>[success] # 高内聚、松耦合
**高内聚**是`模块(后台class 前端hooks 等)`功能的**专一性高,独立性强**.**低耦合**是模块之间的**联系尽量少,尽量简单**,这句话是描述**模块设计的两个方面**
* **高内聚**相近的功能应该放到同一个类中,不相近的功能不要放到同一个类中。相近的功能往往会被同时修改,放到同一个类中,修改会比较集中,代码容易维护
* **低耦合**类与类之间的依赖关系简单清晰。即使两个类有依赖关系,一个类的代码改动不会或者很少导致依赖类的代码改动
>[danger] ##### 高内聚、松耦合之间关系
`高内聚`有助于`松耦合`,同理,`低内聚`也会导致`紧耦合`
* [图片来自极客时间](https://time.geekbang.org/column/article/179615)
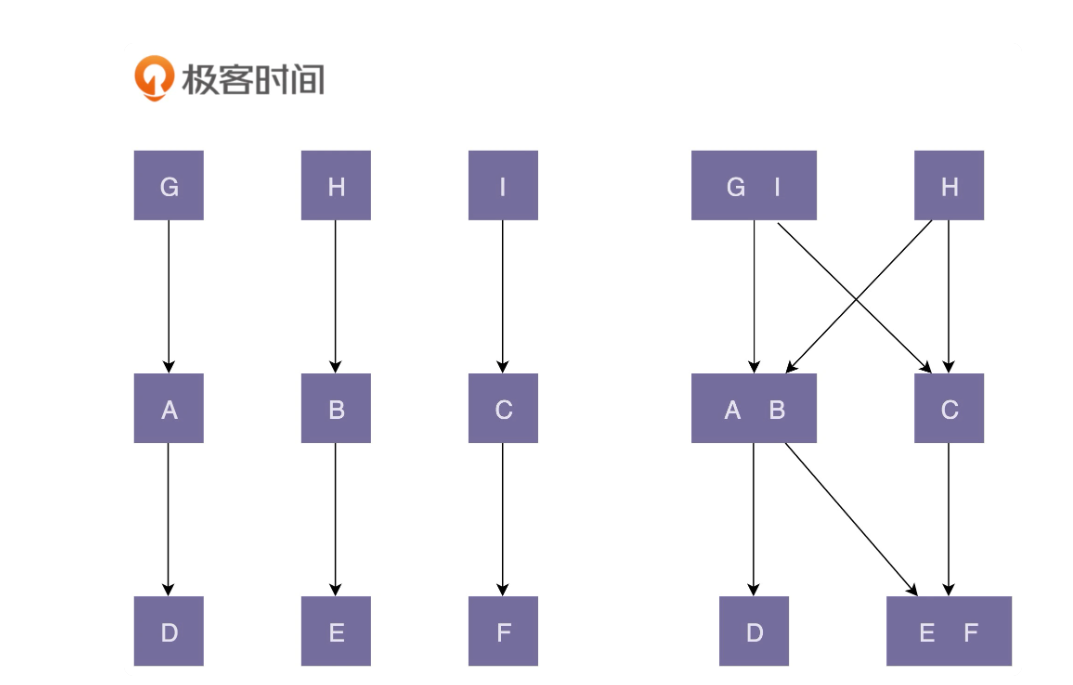
左面符合,**高内聚、松耦合**,将每个类都颗粒化,属于自己的功能都高度聚集,减少了代码直接的耦合度,这样在更改代码时候影响到依赖少,改动少
右面属于**低内聚,紧耦合**,将`G和I `的实现混为一个功能模块,构成了**低内聚**因此 产生了错综复杂的模块间相互依赖形成了**紧耦合**,当我们修改这个类的某一个功能代码的时候,会影响依赖它的多个类
>[danger] ##### 内聚
内聚程度从`低到高`,即**越往下越高内聚越推荐**
* **偶然内聚**:一个模块内的各处理元素之间没有任何联系,只是偶然地被凑到一起。这种模块也称为巧合内聚
* **逻辑内聚**:这种模块把几种相关的功能组合在一起, 每次被调用时,由传送给模块参数来确定该模块应完成哪一种功能
* **时间内聚**:把需要同时执行的动作组合在一起形成的模块称为时间内聚模块
* **过程内聚**:构件或者操作的组合方式是,允许在调用前面的构件或操作之后,马上调用后面的构件或操作,即使两者之间没有数据进行传递。简单的说就是如果一个模块内的处理元素是相关的,而且必须以特定次序执行则称为过程内聚(要完成登录的功能,前一个功能判断网络状态,后一个执行登录操作,显然是按照特定次序执行的)
* **通信内聚**:指模块内所有处理元素都在同一个数据结构上操作或所有处理功能都通过公用数据而发生关联(有时称之为信息内聚)。即指模块内各个组成部分都使用相同的数据结构或产生相同的数据结构
* **顺序内聚**:一个模块中各个处理元素和同一个功能密切相关,而且这些处理必须顺序执行,通常前一个处理元素的输出时后一个处理元素的输入
* **功能内聚**:模块内所有元素的各个组成部分全部都为完成同一个功能而存在,共同完成一个单一的功能,模块已不可再分。即模块仅包括为完成某个功能所必须的所有成分,这些成分紧密联系、缺一不可。
*****
**功能内聚**是最强的内聚,其优点是它的功能明确
>[danger] ##### 耦合
耦合程度从`高到低`,即**越往下越高内聚越推荐**
* **内容性耦合**,即模块间存在某个模块访问另一个模块内部数据的情况,或者模块间不是通过正常的数据交换接口来交换数据的,都称其为内容性耦合,这种耦合或导致内容的混乱,引发逻辑冲突;(内容耦合可能在汇编语言中出现。大多数高级语言都已设计成不允许出现内容耦合。这种耦合的耦合性最强,模块独立性最弱。)
* **公共耦合**:一组模块都访问同一个全局数据结构,则称之为公共耦合。公共数据环境可以是全局数据结构、共享的通信区、内存的公共覆盖区等。如果模块只是向公共数据环境输入数据,或是只从公共数据环境取出数据,这属于比**较松散的公共耦合**;如果模块既向公共数据环境输入数据又从公共数据环境取出数据,这属于**较紧密的公共耦合** 缺点:
1. 无法控制各个模块对公共数据的存取,严重影响了软件模块的可靠性和适应性。
2. 使软件的可维护性变差。若一个模块修改了公共数据,则会影响相关模块。
3. 降低了软件的可理解性。不容易清楚知道哪些数据被哪些模块所共享,排错困难。一般地,仅当模块间共享的数据很多且通过参数传递很不方便时,才使用公共耦合。
* **外部耦合**:即多个模块做访问全局变量时,不通过约束的结构性参数来传递信息,而是直接使用简单的变量传递信息,这回导致逻辑语义的缺失,致使模块间的功能依赖不易理解;
* **控制耦合**:模块之间传递的不是数据信息,而是控制信息例如标志、开关量等,一个模块控制了另一个模块的功能。
* **数据性耦合**,即模块间接依赖是通过数据交换来完成成的,数据交换过程中不存在控制信息,模块间只关注彼此的数据交换协议,而不关注模块内部的数据处理和逻辑控制;(有点函数传参的味道)
* **非直接耦合**,即平行模块间不存在彼此的依赖,它们的运行只依赖其上层模块的调度。
*****
**非直接耦合**作为耦合度最低效果最好的
>[info] ## 高内聚低耦合和其他原则关联
实际上,所有设计原则的目的都是提高代码的扩展性,实现高内聚、低耦合,只是手段(出发角度)不同:
1. 开闭原则是从理念本身出发
2. 单一职责原则是从功能的角度出发;
3. 迪米特原则从类之间的关系出发(不该依赖的不依赖,要依赖的最小必要依赖);
4. 接口隔离原则是从接口调用者的角度出发;
5. 里式替换原则是从类的继承关系角度出发;
6. 控制反转(依赖倒置)原则是从程序的控制权角度出发。 目的是提高代码可读性和可维护性从而间接提升代码可扩展性的设计原则有: 1. KISS、YAGNI 2. DRY ----- > 目的都是实现高内聚低耦合,但是出发的角度不一样,单一职责是从自身提供的功能出发,迪米特法则是从关系出发,针对接口而非实现编程是使用者的角度,殊途同归。
*****
1. 单一职责原则 适用对象: 模块,类,接口 白话:职责太多,容易被依赖(高耦合),以后维护,容易牵一发而动全身。(易维护性)
2. 接口隔离原则 适用对象:接口,函数 白话:有些是不需要让你知道的,避免调用者需要了解的太多(最小知识原则)。有些是不能让你知道的,属于权限问题,需要隔离开来。
3. 基于接口而非实现编程 适用对象: 接口,抽象类 白话:易维护和可扩展性问题。业务不稳定,于是依赖相对稳定的接口。
4. 迪米特法则 适用对象:模块,类 白话:这个只是原则,不是说从谁的角度考虑吧。只要符合这个原则,就能做到高内聚、低耦合。
>[info] ## 参考
[设计模式之美](https://time.geekbang.org/column/article/179615)
[# 高内聚低耦合的设计原则](https://zhuanlan.zhihu.com/p/546934025)
[# 低耦合,高内聚的详解(绝对全面)](https://blog.csdn.net/fengye454545/article/details/79592751)
