
在介绍树之前我们先回顾一下之前学了哪些数据结构?以及还有哪些问题没法用之前的数据结构解决?这是我们在学习任何技术知识的一个重要习惯,思考一下假如没有这个技术会怎么样,这个技术解决了哪些以前不能解决的问题。
#### 有了数组和链表,为什么还需要树
在第 01、02 讲中我们一起学了数组,数组是一个很容易编程实现的静态数据结构,可以很好的支持随机访问。链表相对来说多了一些动态特性,链表适合的应用场景为需要比较频繁的增、删和更新操作。链表的时间复杂度特性我们也介绍了,相比数组,它的缺点是随机访问的时间复杂度为 O(n)。
基于数组和链表也有很多衍生出的数据结构,比如队列和堆栈,队列是先进先出,而堆栈是先进后出,它们可以被看作是定制化的数组或者队列,用来解决一些特定问题。之后我们又介绍了哈希表数据结构,哈希表的重要应用场景是快速查询和更新,正如我们之前学习的那样,哈希表的查询和更新时间复杂度都是均摊 O(1)。
数组和链表的局限性正是来自于它们的线性特点。当你需要在数组或者链表中查询一个元素时,则需要从头到尾遍历这个列表,此时的时间复杂度为 O(n)。试想一个含有 1 万个元素的集合,如果存储在一个数组或者链表里面,那么进行一万次查询需要多少时间呢?其时间复杂度是 O(108),这取决于你的内存访问速度和 CPU 速度,可能需要十几分钟的时间。
在现代的互联网应用中,1 万的 QPS 非常常见。如果要支撑每秒高达 1 万的访问,显然如果仅仅使用数组和链表是不够的。
所以树应运而生,这也是我们这一讲要讲的内容。树相比数组和链表,其抽象表达元素之间的关系更为复杂。我们一起来看看吧!
#### 树的定义和例子
树由节点和边连接组成,与数组和链表不同,它是一种非线性的数据结构。在学习树的规范而枯燥的数学定义之前,我们先来看一个例子吧!
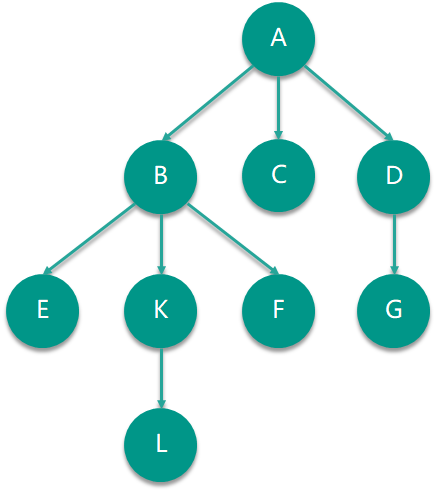
在上图中,A 是这棵树的根。除了根节点外的节点都有且仅有一条指向自己的边,这个边的方向代表了父节点指向了子节点。比如,A 是 B、C、D 的父节点,B 又被称为 A 的子节点,同时 B 也是 E、F、K 的父节点。
每个节点都可以连接着任意数量的子数(包括 0 个),没有子节点的节点也被称作叶子节点,在上图例子中,C、E、F、L、G 都是叶子节点。共享同样父节点的节点被称作兄弟节点,在上图例子中,B、C、D 就是兄弟节点。
一个节点的深度是从根节点到自己边的数量,比如 K 的深度是 2。 节点的高度是从最深的节点开始到自己边的数量,比如 B 的高度是 2。一棵树的高度也就是它根节点的高度
树的递归定义是: n(n>=0)个节点的有限集合,其中每个节点都包含了一个值,并由边指向别的节点(子节点),边不能被重复,并且没有节点能指向根节点。广义的树中,节点可以有 0 个或者多个子节点。而在后面章节中将介绍的二叉树等就是广义树中的特殊类型(每个节点有两个子节点)。
广义的树可以用来表达有层次结构的数据关系,比如文件系统(File System)是一个有层次关系的集合,文件系统中每一个目录(Directory)可以包含多个目录,没有子目录的叶子节点也就是文件(File)了。
公司里的汇报结构也可以用树来表达,比如我的手下有小明和小张两个人汇报工作,那么小明和小张都是我的子节点,小张下面还有 1 个程序员小李,没有人汇报给小李那么小李就是一个叶子节点。在这样一个汇报结构中我是这棵树的根节点。
正如这一讲开头所说的那样,人们设计树这样的数据结构是为了能够更好的组织数据、快速地查找数据。比如在文件系统中我们要查找一张照片,只需要找到照片文件夹再查询就可以了。
比如在公司组织架构中,假如我是负责网页平台的负责人,也就是网页平台子树的根节点,那么如果网页出了问题,CEO 很有可能就直接就来找我了,因为我是根节点,如果要让 CEO 去查询所有的程序员叶子节点,可能节点数量太多而无法遍历了。这也是为什么一个公司不能用链表这样的方式组织,那样的话,我作为 CEO,小张汇报给我、小李汇报给小张、小明再汇报给小李,最后只剩下唯一的叶子节点也就是链表最后一个元素在干活了。
#### 树的编程实现方式
树的实现方式有很多种,在这里介绍两种常见的实现方式,一种是基于链表的实现,另一种是基于数组的实现。对的,你没有看错,正是基于我们之前学习的数组和链表,这也是为什么在专栏开始就和你强调数组和链表是数据结构大厦的基石。高级的数据结构离不开对于这两种基础数据结构的深入理解。
基于链表的实现一般是每一个节点类型维护一个子节点指针和一个指向兄弟节点的链表,我们把它称作左孩子兄弟链表法。代码是这样的:
```
class TreeNode {
Data data;
LinkedList siblings;
TreeNode left_child;
}
```
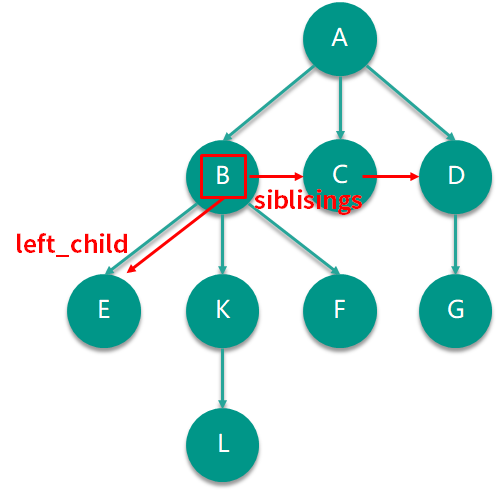
在我们上面图树的例子中,如果用左孩子兄弟链表法实现节点 B 的话,来看看节点 B 在这个代码中会是什么样子呢?如下图所示,节点 B 的 siblisings 节点是一个指向 C 接着指向 D 的链表,节点 B 的 left_child 节点则指向 E。
另一种基于数组的实现方式是每一个节点维护一个包含它所有子节点的数组,我们把它称作孩子数组法。
```
class TreeNode {
Data data;
ArrayList children;
}
```
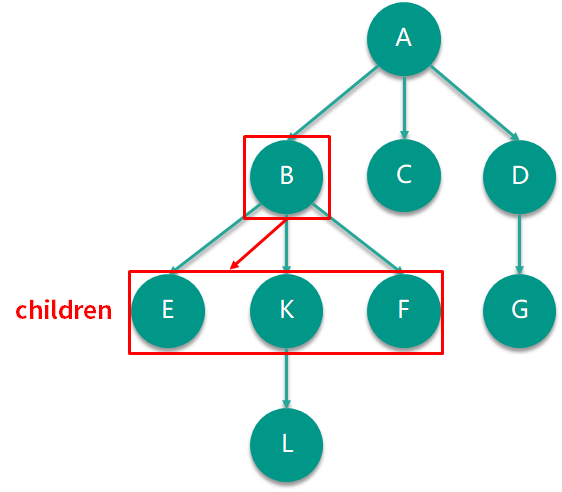
我们也来看看这种孩子数组法中在实际例子中的样子吧!如下图所示,同样是节点 B,利用孩子数组法实现的话,需要维护一个包含 E、K、F 的数组。
看来这两种方式实现起来似乎都挺容易的,实际并不是这样的。你能看出这两种实现方式的差异吗?
在实现一个树的编程中,最容易犯的错误在于内存管理和节点的增、删、改。
为了更好的阐述这里的内存管理以及增删改问题,我们用 C++ 进行示范,一种简单幼稚的孩子数组法实现是这样的:
```
class TreeNode {
Data data;
std::vector<TreeNode> children;
};
```
可以发现,所有子节点的内存都是由父节点管理,也就是说当父节点被删除时,子节点的内存也会被自动清理。那就造成了一个很严重的问题,我们很难方便地删除任意一个非叶子节点。所以事实上用孩子数组实现的话我们往往只能维护一组子节点的指针,像是这样:
```
class TreeNode {
Data data;
std::vector<TreeNode*> children;
};
```
这就造成了另一个问题,子节点的内存由谁来管理呢?所以一个解决办法是除了实现这样一个 TreeNode 类,再去实现一个 NodePool 类用来管理所有的节点内存。例如下面代码,用一个简单的动态数组维护内存:
```
class NodePool {
std::vector<TreeNode> nodes;
}
```
另一个解决办法则是模仿链表的内存管理,在左孩子兄弟链表法中比较容易实现,因为它实际上就是一个二叉的链表。
除了内存管理问题,树节点的插入、删除也是难点。如果你还记得之前学习的数组和链表基本操作,就能知道数组的随机元素增删是 O(n) 的复杂度,而链表是 O(1)。在这里树的实现方式也是类似。
在左孩子兄弟链表法中,插入一个树节点的复杂度是 O(1),相当于是在 siblings 链表中插入一个元素,或者是增加一个 left_child 节点。而在孩子数组法中插入一个节点和数组插入元素类似,需要挪动其后的所有节点,则是 O(n) 的复杂度。
删除节点相比插入节点更为复杂一些,同样的,在孩子数组法中,删除单个节点的复杂度是 O(n),因为你需要去拷贝这个节点的子树到上层节点。在左孩子兄弟链表法中,删除单个节点的复杂度为 O(1),你只需要去重新整理几根指针引用就可以了。
那么现在看来左孩子兄弟链表法各项表现都优于孩子数组法,的确如此,左孩子兄弟链表法是树的教科书范式实现方法。但在实际应用中我们还是常常见到孩子数组法,为什么呢?因为孩子数组法从 API 使用角度更为简单,使用者可以随机访问任意孩子。特别当我们想要提供一个数组的只读的镜像时(Read-Only View),孩子数组法可以作为 API 提供,但是背后可修改的树仍然是由更为复杂的私有方法实现的。
* [ ] 树的遍历和基本算法
除了树的增、删、改,树最最常见的操作就是查找操作,也就是遍历。如果没有遍历,增、删、改根本无从谈起,因为你都不知道去操作哪个节点!树的遍历根据根节点的访问顺序,可以分为前序遍历、后续遍历和按层遍历等多种。所谓前序遍历用伪代码表示就是:
* 先访问根节点N
* 递归访问N的子树
你一定猜到了所谓后续遍历是相似的:
* 递归访问N的子树
* 后访问根节点N
按层遍历呢?就是从上到下、从左到右访问。例如,在上面的树的例子中,按层遍历的结果是:A, B, C, D, E, K, F, G, L。
我们来看看在左孩子兄弟链表法中怎样实现前序遍历吧!
```
class TreeNode {
TreeNode* left_child;
TreeNode* sibling;
}
void PreorderVisit(TreeNode root) {
Visit(root);
for (TreeNode* child = root->left_child; child != nullptr; child = child->sibling) {
PreorderVisit(child);
}
}
```
#### 总结
这一讲到这里你已经了解了我们为什么需要树,掌握了树的概念和定义,更重要的是比较了树的实现方式和遍历方法,树的遍历复杂度相信你肯定也已经看出来了,是 O(n)。如果你不忘初心,还记得在开头说的树是为了更快的方便数据查找,此时你一定有疑问,好像树并没有更高效的数据查询啊?这个呢,我们将会在第 11 讲的二叉查询树章节中展开讲解,在讲二叉查询树之前我们也会先讲解广义树的重要应用。
- 前言
- 开篇
- 开篇词:从此不再“面试造火箭、工作拧螺丝”
- 模块一:数组与链表的应用
- 第 01 讲:数组内存模型
- 第 02 讲:位图数组在 Redis 中的应用
- 第 03 讲:链表基础原理
- 第 04 讲:链表在 Apache Kafka 中的应用
- 模块二:哈希表的应用
- 第 05 讲:哈希函数的本质及生成方式
- 第 06 讲:哈希函数在 GitHub 和比特币中的应用
- 第 07 讲:哈希碰撞的本质及解决方式
- 第 08 讲:哈希表在 Facebook 和 Pinterest 中的应用
- 模块三:树的应用
- 第 09 讲:树的基本原理
- 第 10 讲:树在 Amazon 中的应用
- 第 11 讲:平衡树的性能优化
- 第 12 讲:LSM 树在 Apache HBase 等存储系统中的应用
- 模块四:图的应用
- 第 13 讲:用图来表达更为复杂的数据关系
- 第 14 讲:有向无环图在 Spark 中的应用
- 第 15 讲:图的实现方式与核心算法
- 第 16 讲:图在 Uber 拼车业务中的应用
- 模块五:数据结构组合拳
- 第 17 讲:缓存数据结构在 Nginx 中的应用
- 第 18讲:高并发数据结构在 Instagram 与 Twitter 中的应用