
:-: 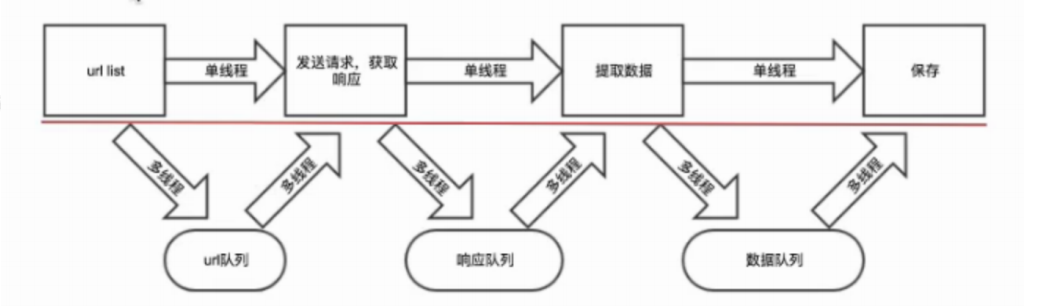
多线程与单线程爬虫流程图
```python
"""
@Date 2021/4/5
"""
import requests
from lxml import etree
from urllib import request
import threading
from queue import Queue
class Producer(threading.Thread):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36',
'Host': 'www.doutula.com',
'Cookie': '__cfduid=d0482fd98715b92c3742dd452c58abe991582206241; UM_distinctid=17062d74e572d0-06f72cf9e39479-2393f61-1fa400-17062d74e595e0; CNZZDATA1256911977=1187705542-1582204806-%7C1582204806; _ga=GA1.2.188432079.1582206243; _gid=GA1.2.321283468.1582206243; __gads=ID=b074b5de9483e3e6:T=1582206242:S=ALNI_MY0LJl_kXttlOHBqkHIVODQTtkVmQ; _agep=1582206244; _agfp=698bc2e12789df094f2cdcc72a7f6225; _agtk=e92fbe464dff15783076bd9190dd965b; XSRF-TOKEN=eyJpdiI6IktrNHNhRUdBNDNtbENxOU5TdnBZUXc9PSIsInZhbHVlIjoiVTE5eVZTbWdTNTJyRmJwdnBcLzhieVlSb2YzMFNjQlNzMEN6YlNiSXJ0NXpBNnA3YjNwcUxNTFFGdEpjbWRDenUiLCJtYWMiOiI0MWFjYzRkN2RlYjMwNDI0OWI2YTc0Y2VhNjQ4ZTkyNGZkOGFmYmU4YTk5ZTUzNzU4M2FhYjMzMzEzOTk3MWZlIn0%3D; doutula_session=eyJpdiI6InRaa09IWis4K0Jic2pIdm9tNnlJWUE9PSIsInZhbHVlIjoianc5QUV4WGYrMFA1R2g1S3pNU2tGU2g5b1RPVG8yaDEwenRuXC9Vdk8rZW5MN0dqbTNNSUpsWjVIMmhDWHJPcjkiLCJtYWMiOiI0OTUxZDQxMThmMmFhMDcyZDAwZGYxNGViY2JhOGQ3Mjg0MzY0MDgxNjExMTE5NGQ3NmYwMGEwNTYzMDM3MDEwIn0%3D'
}
def __init__(self, page_queue, img_queue):
super().__init__()
self.page_queue = page_queue
self.img_queue = img_queue
def run(self):
while True:
if self.page_queue.empty():
break
url = self.page_queue.get()
self.parse_page(url)
def parse_page(self, url):
response = requests.get(url, headers=self.headers)
text = response.text
html = etree.HTML(text)
imgs = html.xpath("//div[@class='page-content text-center']//img")
for img in imgs:
img_url = img.get('data-original')
alt = img.get('alt')
self.img_queue.put((img_url, alt))
class Consumer(threading.Thread):
def __init__(self, page_queue, img_queue):
super().__init__()
self.page_queue = page_queue
self.img_queue = img_queue
def run(self):
while True:
if self.page_queue.empty() and self.img_queue.empty():
break
img = self.img_queue.get()
img_url, filename = img
# 将图片保存到自己电脑的images/{}.jpg路径中
request.urlretrieve(img_url, 'images/{}.jpg'.format(filename))
print("正在下载-{}".format(filename))
def main():
"""
Producer线程负责获取图片的url,Consumer线程负责将图片写入到磁盘中
"""
page_queue = Queue(100)
img_queue = Queue(500)
for page in range(1, 101):
url = 'http://www.doutula.com/photo/list/?page={}'.format(page)
page_queue.put(url)
for i in range(5):
t = Producer(page_queue, img_queue)
t.start()
for i in range(5):
t = Consumer(page_queue, img_queue)
t.start()
if __name__ == '__main__':
main()
```
- 爬虫基本概念
- 爬虫介绍
- 通用爬虫与聚焦爬虫
- 通用爬虫
- 聚焦爬虫
- HTTP与HTTPS协议
- HTTP协议简介
- HTTP的请求与响应
- 客户端HTTP请求
- 服务端HTTP响应
- requests库
- requests库简介
- requests简单使用
- 发送带header的请求
- 发送带参数的请求
- 案例:下载百度贴吧页面
- 发送POST请求
- 使用代理
- 为什么要使用代理?
- 正反向代理
- 代理服务器分类
- 使用代理
- cookie和session
- cookie和session的区别
- 爬虫处理cookie和session
- 使用session登录网站
- 使用cookie登录网站
- cookiejar
- 超时和重试
- verify参数忽略CA证书
- URL地址的解码和编码
- 数据处理
- json数据处理
- json数据处理方案
- json模块处理json数据
- jsonpath处理json数据
- 正则表达式
- lxml
- xpath与lxml介绍
- xpathhelper插件
- 案例
- Beautiful Soup
- Beautiful Soup介绍
- 解析器
- CSS选择器
- 案例
- 四大对象
- 爬虫与反爬虫
- 爬虫与反爬虫的斗争
- 服务器反爬的原因
- 什么样的爬虫会被反爬
- 反爬领域常见概念
- 反爬的三个方向
- 基于身份识别进行反爬
- 基于爬虫行为进行反爬
- 基于数据加密进行反爬
- js解析
- chrome浏览器使用
- 定位js
- 设置断点
- js2py
- hashlib
- 有道翻译案例
- 动态爬取HTML
- 动态HTML
- 获取Ajax数据的方式
- selenium+driver
- driver定位
- 表单元素操作
- 行为链
- cookie操作
- 页面等待
- 多窗口与页面切换
- 配置对象
- 拉勾网案例
- 图片验证码识别
- 图形验证码识别技术简介
- Tesseract
- pytesseract处理图形验证码
- 打码平台
- 登录打码平台
- 验证码种类
- 多任务-线程
- 继承Thread创建线程
- 查看线程数量
- 资源共享
- 互斥锁
- 死锁
- 避免死锁
- Queue线程
- 多线程爬虫
- 多任务-进程
- 创建进程
- 进程池
- 进程间的通信
- Python GIL
- scrapy框架
- scrapy是什么?
- scrapy爬虫流程
- 创建scrapy项目
- Selector选择器
- logging
- scrapy shell
- 保存数据
- Item数据建模
- 翻页请求
- Request
- CrawlSpider
- settings
- 模拟登录
- 保存文件
- 内置Pipeline
- 自定义Pipeline
- 中间件
- selenium动态加载
- 防止反爬
- 随机User-Agent
- 随机IP代理
- settings中的参数
- 随机延迟
- request.meta常用参数
- 分布式爬虫
- 分布式原理
- scrapy_redis
- 去重问题
- 分布式爬虫编写流程
- CrawSpider改写成分布式
- scrapy_splash
- scrapy_splash是什么?
- scrapy_splash环境搭建
- APP抓取
- Android模拟器
- appium
- appium是什么?
- appium环境搭建
- appium环境联调测试
- appium的使用
- 演示项目-抓取抖音app
- 抖音app与appium的联调测试
- 元素定位
- 抖音appium代码
- 抓包软件
- url去重处理