
多台服务器执行一个大型任务,就会有某一个小任务重复问题,比如服务器1下载了 http://www.baidu.com/test.png 这张图片,如果不去重则服务器2也会下载这张图片。
<br/>
scrapy_redis通过将 url 放在一个Redis数据库的 list 数据类型中,并将这个Redis数据库与所有相关的服务器共享,当服务器1的任务是下载 http://www.baidu.com/test.png 这张图片,则将 http://www.baidu.com/test.png 从Redis数据库的 list 删除(pop),所以其它服务器就不会重复执行这个任务了。
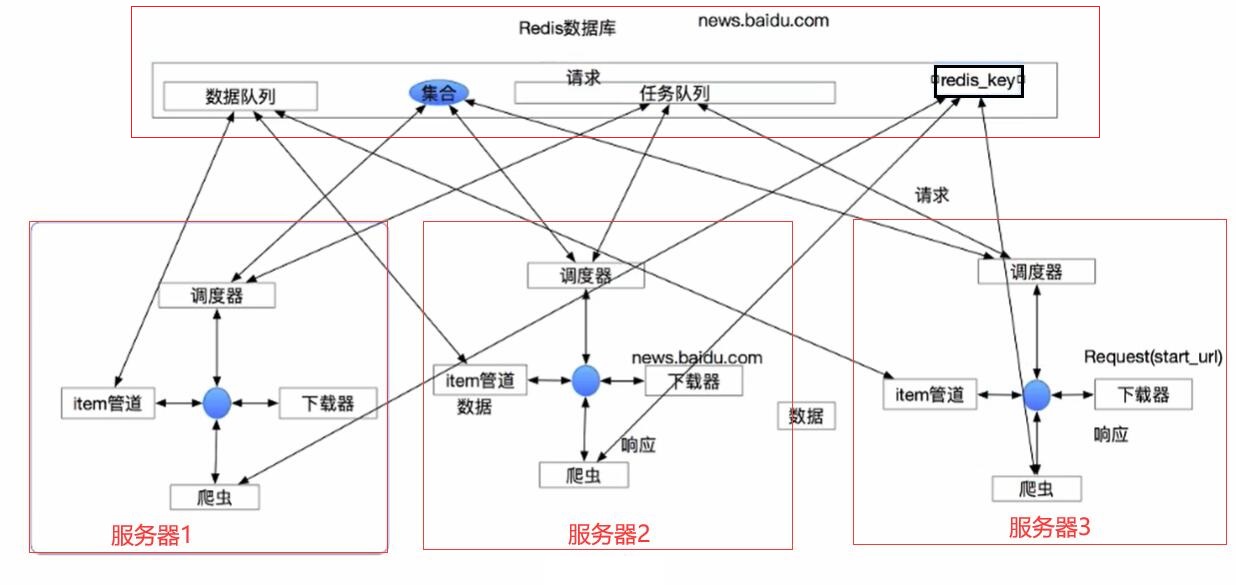
1. 分布式爬虫可以有任意个节点,但是始终只有一个Redis数据库;
2. 三个服务器通过调度器将url放入集合中去重,如果集合中判断该url还没有被执行,则将这个url放入任务队列中等待执行;如果已被执行,则该url被忽略;
3. 数据队列:这个可有可无,它存在的目的是方便不同服务器将数据保存到同一个Redis数据库,这个数据队列就是我们任务的总数;
4. 资源分配:分配策略就是抢占,三个服务器根据自身速度抢占任务,谁先抢到这个任务就由谁执行。
- 爬虫基本概念
- 爬虫介绍
- 通用爬虫与聚焦爬虫
- 通用爬虫
- 聚焦爬虫
- HTTP与HTTPS协议
- HTTP协议简介
- HTTP的请求与响应
- 客户端HTTP请求
- 服务端HTTP响应
- requests库
- requests库简介
- requests简单使用
- 发送带header的请求
- 发送带参数的请求
- 案例:下载百度贴吧页面
- 发送POST请求
- 使用代理
- 为什么要使用代理?
- 正反向代理
- 代理服务器分类
- 使用代理
- cookie和session
- cookie和session的区别
- 爬虫处理cookie和session
- 使用session登录网站
- 使用cookie登录网站
- cookiejar
- 超时和重试
- verify参数忽略CA证书
- URL地址的解码和编码
- 数据处理
- json数据处理
- json数据处理方案
- json模块处理json数据
- jsonpath处理json数据
- 正则表达式
- lxml
- xpath与lxml介绍
- xpathhelper插件
- 案例
- Beautiful Soup
- Beautiful Soup介绍
- 解析器
- CSS选择器
- 案例
- 四大对象
- 爬虫与反爬虫
- 爬虫与反爬虫的斗争
- 服务器反爬的原因
- 什么样的爬虫会被反爬
- 反爬领域常见概念
- 反爬的三个方向
- 基于身份识别进行反爬
- 基于爬虫行为进行反爬
- 基于数据加密进行反爬
- js解析
- chrome浏览器使用
- 定位js
- 设置断点
- js2py
- hashlib
- 有道翻译案例
- 动态爬取HTML
- 动态HTML
- 获取Ajax数据的方式
- selenium+driver
- driver定位
- 表单元素操作
- 行为链
- cookie操作
- 页面等待
- 多窗口与页面切换
- 配置对象
- 拉勾网案例
- 图片验证码识别
- 图形验证码识别技术简介
- Tesseract
- pytesseract处理图形验证码
- 打码平台
- 登录打码平台
- 验证码种类
- 多任务-线程
- 继承Thread创建线程
- 查看线程数量
- 资源共享
- 互斥锁
- 死锁
- 避免死锁
- Queue线程
- 多线程爬虫
- 多任务-进程
- 创建进程
- 进程池
- 进程间的通信
- Python GIL
- scrapy框架
- scrapy是什么?
- scrapy爬虫流程
- 创建scrapy项目
- Selector选择器
- logging
- scrapy shell
- 保存数据
- Item数据建模
- 翻页请求
- Request
- CrawlSpider
- settings
- 模拟登录
- 保存文件
- 内置Pipeline
- 自定义Pipeline
- 中间件
- selenium动态加载
- 防止反爬
- 随机User-Agent
- 随机IP代理
- settings中的参数
- 随机延迟
- request.meta常用参数
- 分布式爬虫
- 分布式原理
- scrapy_redis
- 去重问题
- 分布式爬虫编写流程
- CrawSpider改写成分布式
- scrapy_splash
- scrapy_splash是什么?
- scrapy_splash环境搭建
- APP抓取
- Android模拟器
- appium
- appium是什么?
- appium环境搭建
- appium环境联调测试
- appium的使用
- 演示项目-抓取抖音app
- 抖音app与appium的联调测试
- 元素定位
- 抖音appium代码
- 抓包软件
- url去重处理