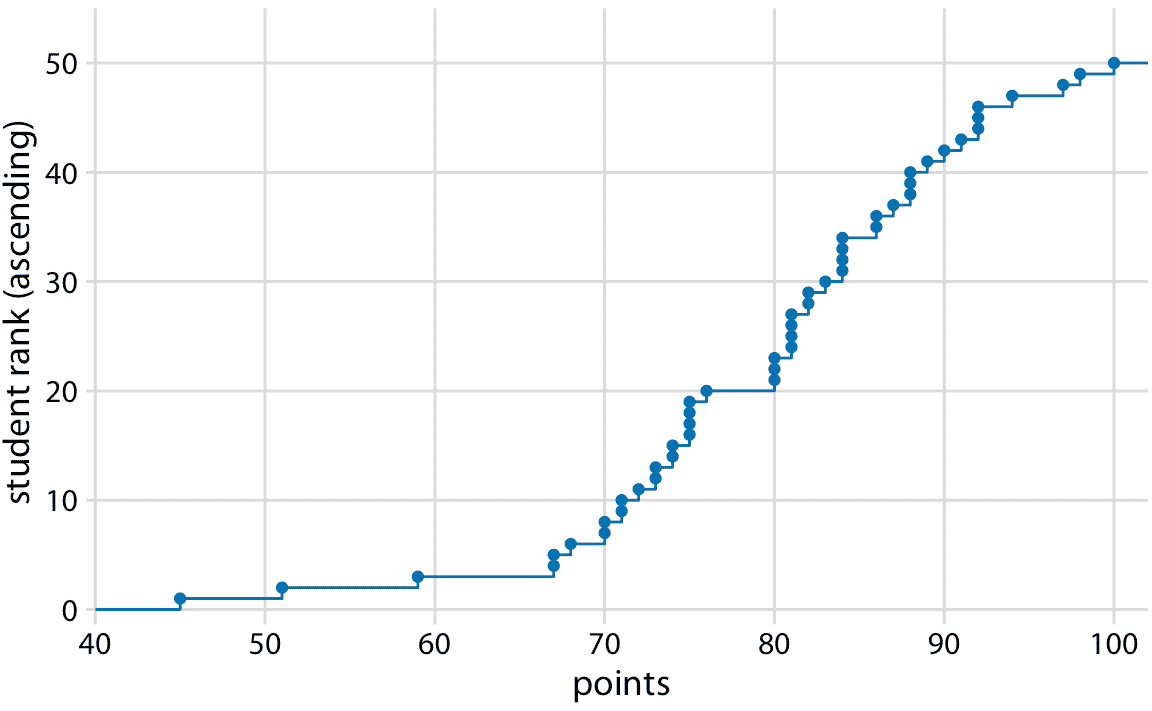
图 8.1:假设的 50 名学生的学生成绩的经验累积分布函数。
你可能想知道如果我们按照相反的顺序对学生进行排序,会发生什么。这个排名简单地翻转了它的函数。结果仍然是经验累积分布函数,但现在这些线表示对于任何可能的得分,观察到的最低学生排名(图 8.2)。
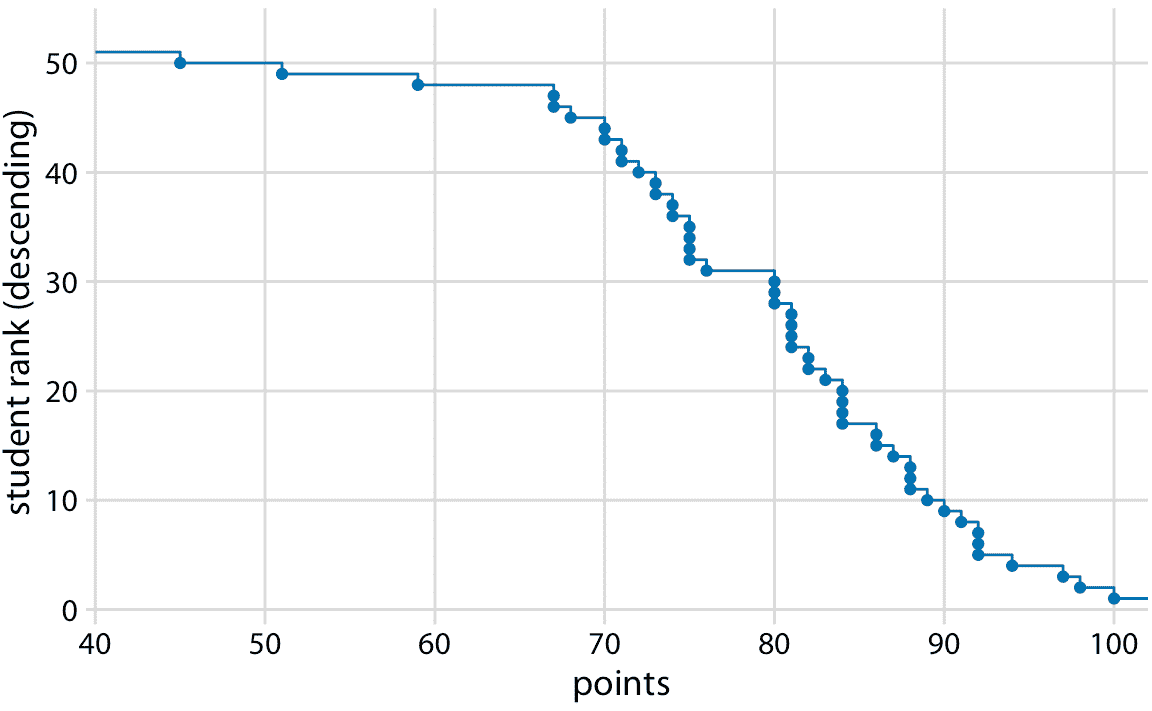
图 8.2:作为降序 ecdf 绘制的学生成绩分布。
升序累积分布函数比降序函数更广为人知,更常用,但两者都有重要的应用。当我们想要显示高度偏斜的分布时,降序累积分布函数是至关重要的(参见章节 8.2 )。
在实际应用中,绘制 ecdf 而不突出显示各个点,并通过最大排名对排名进行归一化是很常见的,因此 *y* 轴代表累积频率(图 8.3)。
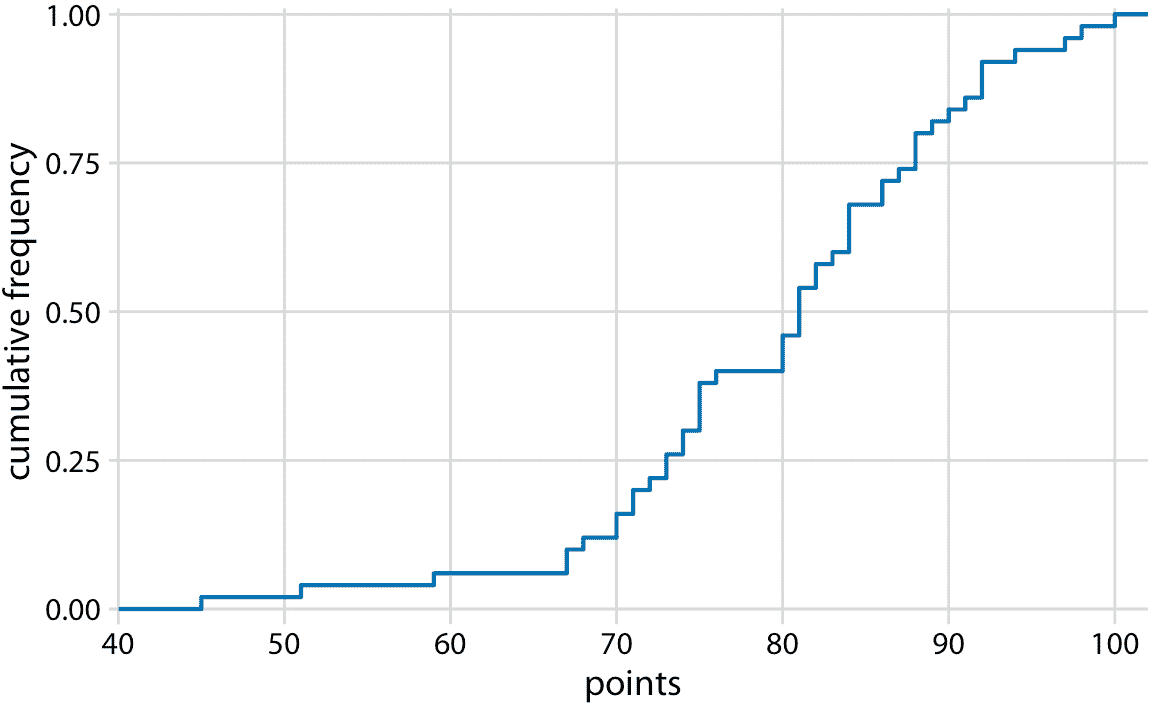
图 8.3:学生成绩的 Ecdf。学生排名已经按照学生总数标准化,因此绘制的 *y* 值对应于班级中得分不超过一定值的学生的比例。
我们可以直接从该图中读取学生成绩分布的关键属性。例如,大约四分之一的学生(25%)得到不到 75 分。中点值(对应于 0.5 的累积频率)是 81。大约 20% 的学生得到 90 分或更多。
我发现 ecdfs 可以方便地分配成绩边界,因为它们可以帮助我找到最小化学生不快乐的准确截断点。例如,在这个例子中,在 80 分以下有一条相当长的水平线,接着是 80 分的急剧上升。这个特征的成因是三名学生在考试中获得 80 分,而另一名表现较差的学生只获得 76 分。在这种情况下,我可能会认为得分为 80 或者以上的每个人都会得到一个 B,而且每个 79 或者更少的人都会得到 C。这三个 80 分的学生很高兴他们刚得到了一个 B,而那个 76 分的学生意识到他必须表现得更好才能不得到 C。如果我把截断值设定为 77,那么字母等级的分布就完全一样了,但我可能会发现,76 分的学生来我办公室,希望协商他们的成绩。同样,如果我将截断值设置为 81,在我的办公室里可能会有三名学生试图协商他们的成绩。
## 8.2 高度偏斜的分布
许多经验数据集具有高度偏斜的分布,特别是右边的重尾,这些分布可能具有挑战性。此类分布的示例包括居住在不同城市或县的人数,社交网络中的联系人数,单个单词出现在书中的频率,不同作者撰写的学术论文数量,个体净值,以及蛋白质相互作用网络中单个蛋白质的相互作用伙伴的数量(Clauset,Shalizi 和 Newman,2009)。所有这些分布的共同点是它们的右尾衰减比指数函数慢。实际上,这意味着非常大的值并不罕见,即使分布的平均值很小。一类重要的此类分布是幂律分布,其中观测值 *x* 大于某些参考点的值的可能性降为 *x* 的幂。举一个具体的例子,考虑美国的净值,它是幂为 2 的指数分布。在任何给定的净值水平(比如 100 万美元),净值为一半的人是四倍,净值为两倍的人是四分之一。重要的是,如果我们使用 10,000 美元作为参考点或者我们使用 1 亿美元,那么同样的关系也成立。因此,幂律分布也称为无刻度分布。
根据 2010 年美国人口普查,我将首先讨论生活在美国各州的人数。这种分布在右边有一个很长的尾巴。尽管大多数县的居民人数相对较少(中位数为 25,857),但仍有少数县拥有极大数量的居民(例如洛杉矶县,居民人数为 9,818,605)。如果我们试图将人口分布可视化为密度图或 ecdf,我们获得的数据基本上是无用的(图 8.4)。
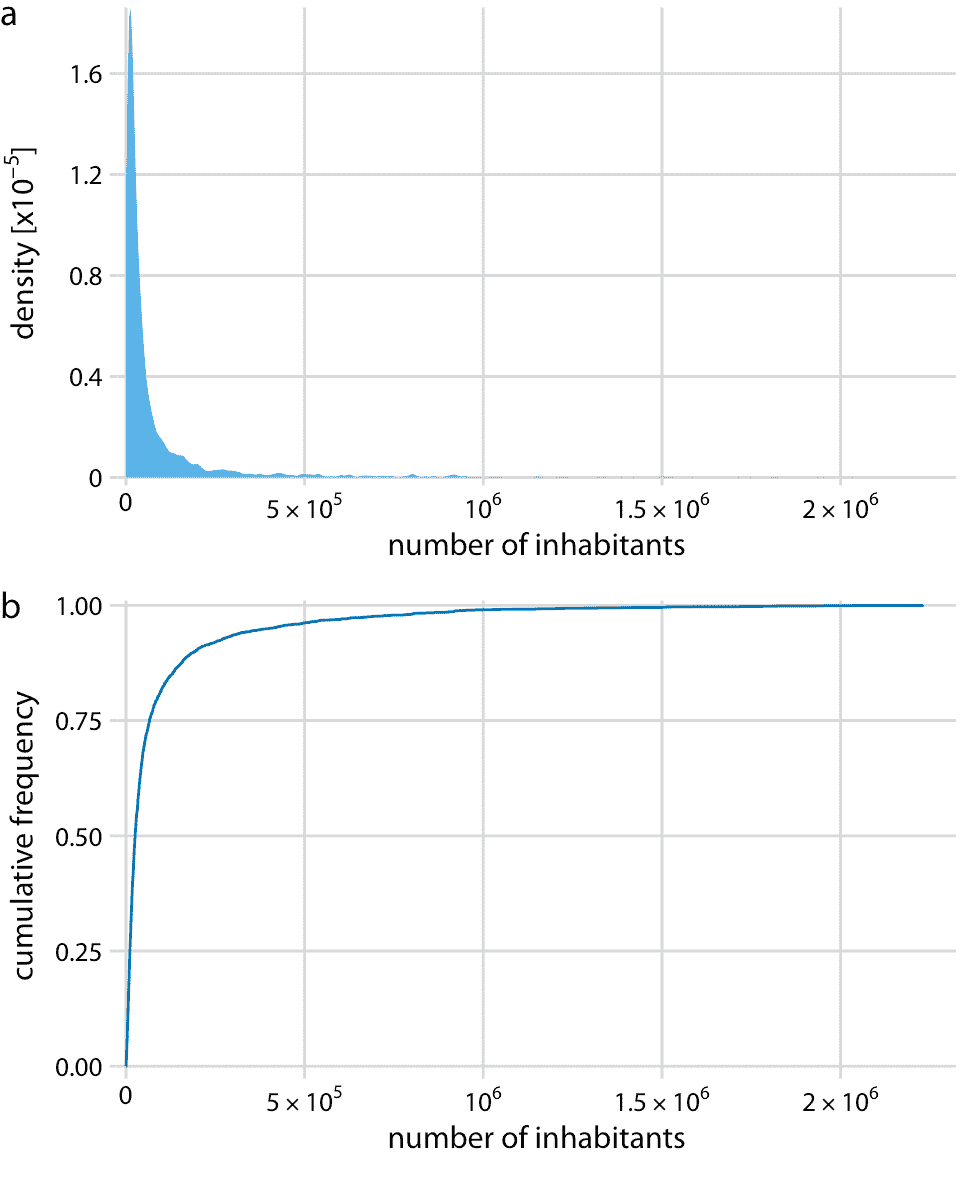
图 8.4:根据 2010 年美国人口普查,美国各县的居民人数分布。(a)密度图。 (b)经验累积分布函数。
密度图(图 8.4a)在 0 处有一个尖峰,几乎没有可见的分布细节。类似地,ecdf(图 8.4b)在 0 附近快速上升,并且同样没有可见的分布细节。对于此特定数据集,我们可以对数据进行对数转换并可视化对数转换值的分布。这种转换在这里起作用,因为县里的人口数量实际上并不是幂律,而是遵循近乎完美的对数正态分布(参见 8.3 部分)。实际上,对数变换值的密度图显示出良好的钟形曲线,相应的 ecdf 显示出良好的 S 形形状(图 8.5)。
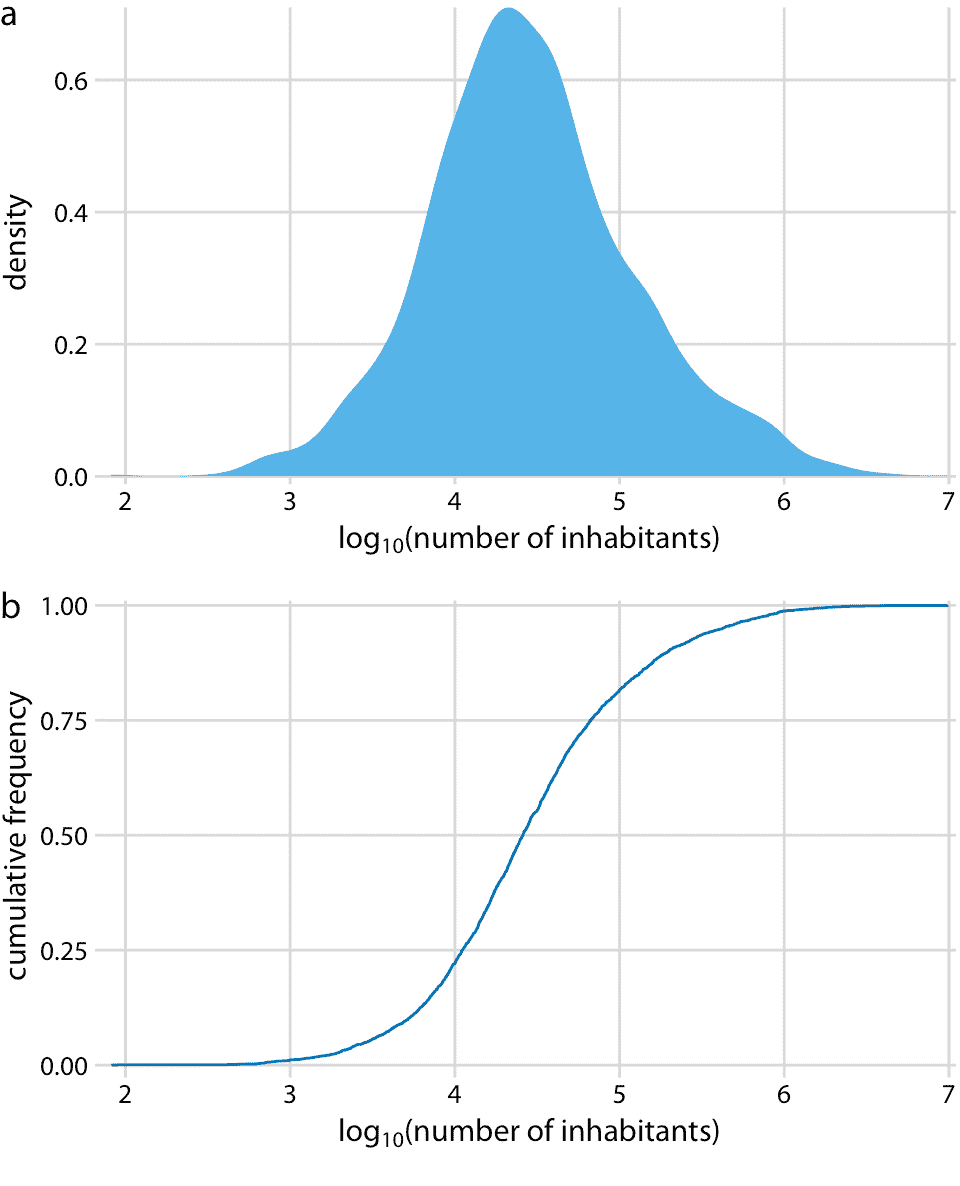
图 8.5:美国各县居民人数的对数分布。(a)密度图。(b)经验累积分布函数。
为了查看这个分布不是幂律,我们将其绘制为具有对数 *x* 和 *y* 轴的降序 ecdf。在此可视化中,幂律显示为完美的直线。对于县里的人口数量,右尾在降序双对数 ecdf 图上几乎是一条直线,但不是很像(图 8.6)。
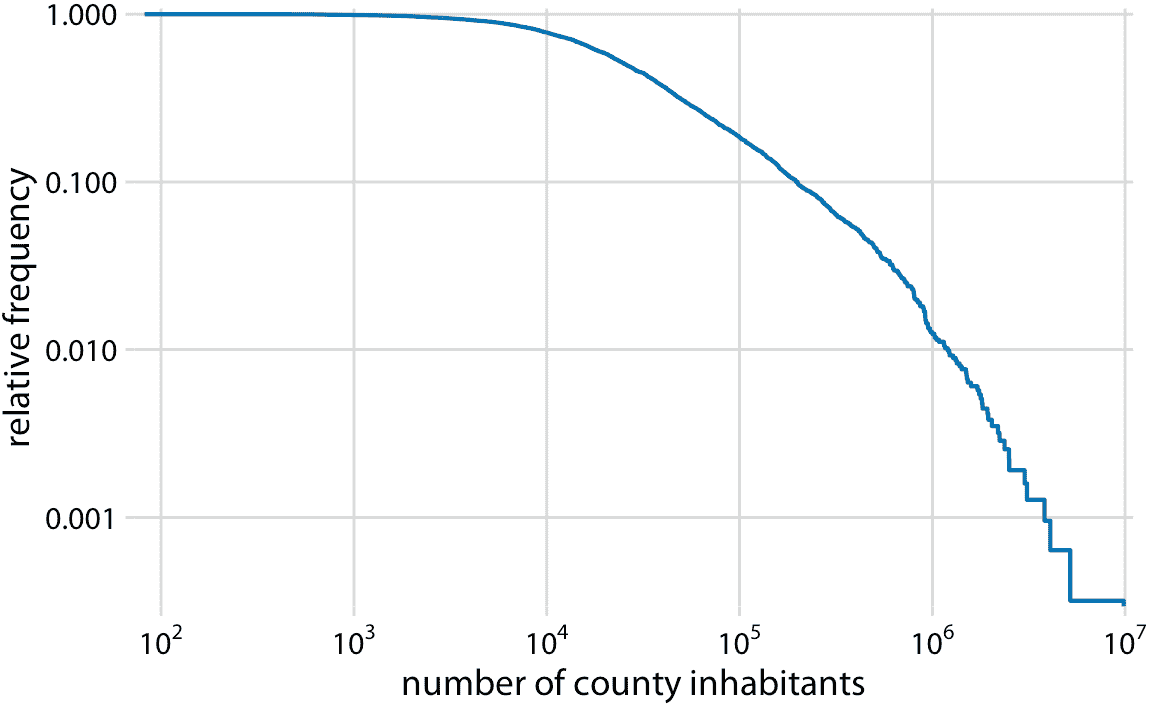
图 8.6:至少有一定居民的县的相对频率,与县居民的数量。
作为第二个例子,我将使用出现在小说“白鲸记”中的所有单词的词频分布。这种分布遵循完美的幂律。当使用对数轴绘制为降序 ecdf 时,我们看到几乎完美的直线(图 8.7 )。
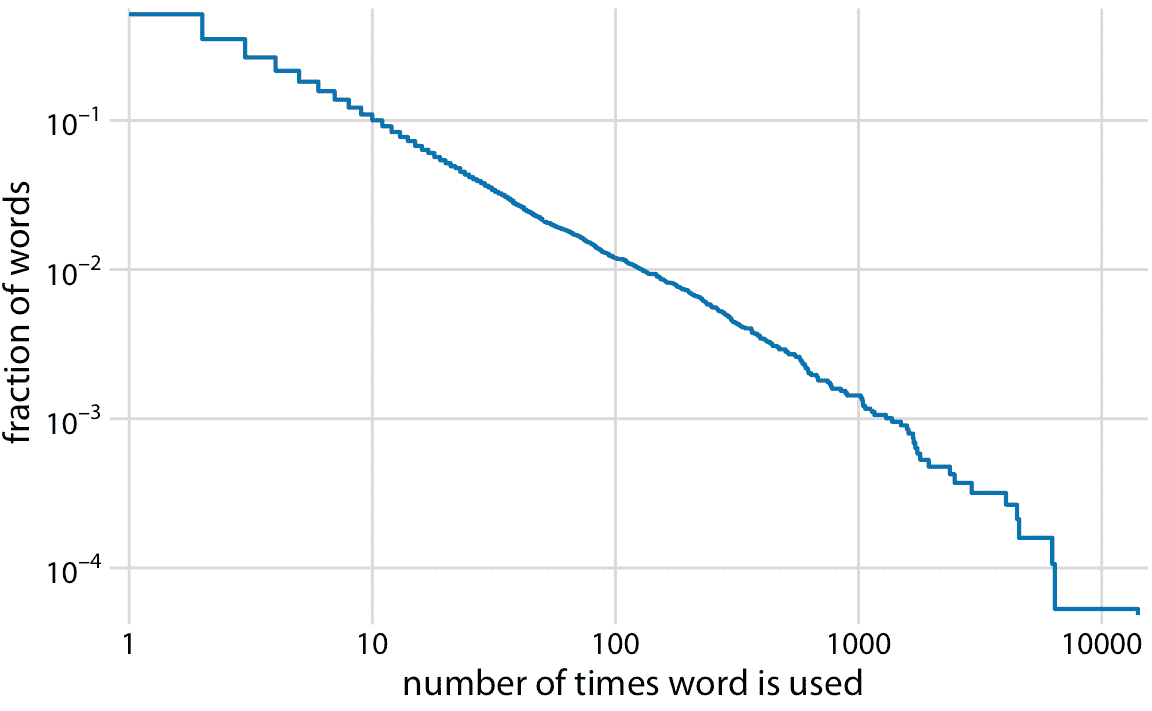
图 8.7:小说“白鲸记”中词数的分布。显示的是在小说中至少出现一定次数的单词的相对频率与使用单词的次数。
## 8.3 分位数-分位数图
当我们想要确定观察到的数据点在何种程度上遵循给定分布时,分位数-分位数(q-q)图是有用的可视化。就像 ecdfs 一样,q-q 图也基于对数据进行排名,并可视化排名和实际值之间的关系。但是,在 q-q 图中,我们不直接绘制排名,如果数据是根据指定的参考分布而分布的,我们使用它们来预测给定数据点应该落在哪里。最常见的是,使用正态分布作为参考构建 q-q 图。举一个具体的例子,假设实际数据值的平均值为 10,标准差为 3。然后,假设正态分布,我们预计排在百分位数 50 的数据点值为 10(平均值) ,百分位 84 的数据点值为 13(高于平均值一个标准差),百分位 2.3 的数据点值为 4(平均值以下两个标准差)。我们可以对数据集中的所有点执行该计算,然后绘制观测值(即,数据集中的值)与理论值(即,给定每个数据点的排名和假定的参考分布的预期值)。
当我们从本章开头对学生成绩分布执行此过程时,我们得到图 8.8 。
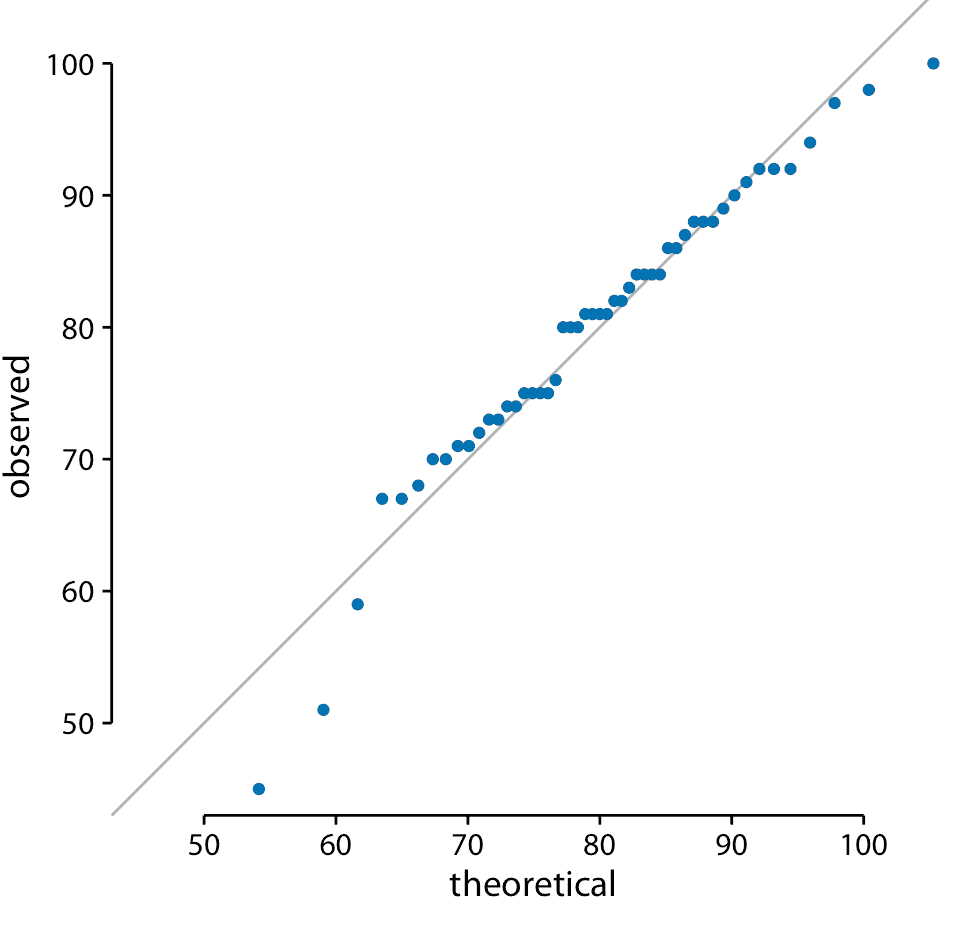
图 8.8:学生成绩的 q-q 图。
这里的实线不是回归线,而是表示 *x* 等于 *y* 的点,即观察值等于理论值的点。如果点落在该线上,则数据遵循假设分布(此处为正态)。我们发现学生的成绩主要是正态分布,在底部和顶部有一些偏差(少数学生的表现比预期更差)。分布的顶部偏差是由假设检验中的最大点值 100 引起的;无论最好的学生有多好,他或她最多可以获得 100 分。
我们还可以使用 q-q 图来测试我在本章前面的断言,即美国各县的人口数量遵循对数正态分布。如果这些计数是对数正态分布的,那么它们的对数变换值是正态分布的,因此应该直接落在 *x* = *y* 线上。在制作这个图时,我们看到观测值与理论值之间的一致性是异常的(图 8.9)。这表明县之间人口数量的分布确实是对数正态的。
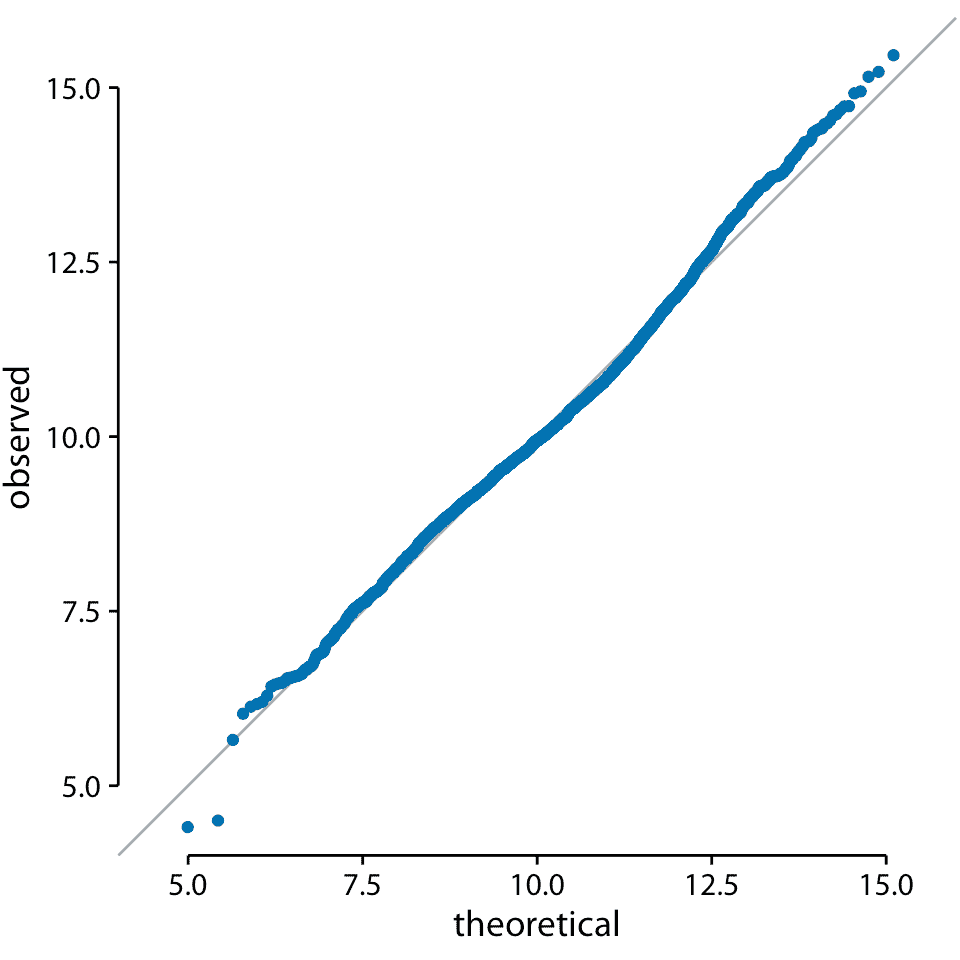
图 8.9:美国各县居民人数对数的 q-q 图。
### 参考
```
Clauset, A., C. R. Shalizi, and M. E. J. Newman. 2009. “Power-Law Distributions in Empirical Data.” SIAM Review 51: 661–703.
```
- 数据可视化的基础知识
- 欢迎
- 前言
- 1 简介
- 2 可视化数据:将数据映射到美学上
- 3 坐标系和轴
- 4 颜色刻度
- 5 可视化的目录
- 6 可视化数量
- 7 可视化分布:直方图和密度图
- 8 可视化分布:经验累积分布函数和 q-q 图
- 9 一次可视化多个分布
- 10 可视化比例
- 11 可视化嵌套比例
- 12 可视化两个或多个定量变量之间的关联
- 13 可视化自变量的时间序列和其他函数
- 14 可视化趋势
- 15 可视化地理空间数据
- 16 可视化不确定性
- 17 比例墨水原理
- 18 处理重叠点
- 19 颜色使用的常见缺陷
- 20 冗余编码
- 21 多面板图形
- 22 标题,说明和表格
- 23 平衡数据和上下文
- 24 使用较大的轴标签
- 25 避免线条图
- 26 不要走向 3D
- 27 了解最常用的图像文件格式
- 28 选择合适的可视化软件
- 29 讲述一个故事并提出一个观点
- 30 带注解的参考书目
- 技术注解
- 参考