>[success] # 单一职责
单一职责原则的英文是 `Single Responsibility Principle`,原则的英文描述是这样的:`A class or module should have a single responsibility`中文意思**一个类或者模块只负责完成一个职责(或者功能)** 更通俗意思 **在定义类、接口、方法后,不能多于一个动机去改变这个类、接口、方法。**
* 在《敏捷软件开发:原则、模式与实践》这本书中,把**职责**定义为**变化的原因**。如果你能够想到多于一个的动机去改变一个类,那么这个类就具有多于一个的职责
* 一个类只负责完成一个职责或者功能。也就是说,不要设计大而全的类,要设计**粒度小、功能单一**的类
* 一个类包含了**两个或者两个以上业务不相干的功能**,那我们就说它职责不够单一,应该将它拆分成多个功能更加单一、粒度更细的类
*****
* **总结**:一个类只负责完成一个职责或者功能。不要设计大而全的类,要设计粒度小、功能单一的类。单一职责原则是为了实现代码高内聚、低耦合,提高代码的复用性、可读性、可维护性。
*****
例如,在转账的情况下,它应该只负责传入转账,而不是同时负责传出、传入和国际转账。此外,在这个特定的例子中,我们的类设计必须足够灵活,不需要在数据库架构更新后进行更改
>[danger] ##### 为什么要做职责分离
* [图片来自 职责原则:如何在代码设计中实现职责分离?](https://kaiwu.lagou.com/course/courseInfo.htm?courseId=710#/detail/pc?id=6872)
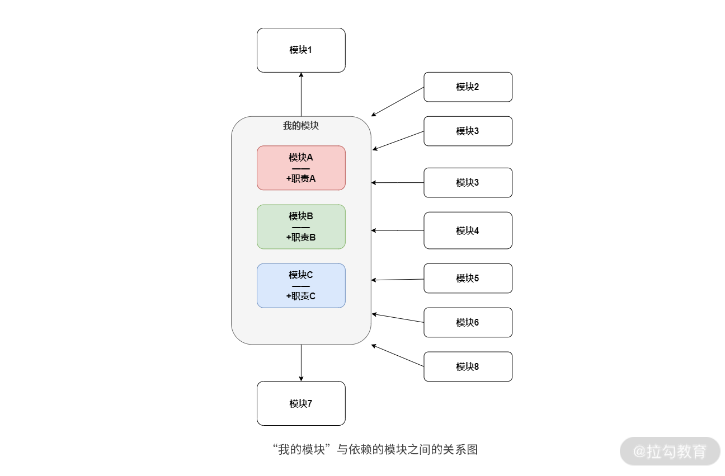
上图中,`我的模块`作为一个单独模块内部包含了`模块 A、B、C`,但包含的`模块 A、B、C`之间没有相互关联,外界的其他八个模块都和`我的模块`有关联,此时如果修改`A`变相的`我的模块`也被改动,那么其余八个模块都有需要重新测试风险,或者其他未来业务需要和`模块 A、B、C`中单独任意一个模块通信都需要和`我的模块`整体通信
* 提高内聚 划分清除职责[图片来自 职责原则:如何在代码设计中实现职责分离?](https://kaiwu.lagou.com/course/courseInfo.htm?courseId=710#/detail/pc?id=6872)
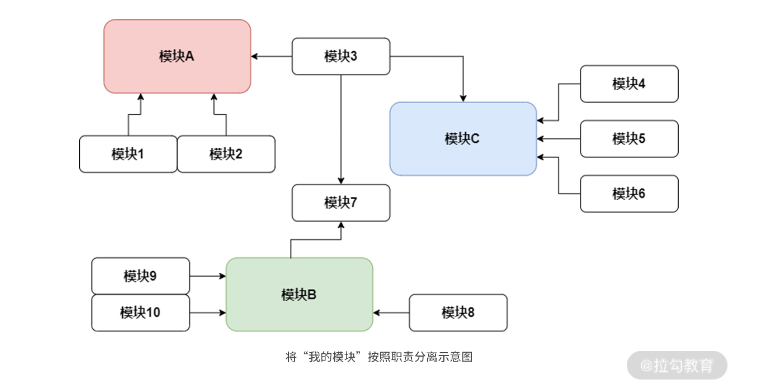
上图中讲我的模块去掉依赖模块直接找到彼此需要的对接,各个模块专注于自己最重要的某个职责,并建立起与其他模块之间清晰的界限
* 总结:**内聚本质上表示的是系统内部的各个部分对同一个问题的专注程度,以及这些部分彼此之间联系的紧密性**,对同一个问题的专注程度才是判断内聚高低的标准,而职责分离只是实现高内聚的一种方法而已
>[danger] ##### 职责分离的重要性
1. **直接对问题进行对象建模,方便厘清构建逻辑**
2. **将问题分解为各种职责,更有利于系统的测试、调试和维护**
3. **提高系统的可扩展性**
>[danger] ##### 从场景出发来看单一职责
并不是任何情况都要做到单一职责,
* **场景一** 类 T 只负责一个职责P,这样设计是符合单一职责原则的。后来由于某种原因,也许是需求变更了,也许是程序的设计者境界提高了,需要将职责 P 细分为粒度更细的职责 P1,P2,这时如果要使程序遵循单一职责原则,需要将类T也分解为两个类 T1 和 T2,分别负责 P1、P2 两个职责。但是在程序已经写好的情况下,这样做简直太费时间了。所以,简单的修改类 T,用它来负责两个职责是一个比较不错的选择,虽然这样做有悖于单一职责原则。(这样做的风险在于职责扩散的不确定性,因为我们不会想到这个职责P,在未来可能会扩散为P1,P2,P3,P4……Pn。所以记住,在职责扩散到我们无法控制的程度之前,立刻对代码进行重构。)
* **场景二**
~~~
public class UserInfo {
private long userId;
private String username;
private String email;
private String telephone;
private long createTime;
private long lastLoginTime;
private String avatarUrl;
private String provinceOfAddress; // 省
private String cityOfAddress; // 市
private String regionOfAddress; // 区
private String detailedAddress; // 详细地址
// ...省略其他属性和方法...
}
~~~
UserInfo 类包含的都是跟用户相关的信息,所有的属性和方法都隶属于用户这样一个业务模型,满足单一职责原则;另一种观点是,地址信息在 UserInfo 类中,所占的比重比较高,可以继续拆分成独立的 UserAddress 类,UserInfo 只保留除 Address 之外的其他信息,拆分之后的两个类的职责更加单一,这要根据场景具体分析是否适合,如果后期公司发展增加了地址维护等一些场景那将地址抽离为类效果更好
* **场景三**
接收命令行的任意字符串参数,然后反转每个字符,并检查反转后的字符是否为“hello world”,如果是,则打印一条信息
~~~
public class Application {
private static void process(String[] words) {
for (int i = 0; i < words.length; i++) {
String arg = "";
for (int j = words[i].length(); j > 0; j--) {
arg+=words[i].substring(j-1,j);
}
System.out.println(arg);
}
if (words.length == 2){
if (words[0].toLowerCase().equals("hello")
&& words[1].toLowerCase().equals("world")){
System.out.println("...bingo");
}
}
}
public static void main(String[] args) {
process(new String[]{"test","is","a","mighty,hahaah,world"});
process(new String[]{"hello","world"});
}
}
~~~
上面代码中`process()` 直接看名字并不能很好理解这个方法打算做什么,如果纯根据我们需求去起这个变量名,可能名字叫`reverseCharactersAndTestHelloWorld()`(反转字符和测试helloword),确实比之前可以通过方法名大概知道方法部分功能实现,但是命名太过于笼统的通常就是内聚性较差的信号
* **分离后效果**
~~~
public class ApplicationOpt {
public void process(String[] words) {
for (int i = 0; i < words.length; i++) {
reversecharacters(words[i]);
System.out.println(words[i]);
}
if (isHelloWorld(words)) {
System.out.println("...bingo");
}
}
private String reversecharacters(String forward) {
String reverse = "";
for (int j = forward.length(); j > 0; j--) {
reverse += forward.substring(j - 1, j);
}
return reverse;
}
private boolean isHelloWorld(String[] names) {
if (names.length == 2){
if (names[0].toLowerCase().equals("hello")
&& names[1].toLowerCase().equals("world")){
return true;
}
}
return false;
}
public static void main(String[] args) {
ApplicationOpt myApp = new ApplicationOpt();
myApp.process(new String[]{"test","is","a","mighty,hahaah,world"});
myApp.process(new String[]{"hello","world"});
}
}
~~~
分离后,**每个步骤都由一个方法来实现,你也能很快区分每个方法具体负责的职责是什么**
* **案例四**
假设有一个书籍类,保存书籍的名称、作者、内容,提供文字修订服务和查询服务
~~~
public class Book {
private String name;
private String author;
private String text;
//constructor, getters and setters
public String replaceWordInText(String word){
return text.replaceAll(word, text);
}
public boolean isWordInText(String word){
return text.contains(word);
}
}
~~~
在后来要增加打印阅读这里功能添加,你为了方便将这个功能写到了`Book`类中,当打印服务需要针对不同的客服端进行适配时,书籍类就需要多次反复地进行修改,那么不同的类实例需要修改的地方就会越来越多,系统明显变得更加脆弱,同时也违反了 SRP
~~~
public class Book {
//...
//打印服务
void printText(){
//具体实现
}
//阅读服务
void getToRead(){
//具体实现
}
}
~~~
>[danger] ##### 职责是否具有唯一性
**职责是否具有唯一性**。当你有多个动机来改变一个类时,那么职责就多于一个,也就违反了 SRP。
>[danger] ##### 考虑职责分离的时机
**从不同的业务层面去看待同一个类的设计,对类是否职责单一,也会有不同的认识**,**[设计模式之美](https://time.geekbang.org/column/article/171771)** 王争老师给了几条判断原则,比起很主观地去思考类是否职责单一,要更有指导意义、更具有可执行性
1. 类中的代码行数、函数或属性过多,会影响代码的可读性和可维护性,我们就需要考虑对类进行拆分;
2. 类依赖的其他类过多,或者依赖类的其他类过多,不符合高内聚、低耦合的设计思想,我们就需要考虑对类进行拆分;
3. 私有方法过多,我们就要考虑能否将私有方法独立到新的类中,设置为 public 方法,供更多的类使用,从而提高代码的复用性
4. 比较难给类起一个合适名字,很难用一个业务名词概括,或者只能用一些笼统的 Manager、Context 之类的词语来命名,这就说明类的职责定义得可能不够清晰
5. 类中大量的方法都是集中操作类中的某几个属性,比如,在 UserInfo 例子中,如果一半的方法都是在操作 address 信息,那就可以考虑将这几个属性和对应的方法拆分出来
>[danger] ##### 单一职责原则优点
* 可以降低类的复杂度,一个类只负责一项职责,其逻辑肯定要比负责多项职责简单的多,但职责不一定只有一个类或方法,还可能有多个类或方法,比如,上传文件是单一职责,而上传方法、增删改查 URL 方法、校验方法都服务于上传文件
* 提高类的可读性,提高系统的可维护性
* 变更引起的风险降低,变更是必然的,如果单一职责原则遵守的好,当修改一个功能时,可以显著降低对其他功能的影响
>[danger] ##### 总结
**评价一个类的职责是否足够单一,我们并没有一个非常明确的、可以量化的标准**,**可以先写一个粗粒度的类,满足业务需求。随着业务的发展,如果粗粒度的类越来越庞大,代码越来越多,这个时候,我们就可以将这个粗粒度的类,拆分成几个更细粒度的类。这就是所谓的持续重构**
关于代码行数也给建议 **,如果你是没有太多项目经验的编程初学者,实际上,我也可以给你一个凑活能用、比较宽泛的、可量化的标准,那就是一个类的代码行数最好不能超过 200 行,函数个数及属性个数都最好不要超过 10 个。**
* 单一职责原则通过避免设计大而全的类,避免将不相关的功能耦合在一起,来提高类的内聚性。同时,类职责单一,类依赖的和被依赖的其他类也会变少,减少了代码的耦合性,以此来实现代码的高内聚、低耦合。但是,如果拆分得过细,实际上会适得其反,反倒会降低内聚性,也会影响代码的可维护性。
>[info] ## 参考文章
[设计模式之美](https://time.geekbang.org/column/article/171771)
[单一职责原则SRP](https://geek-docs.com/design-pattern/design-principle/single-responsibility-principle.html)
[单一职责原则:软件世界中最重要的规则 - DZone](https://www.jdon.com/57486)
[# 职责原则:如何在代码设计中实现职责分离?](https://kaiwu.lagou.com/course/courseInfo.htm?courseId=710#/detail/pc?id=6872)
