
### JDK1.7 ConcurrentHashMap结构
JDK1.7 ConcurrentHashMap 数据结构如下所示:
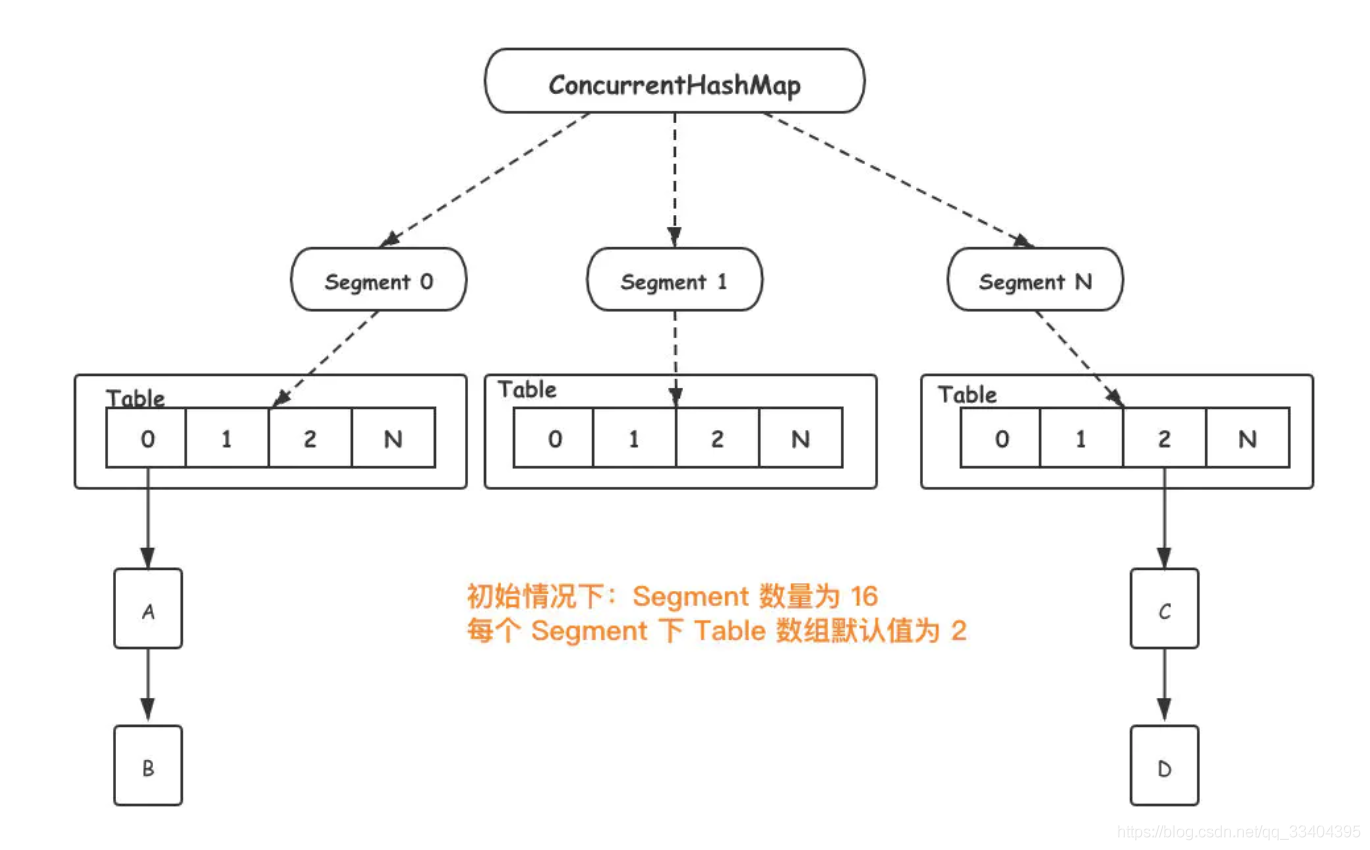
Segament 是一个ConcurrentHashMap内部类,底层结构与 HashMap 一致。另外Segament 继承自 ReentrantLock。
当新元素加入 ConcurrentHashMap 时,首先根据 key hash 值找到相应的 Segament。接着直接对 Segament 上锁,若获取成功,后续操作步骤如同 HashMap。
由于锁的存在,Segament 内部操作都是并发安全,同时由于其他 Segament 未被占用,因此可以支持 concurrencyLevel 个线程安全的并发读写
#### size统计问题
虽然 ConcurrentHashMap 引入分段锁解决多线程并发的问题,但是同时引入新的复杂度,导致计算 ConcurrentHashMap 元素数量将会变得复杂。
由于 ConcurrentHashMap 元素实际分布在 Segament 中,为了统计实际数量,只能遍历 Segament数组求和。
为了数据的准确性,这个过程过我们需要锁住所有的 Segament,计算结束之后,再依次解锁。不过这样做,将会导致写操作被阻塞,一定程度降低 ConcurrentHashMap性能。
所以这里对 ConcurrentHashMap#size 统计方法进行一定的优化。
Segment 每次被修改(写入,删除),都会对 modCount(更新次数)加 1。只要相邻两次计算获取所有的 Segment modCount 总和一致,则代表两次计算过程并无写入或删除,可以直接返回统计数量。
如果三次计算结果都不一致,那没办法只能对所有 Segment 加锁,重新计算结果。
这里需要注意的是,这里求得 size 数量不能做到 100% 准确。这是因为最后依次对 Segment 解锁后,可能会有其他线程进入写入操作。这样就导致返回时的数量与实际数不一致。
不过这也能被接受,总不能因为为了统计元素停止所有元素的写入操作
#### 性能问题
极端情况下所有写入都落在同一个`Segment`中,这就导致`ConcurrentHashMap`退化成`SynchronizedMap`,共同抢一把锁
- java演变
- JDK各个版本的新特性
- JDK1.5新特性
- JDK1.6新特性
- JDK1.7新特性
- JDK1.8新特性
- JAVA基础
- 面向对象特性
- 多态
- 方法重载
- 方法重写
- class
- 常量
- 访问修饰符
- 类加载路径
- java-equals
- 局部类
- java-hashCode
- Java类初始化顺序
- java-clone方法
- JAVA对象实例化的方法
- 基础部分
- JAVA基础特性
- JAVA关键字
- javabean
- static
- 日期相关
- final
- interface
- 函数式接口
- JAVA异常
- 异常屏蔽
- try-with-resource资源泄露
- JAVA引用
- WeakReference
- SoftReference
- PhantomReference
- 位运算符
- try-with-resource语法糖
- JDK冷知识
- JAVA包装类
- JAVA基本类型与包装类
- java.lang.Boolean
- java.lang.Integer
- java.lang.Byte
- java.lang.Short
- java.lang.Long
- java.lang.Float
- java.lang.Double
- java.lang.Character
- 日期相关
- TemporalAdjusters
- String
- 字符串常量池
- String拼接
- String编译期优化
- StringBuilder&StringBuffer
- intern
- 注解
- java标准注解
- 内置注解
- 元注解
- 自定义注解
- 注解处理器
- JVM注解
- Java8 Annotation新特性
- 反射-Reflective
- Reflection
- Class
- Constructor
- Method
- javabean-property
- MethodHandles
- 泛型
- 类型擦除
- bridge-method
- Accessor&Mutator方法
- enum
- JAVA数组
- finalize方法
- JAR文件
- JAVA高级编程
- CORBA
- JMX
- SPI
- Java SPI使用约定
- ServiceLoader
- 实际应用
- IO
- 工具类
- JDK常用工具类
- Objects
- System
- Optional
- Throwable
- Collections
- Array
- Arrays
- System
- Unsafe
- Number
- ClassLoader
- Runtime
- Object
- Comparator
- VarHandle
- 数据结构
- 栈-Stack
- 队列(Queue)
- Deque
- PriorityQueue
- BlockingQueue
- SynchronousQueue
- ArrayBlockingQueue
- LinkedBlockingQueue
- PriorityBlockingQueue
- ConcurrentLinkedQueue
- 列表
- 迭代器
- KV键值对数据类型
- HashMap
- TreeMap
- Hash冲突
- ConcurrentHashMap
- JDK1.7 ConcurrentHashMap结构
- jdk7&jdk8区别
- 集合
- Vector
- Stack
- HashSet
- TreeSet
- ArrayList
- LinkedList
- ArrayList && LinkedList相互转换
- 线程安全的集合类
- 集合类遍历性能
- 并发容器
- CopyOnWriteArrayList
- ConcurrentHashMap
- 同步容器
- BitMap
- BloomFilter
- SkipList
- 设计模式
- 设计模式六大原则
- 单例模式
- 代理模式
- 静态代理
- 动态代理
- JDK动态代理
- cglib动态代理
- spring aop
- 策略模式
- SpringAOP策略模式的运用
- 生产者消费者模式
- 迭代器模式
- 函数式编程
- 方法引用
- 性能问题
- Lambda
- Lambda类型检查
- Stream
- findFirst和findAny
- reduce
- 原始类型流特化
- 无限流
- 收集器
- 并行流
- AOP
- 静态织入
- aspect
- aspect的定义
- AspectJ与SpringAOP
- 动态织入
- 静态代理
- 动态代理
- JDK动态代理
- CGLib动态代理
- Spring AOP
- SpringAOP五种通知类型
- @Before
- @AfterReturning
- @AfterThrowing
- @After
- @Around
- Aspect优先级
- SpringAOP切点表达式
- within
- execution
- 嵌套调用
- 系统优化与重构
- 重叠构造器模式
- 工具类构造器优化
- 常见面试题
- new Object()到底占用几个字节
- 访问修饰符
- cloneable接口实现原理
- 异常分类以及处理机制
- wait和sleep的区别
- 数组在内存中如何分配
- 类加载为什么要使用双亲委派模式,有没有什么场景是打破了这个模式
- 类的实例化顺序
- 附录
- JAVA术语
- FAQ
- 墨菲定律
- 康威定律
- 软件设计原则
- 阿姆达尔定律
- 字节码工具
- OSGI