>[success] # 代码分层
* **软件分层架构是通过层来隔离不同的关注点**(变化相似的地方),以此来解决不同需求变化的问题,使得这种变化可以被控制在一个层里
* **代码分层架构就是将软件“元素”(代码)按照“层”(代码关系)的方式组织起来的一种结构**
* 分层架构核心的原则是:**当请求或数据从外部传递过来后,必须是从上一层传递给下一层**

*****
不采用分层,直接通信**会造成新的代码耦合,增加代码的复杂**,**分层的本质就是为了让相似变化在各自的层内变化,而不造成层与层之间的相互影响**
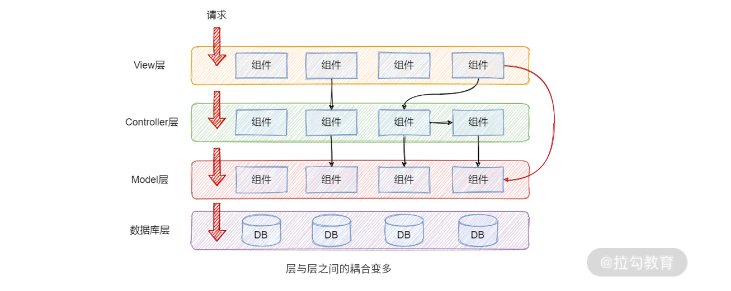
>[danger] ##### 使用分层解决
* **通过分层来拆解问题**,文章中的例子,在做Http 向服务端发送字符串这个过程中,需要`创建连接`、`发送字符串`、`关闭连接`,三个过程面向过程编写这三种情况中每一层都会有属于自己的一些所在层的问题,将每一层的问题拆解,分析去简化。**代码分层本身就是一种拆解复杂问题的好方法**
* **通过分层来提升代码可扩展性**,可以将复杂的逻辑切分为多个层,这样大问题就变成了多个小问题,**组件自身的复用性也就提高了**
* **容易做服务的横向扩展**
总结:**实现责任分离、解耦、组件复用和标准制定**,缺点,**开发成本变高**:因为不同层分别承担各自的责任,**性能降低**:请求数据因为经过多层代码的处理,* **代码复杂度增加**:因为层与层之间存在强耦合,所以对于一些组合功能的调用,则需要增加很多层之间的调用。
>[danger] ##### 分层的设计
认知规则:其上,面向用户的体验与交互;其中,面向应用与业务逻辑;其下,面对各种外部资源与设备。在进行分层架构设计时,我们完全可以基于这个经典的三层架构,沿着水平方向进一步切分属于不同抽象层次的关注点。因此,分层的第一个依据是基于关注点为不同的调用目的划分层次
>[danger] ##### 文章引用
[一篇文章读懂分层架构](https://zhuanlan.zhihu.com/p/40353581)
[趣学设计模式](https://kaiwu.lagou.com/course/courseInfo.htm?courseId=710#/detail/pc?id=6864)
>[success] # 代码的工程思维
**软件开发过程 = 定义与分析 + 设计 + 实现 + 测试 + 交付 + 维护**,不能**在软件开发时,我们总是容易太过于关注局部,而没能跳出局部去看整体**。**软件开发 ≠ 软件编码**
* **有效沟通**现在有一个问题需要解决,问题现象是 xxx,业务方的预期是 xxx,实际看到的是 xxx,不符合预期,从日志和报错看可能是 xxx 出问题了。由于 xxx 项目上线时间紧迫,急需解决,在线等
>[danger] ##### 文章引用
[趣学设计模式](https://kaiwu.lagou.com/course/courseInfo.htm?courseId=710#/detail/pc?id=6864)
>[success] # 评判代码好坏标准
评价代码质量的好坏通常有三个维度:**可读性、可测试性以及可维护性**,可读性是最重要的,只有你写的代码可读性高,别人才更愿意维护你的代码;如果可读性低,大多数人的做法要么是重构,要么是重写。而重构则意味着要承担维护这部分代码的责任,如果不是迫不得已,一般没人愿意承担未知的风险,所以实际上对于难以阅读的代码,绝大部分人都宁愿选择重写而不是重构。
*****
维护代码的时间远远大于编写代码的时间
* **代码易维护**,在不破坏原有代码设计、不引入新的 bug 的情况下,能够快速地修改或者添加代码
* **代码不易维护**,修改或者添加代码需要冒着极大的引入新 bug 的风险,并且需要花费很长的时间才能完成
如果代码分层清晰、模块化好、高内聚低耦合、遵从基于接口而非实现编程的设计原则等等,那就可能意味着代码易维护。除此之外,代码的易维护性还跟项目代码量的多少、业务的复杂程度、利用到的技术的复杂程度、文档是否全面、团队成员的开发水平等诸多因素有关
*****
软件设计大师 Martin Fowler 曾经说过:“Any fool can write code that a computer can understand. Good programmers write code that humans can understand.”翻译成中文就是:“任何傻瓜都会编写计算机能理解的代码。好的程序员能够编写人能够理解的代码。”
* **可读性**,代码是否符合编码规范、命名是否达意、注释是否详尽、函数是否长短合适、模块划分是否清晰、是否符合高内聚低耦合等等,**代码注释需要额外的维护成本,往往一段代码被多次改动后,注释却没有被同步更新,所以尽量避免写注释,代码本身就是注释**。如果你的同事可以轻松地读懂你写的代码,那说明你的代码可读性很好;如果同事在读你的代码时,有很多疑问,那就说明你的代码可读性有待提高了
*****
* **可扩展性**代码预留了一些功能扩展点,你可以把新功能代码,直接插到扩展点上,而不需要因为要添加一个功能而大动干戈,改动大量的原始代码
*****
* **灵活性**,原有的代码已经预留好了扩展点,我们不需要修改原有的代码,只要在扩展点上添加新的代码即可,实现一个功能的时候,发现原有代码中,已经抽象出了很多底层可以复用的模块、类等代码,我们可以拿来直接使用,如果这组接口可以应对各种使用场景,满足各种不同的需求,我们除了可以说接口易用之外,还可以说这个接口设计得好灵活或者代码写得好灵活
*****
* **简洁性**,用最简单的方法解决最复杂的问题
*****
* **可复用性**,尽量减少重复代码的编写,复用已有的代码
*****
* **可测试性**
>[danger] ##### 文章引用
[设计模式之美](https://time.geekbang.org/column/article/160991)
>[success] # 代码重构
随着需求的变化,代码的不停堆砌,原有的设计必定会存在这样那样的问题。针对这些问题,我们就需要进行代码重构。重构是软件开发中非常重要的一个环节。持续重构是保持代码质量不下降的有效手段,能有效避免代码腐化到无可救药的地步
虽然使用设计模式可以提高代码的可扩展性,但过度不恰当地使用,也会增加代码的复杂度,影响代码的可读性。在开发初期,除非特别必须,我们一定不要过度设计,应用复杂的设计模式。而是当代码出现问题的时候,我们再针对问题,应用原则和模式进行重构。这样就能有效避免前期的过度设计
* 重构的目的(why)、对象(what)、时机(when)、方法(how)
* 保证重构不出错的技术手段:单元测试和代码的可测试性
* 两种不同规模的重构:大重构(大规模高层次)和小重构(小规模低层次), **大重构 系统结构层面的重构、具体逻辑实现层面的重构 小重构 不符合编码规范的代码改为符合编码规范的代码(可以通过自动lint工具避免小重构)**
