* 如何解决缓存雪崩?
* 如何解决缓存穿透?
* 如何保证缓存与数据库双写时一致的问题?
# 一、缓存雪崩
## 1.1什么是缓存雪崩?
回顾一下我们为什么要用缓存(Redis):
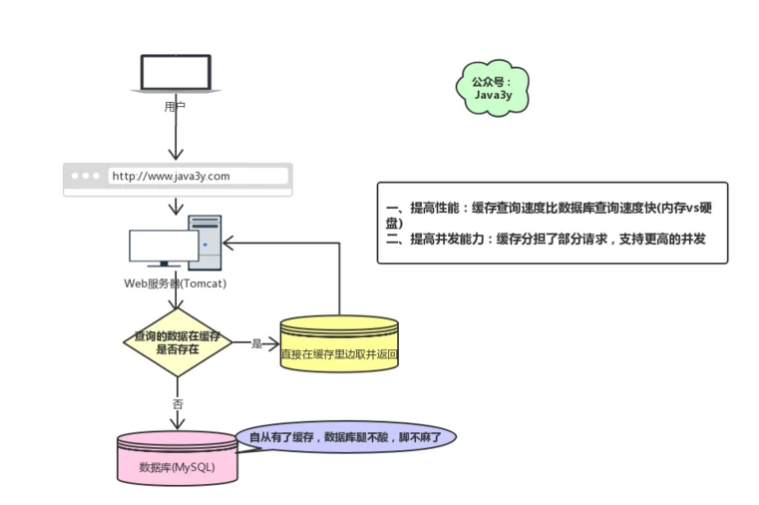](images/screenshot_1628844092011.png)
现在有个问题,**如果我们的缓存挂掉了,这意味着我们的全部请求都跑去数据库了**。
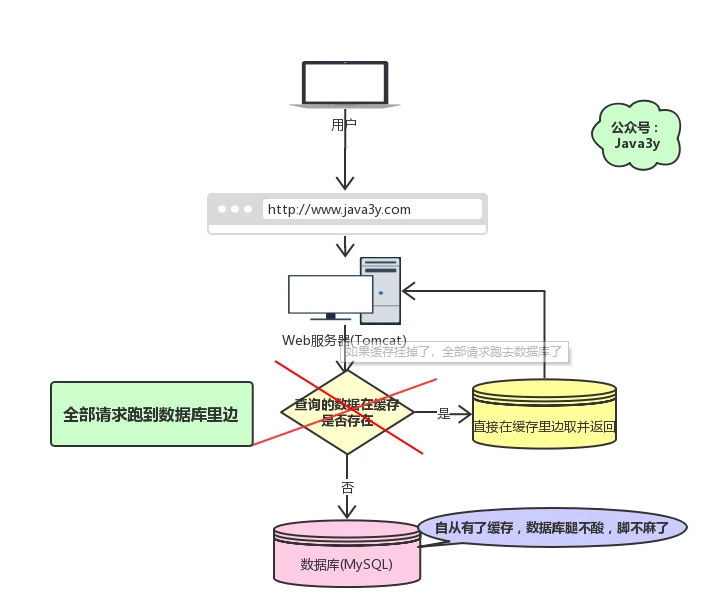](images/screenshot_1628844112093.png)
在前面学习我们都知道Redis不可能把所有的数据都缓存起来(**内存昂贵且有限**),所以Redis需要对数据设置过期时间,并采用的是惰性删除+定期删除两种策略对过期键删除。[Redis对过期键的策略+持久化](https://link.segmentfault.com/?url=https%3A%2F%2Fmp.weixin.qq.com%2Fs%3F__biz%3DMzI4Njg5MDA5NA%3D%3D%26amp%3Bmid%3D2247484386%26amp%3Bidx%3D1%26amp%3Bsn%3D323ddc84dc851a975530090fcd6e2326%26amp%3Bchksm%3Debd742e3dca0cbf52bc65d430447e639d81cc13e0ac34613edf464dae3950b10e2e1df74dcc5%26amp%3Btoken%3D1834317504%26amp%3Blang%3Dzh_CN%23rd)
如果缓存数据**设置的过期时间是相同**的,并且Redis恰好将这部分数据全部删光了。这就会导致在这段时间内,这些缓存**同时失效**,全部请求到数据库中。
**这就是缓存雪崩**:
* Redis挂掉了,请求全部走数据库。
* 对缓存数据设置相同的过期时间,导致某段时间内缓存失效,请求全部走数据库。
缓存雪崩如果发生了,很可能就把我们的数据库**搞垮**,导致整个服务瘫痪!
## 1.2如何解决缓存雪崩?
对于“对缓存数据设置相同的过期时间,导致某段时间内缓存失效,请求全部走数据库。”这种情况,非常好解决:
* 解决方法:在缓存的时候给过期时间加上一个**随机值**,这样就会大幅度的**减少缓存在同一时间过期**。
对于“Redis挂掉了,请求全部走数据库”这种情况,我们可以有以下的思路:
* 事发前:实现Redis的**高可用**(主从架构+Sentinel 或者Redis Cluster),尽量避免Redis挂掉这种情况发生。
* 事发中:万一Redis真的挂了,我们可以设置**本地缓存(ehcache)+限流(hystrix)**,尽量避免我们的数据库被干掉(起码能保证我们的服务还是能正常工作的)
* 事发后:redis持久化,重启后自动从磁盘上加载数据,**快速恢复缓存数据**。
# 二、缓存穿透
## 2.1什么是缓存穿透
比如,我们有一张数据库表,ID都是(**正数**):
但是可能有黑客想把我的数据库搞垮,每次请求的ID都是**负数**。这会导致我的缓存就没用了,请求全部都找数据库去了,但数据库也没有这个值啊,所以每次都返回空出去。
> 缓存穿透是指查询一个一定**不存在的数据**。由于缓存不命中,并且出于容错考虑,如果从**数据库查不到数据则不写入缓存**,这将导致这个不存在的数据**每次请求都要到数据库去查询**,失去了缓存的意义。
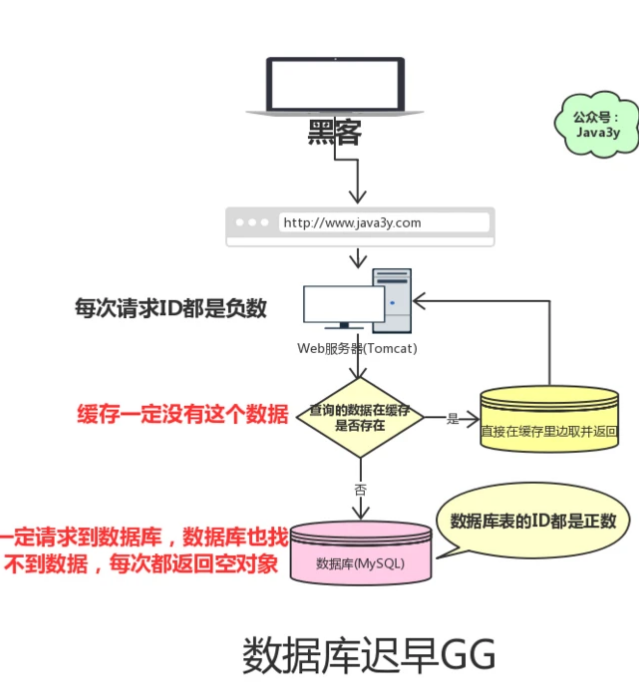
**这就是缓存穿透**:
* 请求的数据在缓存大量不命中,导致请求走数据库。
缓存穿透如果发生了,也可能把我们的数据库**搞垮**,导致整个服务瘫痪!
## 2.1如何解决缓存穿透?
解决缓存穿透也有两种方案:
* 由于请求的参数是不合法的(每次都请求不存在的参数),于是我们可以使用布隆过滤器(BloomFilter)或者压缩filter**提前拦截**,不合法就不让这个请求到数据库层!
* 当我们从数据库找不到的时候,我们也将这个**空对象设置到缓存里边去**。下次再请求的时候,就可以从缓存里边获取了。
* 这种情况我们一般会将空对象设置一个**较短的过期时间**。
参考资料:
* 缓存系列文章--缓存穿透问题
* [https://carlosfu.iteye.com/blog/2248185](https://link.segmentfault.com/?url=https%3A%2F%2Fcarlosfu.iteye.com%2Fblog%2F2248185)
# 三、缓存与数据库双写一致
## 3.1对于读操作,流程是这样的
上面讲缓存穿透的时候也提到了:如果从数据库查不到数据则不写入缓存。
一般我们对**读操作**的时候有这么一个**固定的套路**:
* 如果我们的数据在缓存里边有,那么就直接取缓存的。
* 如果缓存里没有我们想要的数据,我们会先去查询数据库,然后**将数据库查出来的数据写到缓存中**。
* 最后将数据返回给请求
## 3.2什么是缓存与数据库双写一致问题?
如果仅仅查询的话,缓存的数据和数据库的数据是没问题的。但是,当我们要**更新**时候呢?各种情况很可能就**造成数据库和缓存的数据不一致**了。
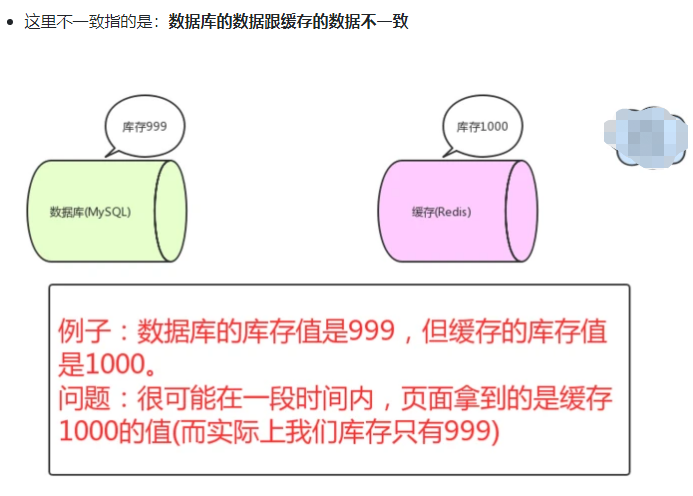
从理论上说,只要我们设置了**键的过期时间**,我们就能保证缓存和数据库的数据**最终是一致**的。因为只要缓存数据过期了,就会被删除。随后读的时候,因为缓存里没有,就可以查数据库的数据,然后将数据库查出来的数据写入到缓存中。
除了设置过期时间,我们还需要做更多的措施来**尽量避免**数据库与缓存处于不一致的情况发生。
## 3.3对于更新操作
一般来说,执行更新操作时,我们会有两种选择:
* 先操作数据库,再操作缓存
* 先操作缓存,再操作数据库
首先,要明确的是,无论我们选择哪个,我们都希望这**两个操作要么同时成功,要么同时失败**。所以,这会演变成一个**分布式事务**的问题。
所以,**如果原子性被破坏了**,可能会有以下的情况:
* **操作数据库成功了,操作缓存失败了**。
* **操作缓存成功了,操作数据库失败了**。
> 如果第一步已经失败了,我们直接返回Exception出去就好了,第二步根本不会执行。
下面我们具体来分析一下吧。
### 3.3.1操作缓存
操作缓存也有两种方案:
* 更新缓存
* 删除缓存
一般我们都是采取**删除缓存**缓存策略的,原因如下:
1. 高并发环境下,无论是先操作数据库还是后操作数据库而言,如果加上更新缓存,那就**更加容易**导致数据库与缓存数据不一致问题。(删除缓存**直接和简单**很多)
2. 如果每次更新了数据库,都要更新缓存【这里指的是频繁更新的场景,这会耗费一定的性能】,倒不如直接删除掉。等再次读取时,缓存里没有,那我到数据库找,在数据库找到再写到缓存里边(体现**懒加载**)
基于这两点,对于缓存在更新时而言,都是建议执行**删除**操作!
### 3.3.2先更新数据库,再删除缓存
正常的情况是这样的:
* 先操作数据库,成功;
* 再删除缓存,也成功;
如果原子性被破坏了:
* 第一步成功(操作数据库),第二步失败(删除缓存),会导致**数据库里是新数据,而缓存里是旧数据**。
* 如果第一步(操作数据库)就失败了,我们可以直接返回错误(Exception),不会出现数据不一致。
如果在高并发的场景下,出现数据库与缓存数据不一致的**概率特别低**,也不是没有:
* 缓存**刚好**失效
* 线程A查询数据库,得一个旧值
* 线程B将新值写入数据库
* 线程B删除缓存
* 线程A将查到的旧值写入缓存
要达成上述情况,还是说一句**概率特别低**:
> 因为这个条件需要发生在读缓存时缓存失效,而且并发着有一个写操作。而实际上数据库的写操作会比读操作慢得多,而且还要锁表,**而读操作必需在写操作前进入数据库操作,而又要晚于写操作更新缓存**,所有的这些条件都具备的概率基本并不大。
对于这种策略,其实是一种设计模式:`Cache Aside Pattern`
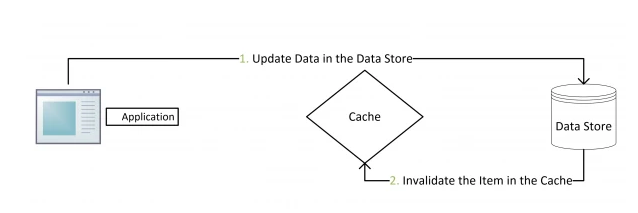
**删除缓存失败的解决思路**:
* 将需要删除的key发送到消息队列中
* 自己消费消息,获得需要删除的key
* **不断重试删除操作,直到成功**
### 3.3.3先删除缓存,再更新数据库
正常情况是这样的:
* 先删除缓存,成功;
* 再更新数据库,也成功;
如果原子性被破坏了:
* 第一步成功(删除缓存),第二步失败(更新数据库),数据库和缓存的数据还是一致的。
* 如果第一步(删除缓存)就失败了,我们可以直接返回错误(Exception),数据库和缓存的数据还是一致的。
看起来是很美好,但是我们在并发场景下分析一下,就知道还是有问题的了:
* 线程A删除了缓存
* 线程B查询,发现缓存已不存在
* 线程B去数据库查询得到旧值
* 线程B将旧值写入缓存
* 线程A将新值写入数据库
所以也会导致数据库和缓存不一致的问题。
**并发下解决数据库与缓存不一致的思路**:
* 将删除缓存、修改数据库、读取缓存等的操作积压到**队列**里边,实现**串行化**。

## 3.4对比两种策略
我们可以发现,两种策略各自有优缺点:
* 先删除缓存,再更新数据库
* 在高并发下表现不如意,在原子性被破坏时表现优异
* 先更新数据库,再删除缓存(`Cache Aside Pattern`设计模式)
* 在高并发下表现优异,在原子性被破坏时表现不如意
## 3.5其他保障数据一致的方案与资料
可以用**databus**或者阿里的**canal监听binlog**进行更新。
参考资料:
* 缓存更新的套路
* [https://coolshell.cn/articles/17416.html](https://link.segmentfault.com/?url=https%3A%2F%2Fcoolshell.cn%2Farticles%2F17416.html)
* 如何保证缓存与数据库双写时的数据一致性?
* [https://github.com/doocs/advanced-java/blob/master/docs/high-concurrency/redis-consistence.md](https://link.segmentfault.com/?url=https%3A%2F%2Fgithub.com%2Fdoocs%2Fadvanced-java%2Fblob%2Fmaster%2Fdocs%2Fhigh-concurrency%2Fredis-consistence.md)
* 分布式之数据库和缓存双写一致性方案解析
* [https://zhuanlan.zhihu.com/p/48334686](https://link.segmentfault.com/?url=https%3A%2F%2Fzhuanlan.zhihu.com%2Fp%2F48334686)
* Cache Aside Pattern
* [https://blog.csdn.net/z50l2o08e2u4aftor9a/article/details/81008933](https://link.segmentfault.com/?url=https%3A%2F%2Fblog.csdn.net%2Fz50l2o08e2u4aftor9a%2Farticle%2Fdetails%2F81008933)
- 文档说明
- 开始
- linux
- 常用命令
- ps -ef
- lsof
- netstat
- 解压缩
- 复制
- 权限
- 其他
- lnmp集成安装
- supervisor
- 安装
- supervisor进程管理
- nginx
- 域名映射
- 负载均衡配置
- lnmp集成环境安装
- nginx源码安装
- location匹配
- 限流配置
- 日志配置
- 重定向配置
- 压缩策略
- nginx 正/反向代理
- HTTPS配置
- mysql
- navicat创建索引
- 设置外网链接mysql
- navicat破解
- sql语句学习
- 新建mysql用户并赋予权限
- php
- opcache
- 设计模式
- 在CentOS下安装crontab服务
- composer
- 基础
- 常用的包
- guzzle
- 二维码
- 公共方法
- 敏感词过滤
- IP访问频次限制
- CURL
- 支付
- 常用递归
- 数据排序
- 图片相关操作
- 权重分配
- 毫秒时间戳
- base64<=>图片
- 身份证号分析
- 手机号相关操作
- 项目搭建 公共处理函数
- JWT
- 系统函数
- json_encode / json_decode 相关
- 数字计算
- 数组排序
- php8
- jit特性
- php8源码编译安装
- laravel框架
- 常用artisan命令
- 常用查询
- 模型关联
- 创建公共方法
- 图片上传
- 中间件
- 路由配置
- jwt
- 队列
- 定时任务
- 日志模块
- laravel+swoole基本使用
- 拓展库
- 请求接口log
- laravel_octane
- 微信开发
- token配置验证
- easywechart 获取用户信息
- 三方包
- webman
- win下热更新代码
- 使用laravel db listen 监听sql语句
- guzzle
- 使用workman的httpCLient
- 修改队列后代码不生效
- workman
- 安装与使用
- websocket
- eleticsearch
- php-es 安装配置
- hyperf
- 热更新
- 安装报错
- swoole
- 安装
- win安装swoole-cli
- google登录
- golang
- 文档地址
- 标准库
- time
- 数据类型
- 基本数据类型
- 复合数据类型
- 协程&管道
- 协程基本使用
- 读写锁 RWMutex
- 互斥锁Mutex
- 管道的基本使用
- 管道select多路复用
- 协程加管道
- beego
- gin
- 安装
- 热更新
- 路由
- 中间件
- 控制器
- 模型
- 配置文件/conf
- gorm
- 初始化
- 控制器 模型查询封装
- 添加
- 修改
- 删除
- 联表查询
- 环境搭建
- Windows
- linux
- 全局异常捕捉
- javascript
- 常用函数
- vue
- vue-cli
- 生产环境 开发环境配置
- 组件通信
- 组件之间通信
- 父传子
- 子传父
- provide->inject (非父子)
- 引用元素和组件
- vue-原始写法
- template基本用法
- vue3+ts项目搭建
- vue3引入element-plus
- axios 封装网络请求
- computed 计算属性
- watch 监听
- 使用@符 代替文件引入路径
- vue开发中常用的插件
- vue 富文本编辑
- nuxt
- 学习笔记
- 新建项目踩坑整理
- css
- flex布局
- flex PC端基本布局
- flex 移动端基本布局
- 常用css属性
- 盒子模型与定位
- 小说分屏显示
- git
- 基本命令
- fetch
- 常用命令
- 每次都需要验证
- git pull 有冲突时
- .gitignore 修改后不生效
- 原理解析
- tcp与udp详解
- TCP三次握手四次挥手
- 缓存雪崩 穿透 更新详解
- 内存泄漏-内存溢出
- php_fpm fast_cgi cig
- redis
- 相关三方文章
- API对外接口文档示范
- elaticsearch
- 全文检索
- 简介
- 安装
- kibana
- 核心概念 索引 映射 文档
- 高级查询 Query DSL
- 索引原理
- 分词器
- 过滤查询
- 聚合查询
- 整合应用
- 集群
- docker
- docker 简介
- docker 安装
- docker 常用命令
- image 镜像命令
- Contrainer 容器命令
- docker-compose
- redis 相关
- 客户端安装
- Linux 环境下安装
- uni
- http请求封装
- ios打包
- 视频纵向播放
- 日记
- 工作日记
- 情感日志
- 压测
- ab
- ui
- thorui
- 开发规范
- 前端
- 后端
- 状态码
- 开发小组未来规划