
[TOC]
## ASCII 表
总所周知,计算机起源于美国,英文只有26字符,算上其他所有特殊符号也不会超过128个。字节是计算机的基本存储单位。一个字节(bytes)包括八个比特位(bit)。能够表示出256(2^8)个二进制数字,所以美国人在这里只是用到了一个字节的前七位即127个数字来对应了127个具体字符。而这张对应表就是ASCII码字符编码表,简称ASCII表。后来为了能够让计算机识别拉丁文,就像一个字节的最高位也应用了。这样就多扩展出128个二进制数字来对应新的符号。这张对应表因为是在ASCII表的基础上扩展的最高位,因此称为扩展ASCII表。到此位置,一个字节能表示的256个二进制数据都有了特殊的字符对应。
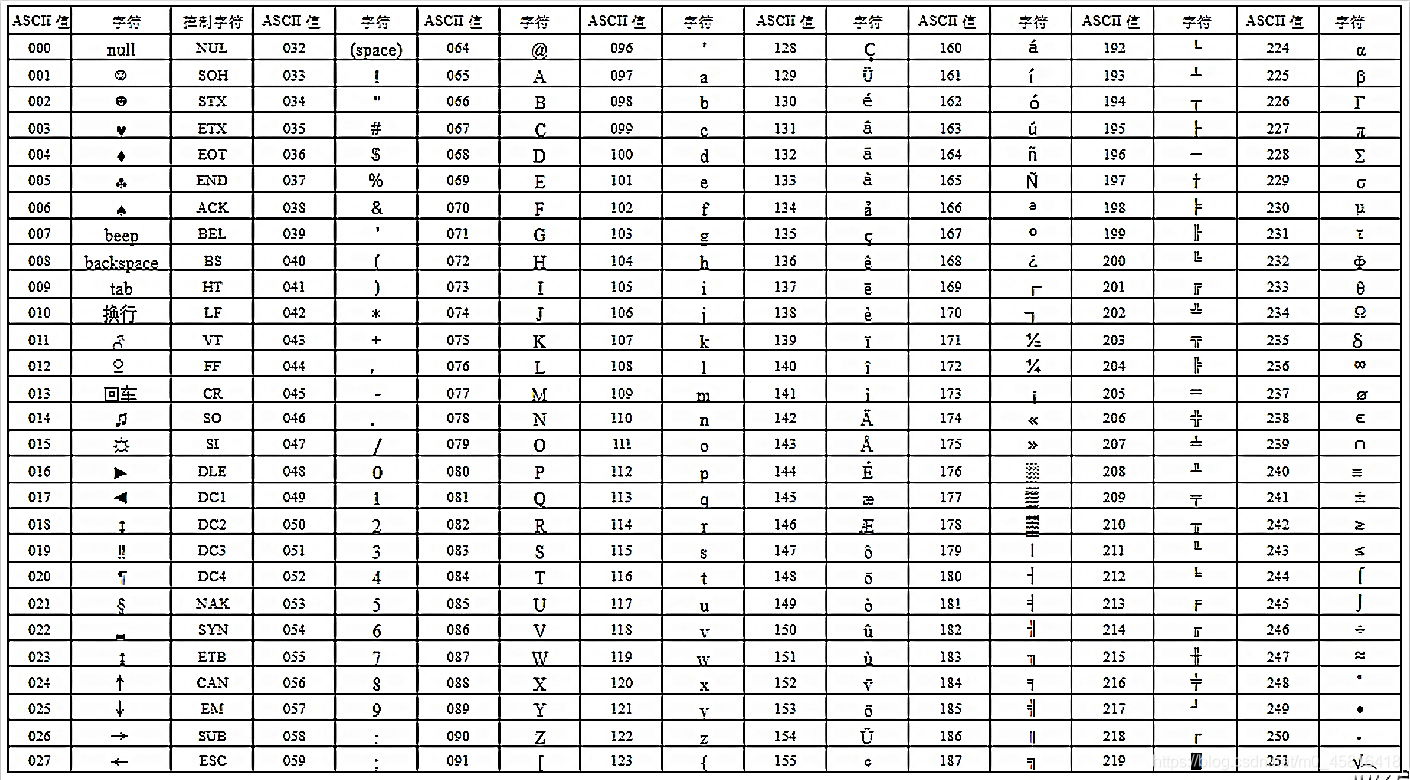
> 注:表中000-127是标准的。128-255是扩展的
## GBK 编码
当计算机发在到东亚国家后,问题又出现了。像中文、韩文、日文等符号也需要在计算机上显示。可是一个字节已经被西方国际占满了。于是,中华民族自己重写一张对应表。直接生猛地将扩展的第八位对应拉丁文全部删掉。规定一个小于127的字符的意义与原来相同。即支持ASCII码表。但两个大于127的字符连在一起时,就表示一个汉字。这样子就可以将几千个汉字对应一个个二进制数了。而这种编码方式就是GB2312,也称为中文扩展ASCII码表。再后来,我们为了对应更多的汉字规定只要第一个字节是大于127就固定表示这是一个汉字的开始。不管后面跟的是不是扩展字符串里的内容。这样子能多出几万个二进制字,就算甲骨文也能够用了。而这次扩展的编码方式称为GBK标准。当然,GBK标准下,一个像“曾”这样的中文字符,必须占两个字节才能存储显示。
## Unicode 与 utf8 编码
与此同时,其他国家也都开发出一套编码方式。即本国文字符号和二进制数字的对应表。而国家彼此间的编码方式是互不支持的,这会导致很多问题。于是ISO国际化标准组织为了统一编码。统计了世界上所有国家的字符,开发出了一张万国码字符表,用两个字节即六万多个二进制数字来对应。这就是 Unicode 编码方式。这样,每个国家都使用这套编码方式就再也不会有计算机的编码问题了。 Unicode 的编码特点是对应任意一个字符,都需要两个字节来存储。这对于美国人而言无异于吃上了世界的大锅板,也就是说,如果用ASCII码表,明明一个字节就可以存储的字符现在为了兼容其他语言而需要两个字节了。比如字母"A",本可以用 01000001 来存储,现在要用Unicode只能是 00000000 01000001 存储。而这将导致大量的空间被浪费掉,基于此,美国人创建了 utf8 编码,而utf8编码是一种针对 Unicode 的可变长字符编码方式,根据具体不同的字符计算出需要字节,对于ASCII码范围的字符。就用一个字符,而且符号与数字的对应也是一致的。所以说 utf8 是兼容 ASCII 码表的。但是对于中文,一般是用三个字节存储的。
- Golang简介
- 开发环境
- Golang安装
- 编辑器及快捷键
- vscode插件
- 第一个程序
- 基础数据类型
- 变量及匿名变量
- 常量与iota
- 整型与浮点型
- 复数与布尔值
- 字符串
- 运算符
- 算术运算符
- 关系运算符
- 逻辑运算符
- 位运算符
- 赋值运算符
- 流程控制语句
- 获取用户输入
- if分支语句
- for循环语句
- switch语句
- break_continue_goto语法
- 高阶数据类型
- pointer指针
- array数组
- slice切片
- slice切片扩展
- map映射
- 函数
- 函数定义和调用
- 函数参数
- 函数返回值
- 作用域
- 函数形参传递
- 匿名函数
- 高阶函数
- 闭包
- defer语句
- 内置函数
- fmt
- strconv
- strings
- time
- os
- io
- 文件操作
- 编码
- 字符与字节
- 字符串
- 读写文件
- 结构体
- 类型别名和自定义类型
- 结构体声明
- 结构体实例化
- 模拟构造函数
- 方法接收器
- 匿名字段
- 嵌套与继承
- 序列化
- 接口
- 接口类型
- 值接收者和指针接收者
- 类型与接口对应关系
- 空接口
- 接口值
- 类型断言
- 并发编程
- 基本概念
- goroutine
- channel
- select
- 并发安全
- 练习题
- 第三方库
- Survey
- cobra