
你好,我是蔡元楠,现在在 Google 主持研发机器学习在生物医疗领域中的产品应用。在此之前,也在 Google 的搜索广告部门、智能语音助手等部门参与核心系统的研发。

#### Google 洗手间里贴着的 B+ 树和哈希表
许多来 Google 参观的人,用完洗手间后,都会惊奇而略带羞涩地问:“你们马桶前面的门上,还贴着 B+ 树和哈希表的对比… 是用来搞笑的吗?我感觉数据结构只有在面试的时候会问,工作后从来不需要用数据结构的呀”。
这真不是搞笑,在不同的应用场景合理使用对的数据结构,在 Google 等大厂都是非常认真对待的。而事实上很多技术人,包括我遇到不少 Google 招聘的应届毕业生,对待数据结构还存在以下两大误区。
* 不懂底层原理:看了很多书,算法、架构设计等相关的资料,却始终没有搞懂底层数据结构的原理,很多开源软件拿来就用,简直是盲人摸象。
* 工作中不会用:很多开发者认为数据结构与算法只有在面试的时候用得到,甚至很多课程也仅仅停留在面试刷题的层面上。从而“面试造火箭、工作拧螺丝”成为了很多技术人的自嘲。
这两个误区又是紧密相连的,在实际工作中如果用不好数据结构将会给工作带来很大的影响,比如:
* 如果不知道数据结构背后的原理,就只能堆砌业务逻辑,从而导致的后果往往是把整个代码库搞得异常繁琐复杂且难以维护;
* 错误的使用数据结构,也会影响整个核心的用户体验,如延时太高、消耗资源过多等;
* 如果对数据结构没有进行深入的理解,那么也会限制一个技术人的职业成长和技术影响力,因为他的技术广度与深度无法胜任更关键的角色。
存在以上的问题主要是因为:(1)基础原理没有融会贯通,(2)实际工作中没有使用数据结构的场景,无法深入理解其核心原理,慢慢地数据结构原理知识也就忘了。
#### 不懂数据结构引发的血案
清楚记得刚开始工作时,我临危受命负责解决我们组的一个重大性能 Bug,当时影响了多个核心用户的体验。经过深入地排查后才发现,在一个关键 RPC 的代码逻辑中大量使用了一个自定义树,这个树的数据结构实现,正是这个系统的瓶颈。

首先这个树的实现极为繁琐,为整个系统的维护增加了复杂度;其次他的一些高频操作的代码实现都没有优化。比如,这个树的节点插入是用数组的插入实现的,这个树的遍历实现使用了 C++ 标准库的 std::vector 等。这个数据结构的改写把我们 RPC 的 90 分位延时从 800ms 优化到了 200ms 以下。
此时才意识到我之前学的都是“假”的数据结构,曾经对于数据结构的理解是多么浮于纸面。纸上得来终觉浅,只有和真正的应用场景相结合,才能深刻理解数据结构的原理和性能影响。

#### 专栏设计
上面的两个故事,正是我们设计这个数据结构专栏的初衷,即想要帮助解决很多技术人的两个误区:(1)不懂底层原理,(2)工作中不会用。用原理结合真实大厂案例和开源框架的方式,来加深你对于数据结构的理解和应用能力,学完后可以应用到具体的工作中。
现在的开源项目层出不穷,万变不离其宗的是底层的数据结构实现。可以说,这是一个做底层框架或者做架构设计的架构师非读不可的专栏,而做应用或业务层的软件工程师也应该细细品读,对于以后的代码逻辑提升有很好的帮助作用。
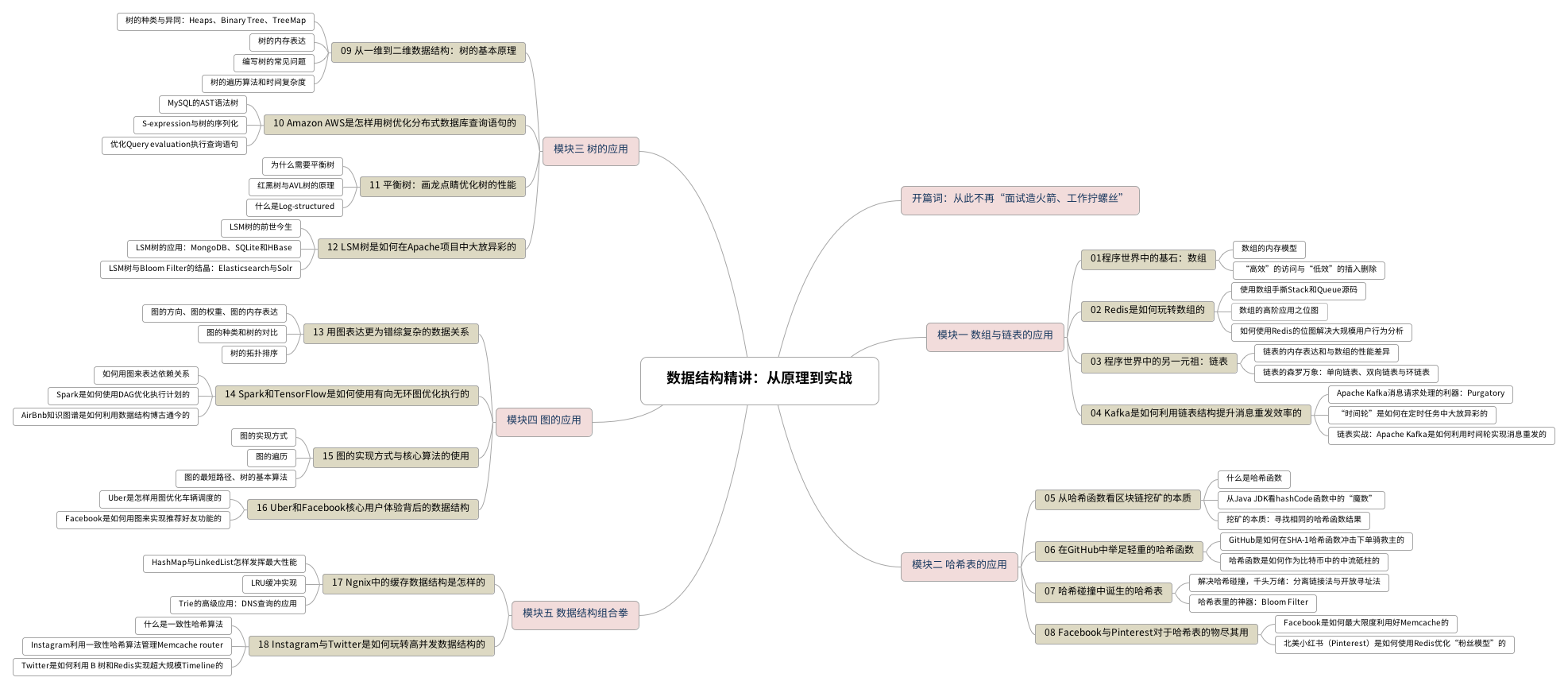
这个专栏共分为 5 大模块 18 讲。
* [ ] 模块一 数组与链表的应用
在模块一中我们会回顾时间复杂度和空间复杂度、深入数组和链表的内存结构,以及如何在 Redis 中使用 Bitmap 来替代常规 SQL 查询,以作为案例分析探讨数组在用户活跃度分析中的应用;接着也会研究 Kafka 是如何利用链表结构来提升消息重发效率的。
* [ ] 模块二 哈希表的应用
这个模块将会带你通过比特币挖矿的案例,来理解哈希函数和哈希碰撞的本质。紧接着会研究哈希表的各种实现,同时结合之前讲解的数组与链表,来分析哈希表是如何作为核心数据结构支撑起 Memcached 的,同时带你领略 Facebook 是如何利用 Memcached 支撑起百亿级用户请求的。
* [ ] 模块三 树的应用
在树的模块中,会先讲解树的结构化特性,同时比较各种树,比如堆、二叉树。接着总结在编写一个树的类型时需要注意的常见问题,会以 MySQL 语法树为例,看看树是如何在 Amazon AWS 超大型数据库查询起到中流砥柱的作用的。在这个模块的后半部分我们会把重心放在平衡树上,以及平衡树是如何成为如 Elastic Search、LevelDB 等众多存储系统的基石的。
* [ ] 模块四 图的应用
图也是在大厂应用非常广泛的数据结构之一。在这一模块中将会回顾有向图和无向图的基本概念、图的内存表达、比较图和树的区别,然后把重心放在应用最广泛的有向无环图上。我们以 Apache Spark 和 TensorFlow 为例,来看看有向无环图是如何优化大规模分布式运算的系统。之后也会以 Uber 的车辆调度算法再加上 Facebook 的 Newsfeed 功能,深入浅出的帮你掌握图是怎样实现这些硅谷一线大厂核心功能的。
* [ ] 模块五 数据结构组合拳
前面的模块我们主要分析单个数据是如何支撑一个大厂核心应用场景的,或者一个开源框架的核心功能。但是在实战中会经常需要融合使用多种数据结构去实现业务逻辑。数据结构组合拳这个模块就是为了帮助你掌握这些应用而设计的。会先详尽看 Nginx 中的缓存数据结构,如哈希表、链表、红黑树与 LRU 缓存。相信通过这个案例你能对这些数据结构的理解更进一步;接着会探索 Twitter 的高并发限流机制,涉及到各种并发数据结构,比如并发哈希表、RateLimiter 和消息队列。在这个模块结束后,相信以后在面对类似的应用场景时都能信手拈来,打出数据结构组合拳。
#### 讲师寄语
数据结构底层原理的速成捷径:我也曾经读过枯燥无味的数据结构教材,以及各种味同嚼蜡不得要义的论文,比如数据库设计论文、分布式系统论文等,当时很痛苦,但硬着头皮给啃下来了。
为了不让你再经历这些,和拉勾教育平台一起合作,历时半年精心打磨出了这个专栏,从 5+ 本数据结构教材、20+ 篇技术论文中,提炼出了真正在工程实践中应用到的关键核心原理,同时不乏深度。因为在 Google 亿级流量,超大规模技术系统的历练让我明白,数据结构的理解不是靠死记硬背的,一定要懂得为什么,不然在工作中很快就会忘掉。这个专栏将会告诉你数据结构为什么这么设计,从而也能根据应用场景来设计合适的数据结构。

真实大厂数据结构实战案例:将结合 8 个硅谷一线大厂的最佳实践,以及 15 个顶级开源软件的应用来解读数据结构在实战工程中如何应用,如何通过优化一个核心数据结构来达到优化整个系统的功能。搞清楚这些数据结构原理后,相信你也能拥有造轮子的能力,而不是只能借助其他人的开源框架了。
* 8 个硅谷一线大厂包括 Facebook、Instagram、GitHub、Amazon、Uber、Twitter、Airbnb 和 Pinterest。
* 15 个顶级开源软件包括 Redis、Kafka、MySQL、SQLite、 MongoDB、Spark、TensorFlow、Nginx、Memcached、LevelDB、RocksDB、HBase、Cassandra、Elastic Search 和 Solr。
马上就要开始正式内容的学习了,让我们一起以 Linux 之父 Linus Torvalds 的话共勉吧!Bad programmers worry about the code. Good programmers worry about data structures and their relationships.(低水平的程序员操心代码,高水平的程序员考虑数据结构和数据结构的联系。)
- 前言
- 开篇
- 开篇词:从此不再“面试造火箭、工作拧螺丝”
- 模块一:数组与链表的应用
- 第 01 讲:数组内存模型
- 第 02 讲:位图数组在 Redis 中的应用
- 第 03 讲:链表基础原理
- 第 04 讲:链表在 Apache Kafka 中的应用
- 模块二:哈希表的应用
- 第 05 讲:哈希函数的本质及生成方式
- 第 06 讲:哈希函数在 GitHub 和比特币中的应用
- 第 07 讲:哈希碰撞的本质及解决方式
- 第 08 讲:哈希表在 Facebook 和 Pinterest 中的应用
- 模块三:树的应用
- 第 09 讲:树的基本原理
- 第 10 讲:树在 Amazon 中的应用
- 第 11 讲:平衡树的性能优化
- 第 12 讲:LSM 树在 Apache HBase 等存储系统中的应用
- 模块四:图的应用
- 第 13 讲:用图来表达更为复杂的数据关系
- 第 14 讲:有向无环图在 Spark 中的应用
- 第 15 讲:图的实现方式与核心算法
- 第 16 讲:图在 Uber 拼车业务中的应用
- 模块五:数据结构组合拳
- 第 17 讲:缓存数据结构在 Nginx 中的应用
- 第 18讲:高并发数据结构在 Instagram 与 Twitter 中的应用