## Compile
`compile` 编译可以分成 `parse`、`optimize` 与 `generate` 三个阶段,最终需要得到 render function。这部分内容不算 Vue.js 的响应式核心,只是用来编译的,笔者认为在精力有限的情况下不需要追究其全部的实现细节,能够把握如何解析的大致流程即可。

由于解析过程比较复杂,直接上代码可能会导致不了解这部分内容的同学一头雾水。所以笔者准备提供一个 template 的示例,通过这个示例的变化来看解析的过程。但是解析的过程及结果都是将最重要的部分抽离出来展示,希望能让读者更好地了解其核心部分的实现。
```
<div :class="c" class="demo" v-if="isShow">
<span v-for="item in sz">{{item}}</span>
</div>
```
```
var html = '<div :class="c" class="demo" v-if="isShow"><span v-for="item in sz">{{item}}</span></div>';
```
接下来的过程都会依赖这个示例来进行。
## parse
首先是 `parse`,`parse` 会用正则等方式将 template 模板中进行字符串解析,得到指令、class、style等数据,形成 AST([在计算机科学中,抽象语法树(abstract syntax tree或者缩写为AST),或者语法树(syntax tree),是源代码的抽象语法结构的树状表现形式,这里特指编程语言的源代码。](https://zh.wikipedia.org/wiki/%E6%8A%BD%E8%B1%A1%E8%AA%9E%E6%B3%95%E6%A8%B9))。
这个过程比较复杂,会涉及到比较多的正则进行字符串解析,我们来看一下得到的 AST 的样子。
```
{
/* 标签属性的map,记录了标签上属性 */
'attrsMap': {
':class': 'c',
'class': 'demo',
'v-if': 'isShow'
},
/* 解析得到的:class */
'classBinding': 'c',
/* 标签属性v-if */
'if': 'isShow',
/* v-if的条件 */
'ifConditions': [
{
'exp': 'isShow'
}
],
/* 标签属性class */
'staticClass': 'demo',
/* 标签的tag */
'tag': 'div',
/* 子标签数组 */
'children': [
{
'attrsMap': {
'v-for': "item in sz"
},
/* for循环的参数 */
'alias': "item",
/* for循环的对象 */
'for': 'sz',
/* for循环是否已经被处理的标记位 */
'forProcessed': true,
'tag': 'span',
'children': [
{
/* 表达式,_s是一个转字符串的函数 */
'expression': '_s(item)',
'text': '{{item}}'
}
]
}
]
}
```
最终得到的 AST 通过一些特定的属性,能够比较清晰地描述出标签的属性以及依赖关系。
接下来我们用代码来讲解一下如何使用正则来把 template 编译成我们需要的 AST 的。
### 正则
首先我们定义一下接下来我们会用到的正则。
```
const ncname = '[a-zA-Z_][\\w\\-\\.]*';
const singleAttrIdentifier = /([^\s"'<>/=]+)/
const singleAttrAssign = /(?:=)/
const singleAttrValues = [
/"([^"]*)"+/.source,
/'([^']*)'+/.source,
/([^\s"'=<>`]+)/.source
]
const attribute = new RegExp(
'^\\s*' + singleAttrIdentifier.source +
'(?:\\s*(' + singleAttrAssign.source + ')' +
'\\s*(?:' + singleAttrValues.join('|') + '))?'
)
const qnameCapture = '((?:' + ncname + '\\:)?' + ncname + ')'
const startTagOpen = new RegExp('^<' + qnameCapture)
const startTagClose = /^\s*(\/?)>/
const endTag = new RegExp('^<\\/' + qnameCapture + '[^>]*>')
const defaultTagRE = /\{\{((?:.|\n)+?)\}\}/g
const forAliasRE = /(.*?)\s+(?:in|of)\s+(.*)/
```
## advance
因为我们解析 template 采用循环进行字符串匹配的方式,所以每匹配解析完一段我们需要将已经匹配掉的去掉,头部的指针指向接下来需要匹配的部分。
```
function advance (n) {
index += n
html = html.substring(n)
}
```
举个例子,当我们把第一个 div 的头标签全部匹配完毕以后,我们需要将这部分除去,也就是向右移动 43 个字符。

调用 `advance` 函数
```
advance(43);
```
得到结果

### parseHTML
首先我们需要定义个 `parseHTML` 函数,在里面我们循环解析 template 字符串。
```
function parseHTML () {
while(html) {
let textEnd = html.indexOf('<');
if (textEnd === 0) {
if (html.match(endTag)) {
//...process end tag
continue;
}
if (html.match(startTagOpen)) {
//...process start tag
continue;
}
} else {
//...process text
continue;
}
}
}
```
`parseHTML` 会用 `while` 来循环解析 template ,用正则在匹配到标签头、标签尾以及文本的时候分别进行不同的处理。直到整个 template 被解析完毕。
### parseStartTag
我们来写一个 `parseStartTag` 函数,用来解析起始标签("<div :class="c" class="demo" v-if="isShow">"部分的内容)。
```
function parseStartTag () {
const start = html.match(startTagOpen);
if (start) {
const match = {
tagName: start[1],
attrs: [],
start: index
}
advance(start[0].length);
let end, attr
while (!(end = html.match(startTagClose)) && (attr = html.match(attribute))) {
advance(attr[0].length)
match.attrs.push({
name: attr[1],
value: attr[3]
});
}
if (end) {
match.unarySlash = end[1];
advance(end[0].length);
match.end = index;
return match
}
}
}
```
首先用 `startTagOpen` 正则得到标签的头部,可以得到 `tagName`(标签名称),同时我们需要一个数组 `attrs` 用来存放标签内的属性。
```
const start = html.match(startTagOpen);
const match = {
tagName: start[1],
attrs: [],
start: index
}
advance(start[0].length);
```
接下来使用 `startTagClose` 与 `attribute` 两个正则分别用来解析标签结束以及标签内的属性。这段代码用 `while` 循环一直到匹配到 `startTagClose` 为止,解析内部所有的属性。
```
let end, attr
while (!(end = html.match(startTagClose)) && (attr = html.match(attribute))) {
advance(attr[0].length)
match.attrs.push({
name: attr[1],
value: attr[3]
});
}
if (end) {
match.unarySlash = end[1];
advance(end[0].length);
match.end = index;
return match
}
```
## stack
此外,我们需要维护一个 **stack** 栈来保存已经解析好的标签头,这样我们可以根据在解析尾部标签的时候得到所属的层级关系以及父标签。同时我们定义一个 `currentParent` 变量用来存放当前标签的父标签节点的引用, `root` 变量用来指向根标签节点。
```
const stack = [];
let currentParent, root;
```
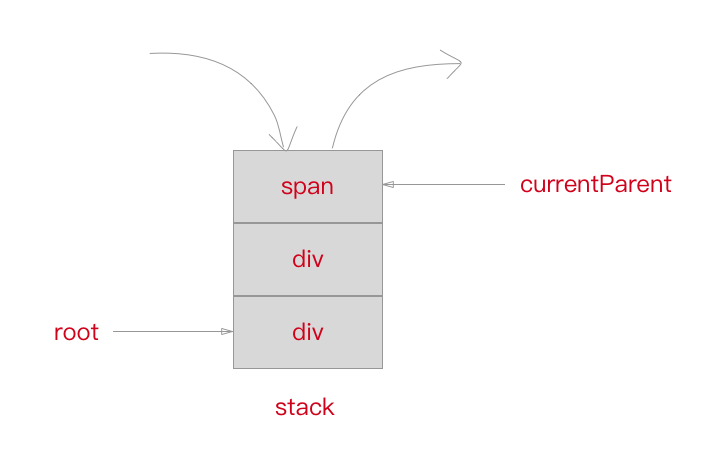
知道这个以后,我们优化一下 `parseHTML` ,在 `startTagOpen` 的 `if` 逻辑中加上新的处理。
```
if (html.match(startTagOpen)) {
const startTagMatch = parseStartTag();
const element = {
type: 1,
tag: startTagMatch.tagName,
lowerCasedTag: startTagMatch.tagName.toLowerCase(),
attrsList: startTagMatch.attrs,
attrsMap: makeAttrsMap(startTagMatch.attrs),
parent: currentParent,
children: []
}
if(!root){
root = element
}
if(currentParent){
currentParent.children.push(element);
}
stack.push(element);
currentParent = element;
continue;
}
```
我们将 `startTagMatch` 得到的结果首先封装成 `element` ,这个就是最终形成的 AST 的节点,标签节点的 type 为 1。
```
const startTagMatch = parseStartTag();
const element = {
type: 1,
tag: startTagMatch.tagName,
attrsList: startTagMatch.attrs,
attrsMap: makeAttrsMap(startTagMatch.attrs),
parent: currentParent,
children: []
}
```
然后让 `root` 指向根节点的引用。
```
if(!root){
root = element
}
```
接着我们将当前节点的 `element` 放入父节点 `currentParent` 的 `children` 数组中。
```
if(currentParent){
currentParent.children.push(element);
}
```
最后将当前节点 `element` 压入 stack 栈中,并将 `currentParent` 指向当前节点,因为接下去下一个解析如果还是头标签或者是文本的话,会成为当前节点的子节点,如果是尾标签的话,那么将会从栈中取出当前节点,这种情况我们接下来要讲。
```
stack.push(element);
currentParent = element;
continue;
```
其中的 `makeAttrsMap` 是将 attrs 转换成 map 格式的一个方法。
```
function makeAttrsMap (attrs) {
const map = {}
for (let i = 0, l = attrs.length; i < l; i++) {
map[attrs[i].name] = attrs[i].value;
}
return map
}
```
### parseEndTag
同样,我们在 `parseHTML` 中加入对尾标签的解析函数,为了匹配如“</div>”。
```
const endTagMatch = html.match(endTag)
if (endTagMatch) {
advance(endTagMatch[0].length);
parseEndTag(endTagMatch[1]);
continue;
}
```
用 `parseEndTag` 来解析尾标签,它会从 stack 栈中取出最近的跟自己标签名一致的那个元素,将 `currentParent` 指向那个元素,并将该元素之前的元素都从 stack 中出栈。
这里可能有同学会问,难道解析的尾元素不应该对应 stack 栈的最上面的一个元素才对吗?
其实不然,比如说可能会存在自闭合的标签,如“<br />”,或者是写了“<span>”但是没有加上“< /span>”的情况,这时候就要找到 stack 中的第二个位置才能找到同名标签。
```
function parseEndTag (tagName) {
let pos;
for (pos = stack.length - 1; pos >= 0; pos--) {
if (stack[pos].lowerCasedTag === tagName.toLowerCase()) {
break;
}
}
if (pos >= 0) {
stack.length = pos;
currentParent = stack[pos];
}
}
```
### parseText
最后是解析文本,这个比较简单,只需要将文本取出,然后有两种情况,一种是普通的文本,直接构建一个节点 push 进当前 `currentParent` 的 children 中即可。还有一种情况是文本是如“{{item}}”这样的 Vue.js 的表达式,这时候我们需要用 `parseText` 来将表达式转化成代码。
```
text = html.substring(0, textEnd)
advance(textEnd)
let expression;
if (expression = parseText(text)) {
currentParent.children.push({
type: 2,
text,
expression
});
} else {
currentParent.children.push({
type: 3,
text,
});
}
continue;
```
我们会用到一个 `parseText` 函数。
```
function parseText (text) {
if (!defaultTagRE.test(text)) return;
const tokens = [];
let lastIndex = defaultTagRE.lastIndex = 0
let match, index
while ((match = defaultTagRE.exec(text))) {
index = match.index
if (index > lastIndex) {
tokens.push(JSON.stringify(text.slice(lastIndex, index)))
}
const exp = match[1].trim()
tokens.push(`_s(${exp})`)
lastIndex = index + match[0].length
}
if (lastIndex < text.length) {
tokens.push(JSON.stringify(text.slice(lastIndex)))
}
return tokens.join('+');
}
```
我们使用一个 `tokens` 数组来存放解析结果,通过 `defaultTagRE` 来循环匹配该文本,如果是普通文本直接 `push` 到 `tokens` 数组中去,如果是表达式({{item}}),则转化成“\_s(${exp})”的形式。
举个例子,如果我们有这样一个文本。
```
<div>hello,{{name}}.</div>
```
最终得到 `tokens`。
```
tokens = ['hello,', _s(name), '.'];
```
最终通过 `join` 返回表达式。
```
'hello' + _s(name) + '.';
```
### processIf与processFor
最后介绍一下如何处理“`v-if`”以及“`v-for`”这样的 Vue.js 的表达式的,这里我们只简单介绍两个示例中用到的表达式解析。
我们只需要在解析头标签的内容中加入这两个表达式的解析函数即可,在这时“`v-for`”之类指令已经在属性解析时存入了 `attrsMap` 中了。
```
if (html.match(startTagOpen)) {
const startTagMatch = parseStartTag();
const element = {
type: 1,
tag: startTagMatch.tagName,
attrsList: startTagMatch.attrs,
attrsMap: makeAttrsMap(startTagMatch.attrs),
parent: currentParent,
children: []
}
processIf(element);
processFor(element);
if(!root){
root = element
}
if(currentParent){
currentParent.children.push(element);
}
stack.push(element);
currentParent = element;
continue;
}
```
首先我们需要定义一个 `getAndRemoveAttr` 函数,用来从 `el` 的 `attrsMap` 属性或是 `attrsList` 属性中取出 `name` 对应值。
```
function getAndRemoveAttr (el, name) {
let val
if ((val = el.attrsMap[name]) != null) {
const list = el.attrsList
for (let i = 0, l = list.length; i < l; i++) {
if (list[i].name === name) {
list.splice(i, 1)
break
}
}
}
return val
}
```
比如说解析示例的 div 标签属性。
```
getAndRemoveAttr(el, 'v-for');
```
可有得到“item in sz”。
有了这个函数这样我们就可以开始实现 `processFor` 与 `processIf` 了。
“v-for”会将指令解析成 `for` 属性以及 `alias` 属性,而“v-if”会将条件都存入 `ifConditions` 数组中。
```
function processFor (el) {
let exp;
if ((exp = getAndRemoveAttr(el, 'v-for'))) {
const inMatch = exp.match(forAliasRE);
el.for = inMatch[2].trim();
el.alias = inMatch[1].trim();
}
}
function processIf (el) {
const exp = getAndRemoveAttr(el, 'v-if');
if (exp) {
el.if = exp;
if (!el.ifConditions) {
el.ifConditions = [];
}
el.ifConditions.push({
exp: exp,
block: el
});
}
}
```
到这里,我们已经把 `parse` 的过程介绍完了,接下来看一下 `optimize`。
## optimize
`optimize` 主要作用就跟它的名字一样,用作「优化」。
这个涉及到后面要讲 `patch` 的过程,因为 `patch` 的过程实际上是将 VNode 节点进行一层一层的比对,然后将「差异」更新到视图上。那么一些静态节点是不会根据数据变化而产生变化的,这些节点我们没有比对的需求,是不是可以跳过这些静态节点的比对,从而节省一些性能呢?
那么我们就需要为静态的节点做上一些「标记」,在 `patch` 的时候我们就可以直接跳过这些被标记的节点的比对,从而达到「优化」的目的。
经过 `optimize` 这层的处理,每个节点会加上 `static` 属性,用来标记是否是静态的。
得到如下结果。
```
{
'attrsMap': {
':class': 'c',
'class': 'demo',
'v-if': 'isShow'
},
'classBinding': 'c',
'if': 'isShow',
'ifConditions': [
'exp': 'isShow'
],
'staticClass': 'demo',
'tag': 'div',
/* 静态标志 */
'static': false,
'children': [
{
'attrsMap': {
'v-for': "item in sz"
},
'static': false,
'alias': "item",
'for': 'sz',
'forProcessed': true,
'tag': 'span',
'children': [
{
'expression': '_s(item)',
'text': '{{item}}',
'static': false
}
]
}
]
}
```
我们用代码实现一下 `optimize` 函数。
### isStatic
首先实现一个 `isStatic` 函数,传入一个 node 判断该 node 是否是静态节点。判断的标准是当 type 为 2(表达式节点)则是非静态节点,当 type 为 3(文本节点)的时候则是静态节点,当然,如果存在 `if` 或者 `for`这样的条件的时候(表达式节点),也是非静态节点。
```
function isStatic (node) {
if (node.type === 2) {
return false
}
if (node.type === 3) {
return true
}
return (!node.if && !node.for);
}
```
### markStatic
`markStatic` 为所有的节点标记上 `static`,遍历所有节点通过 `isStatic` 来判断当前节点是否是静态节点,此外,会遍历当前节点的所有子节点,如果子节点是非静态节点,那么当前节点也是非静态节点。
```
function markStatic (node) {
node.static = isStatic(node);
if (node.type === 1) {
for (let i = 0, l = node.children.length; i < l; i++) {
const child = node.children[i];
markStatic(child);
if (!child.static) {
node.static = false;
}
}
}
}
```
### markStaticRoots
接下来是 `markStaticRoots` 函数,用来标记 `staticRoot`(静态根)。这个函数实现比较简单,简单来将就是如果当前节点是静态节点,同时满足该节点并不是只有一个文本节点左右子节点(作者认为这种情况的优化消耗会大于收益)时,标记 `staticRoot` 为 true,否则为 false。
```
function markStaticRoots (node) {
if (node.type === 1) {
if (node.static && node.children.length && !(
node.children.length === 1 &&
node.children[0].type === 3
)) {
node.staticRoot = true;
return;
} else {
node.staticRoot = false;
}
}
}
```
### optimize
有了以上的函数,就可以实现 `optimize` 了。
```
function optimize (rootAst) {
markStatic(rootAst);
markStaticRoots(rootAst);
}
```
## generate
`generate` 会将 AST 转化成 render funtion 字符串,最终得到 render 的字符串以及 staticRenderFns 字符串。
首先带大家感受一下真实的 Vue.js 编译得到的结果。
```
with(this){
return (isShow) ?
_c(
'div',
{
staticClass: "demo",
class: c
},
_l(
(sz),
function(item){
return _c('span',[_v(_s(item))])
}
)
)
: _e()
}
```
看到这里可能会纳闷了,这些 `_c`,`_l` 到底是什么?其实他们是 Vue.js 对一些函数的简写,比如说 `_c` 对应的是 `createElement` 这个函数。没关系,我们把它用 VNode 的形式写出来就会明白了,这个对接上一章写的 VNode 函数。
首先是第一层 div 节点。
```
render () {
return isShow ? (new VNode('div', {
'staticClass': 'demo',
'class': c
}, [ /*这里还有子节点*/ ])) : createEmptyVNode();
}
```
然后我们在 `children` 中加上第二层 span 及其子文本节点节点。
```
/* 渲染v-for列表 */
function renderList (val, render) {
let ret = new Array(val.length);
for (i = 0, l = val.length; i < l; i++) {
ret[i] = render(val[i], i);
}
}
render () {
return isShow ? (new VNode('div', {
'staticClass': 'demo',
'class': c
},
/* begin */
renderList(sz, (item) => {
return new VNode('span', {}, [
createTextVNode(item);
]);
})
/* end */
)) : createEmptyVNode();
}
```
那我们如何来实现一个 `generate` 呢?
### genIf
首先实现一个处理 `if` 条件的 `genIf` 函数。
```
function genIf (el) {
el.ifProcessed = true;
if (!el.ifConditions.length) {
return '_e()';
}
return `(${el.ifConditions[0].exp})?${genElement(el.ifConditions[0].block)}: _e()`
}
```
### genFor
然后是处理 `for` 循环的函数。
```
function genFor (el) {
el.forProcessed = true;
const exp = el.for;
const alias = el.alias;
const iterator1 = el.iterator1 ? `,${el.iterator1}` : '';
const iterator2 = el.iterator2 ? `,${el.iterator2}` : '';
return `_l((${exp}),` +
`function(${alias}${iterator1}${iterator2}){` +
`return ${genElement(el)}` +
'})';
}
```
### genText
处理文本节点的函数。
```
function genText (el) {
return `_v(${el.expression})`;
}
```
### genElement
接下来实现一下 `genElement`,这是一个处理节点的函数,因为它依赖 `genChildren` 以及g `enNode` ,所以这三个函数放在一起讲。
genElement会根据当前节点是否有 `if` 或者 `for` 标记然后判断是否要用 `genIf` 或者 `genFor` 处理,否则通过 `genChildren` 处理子节点,同时得到 `staticClass`、`class` 等属性。
`genChildren` 比较简单,遍历所有子节点,通过 `genNode` 处理后用“,”隔开拼接成字符串。
`genNode` 则是根据 `type` 来判断该节点是用文本节点 `genText` 还是标签节点 `genElement` 来处理。
```
function genNode (el) {
if (el.type === 1) {
return genElement(el);
} else {
return genText(el);
}
}
function genChildren (el) {
const children = el.children;
if (children && children.length > 0) {
return `${children.map(genNode).join(',')}`;
}
}
function genElement (el) {
if (el.if && !el.ifProcessed) {
return genIf(el);
} else if (el.for && !el.forProcessed) {
return genFor(el);
} else {
const children = genChildren(el);
let code;
code = `_c('${el.tag},'{
staticClass: ${el.attrsMap && el.attrsMap[':class']},
class: ${el.attrsMap && el.attrsMap['class']},
}${
children ? `,${children}` : ''
})`
return code;
}
}
```
### generate
最后我们使用上面的函数来实现 `generate`,其实很简单,我们只需要将整个 AST 传入后判断是否为空,为空则返回一个 div 标签,否则通过 `generate` 来处理。
```
function generate (rootAst) {
const code = rootAst ? genElement(rootAst) : '_c("div")'
return {
render: `with(this){return ${code}}`,
}
}
```
经历过这些过程以后,我们已经把 template 顺利转成了 render function 了,接下来我们将介绍 `patch` 的过程,来看一下具体 VNode 节点如何进行差异的比对。
注:本节代码参考[《template 模板是怎样通过 Compile 编译的》](https://github.com/answershuto/VueDemo/blob/master/%E3%80%8Atemplate%20%E6%A8%A1%E6%9D%BF%E6%98%AF%E6%80%8E%E6%A0%B7%E9%80%9A%E8%BF%87%20Compile%20%E7%BC%96%E8%AF%91%E7%9A%84%E3%80%8B.js)。
