
你好,我是你的数据结构课老师蔡元楠,欢迎进入第 03 课时的内容“链表基础原理”。
这一讲,我想和你一起研究数据结构中另外一个基本的知识点——链表(Linked List)。在讲解这个概念之前,先来复习一下数组的内存模型。
#### 内存管理器
当我们在使用高级语言创建一个数组的时候,实际上是将这个指令传达了给操作系统里面的内存管理器(Memory Manager),内存管理器在收到指令后会在内存中分配一块相应大小的连续存储空间给这个数组。
例如,当想创建一个大小为 5 的数组时,内存管理器有可能会从 0x80000000 这个地址开始分配一个连续的内存块给我们,我们便可以操作这个数组了,如下图所示。
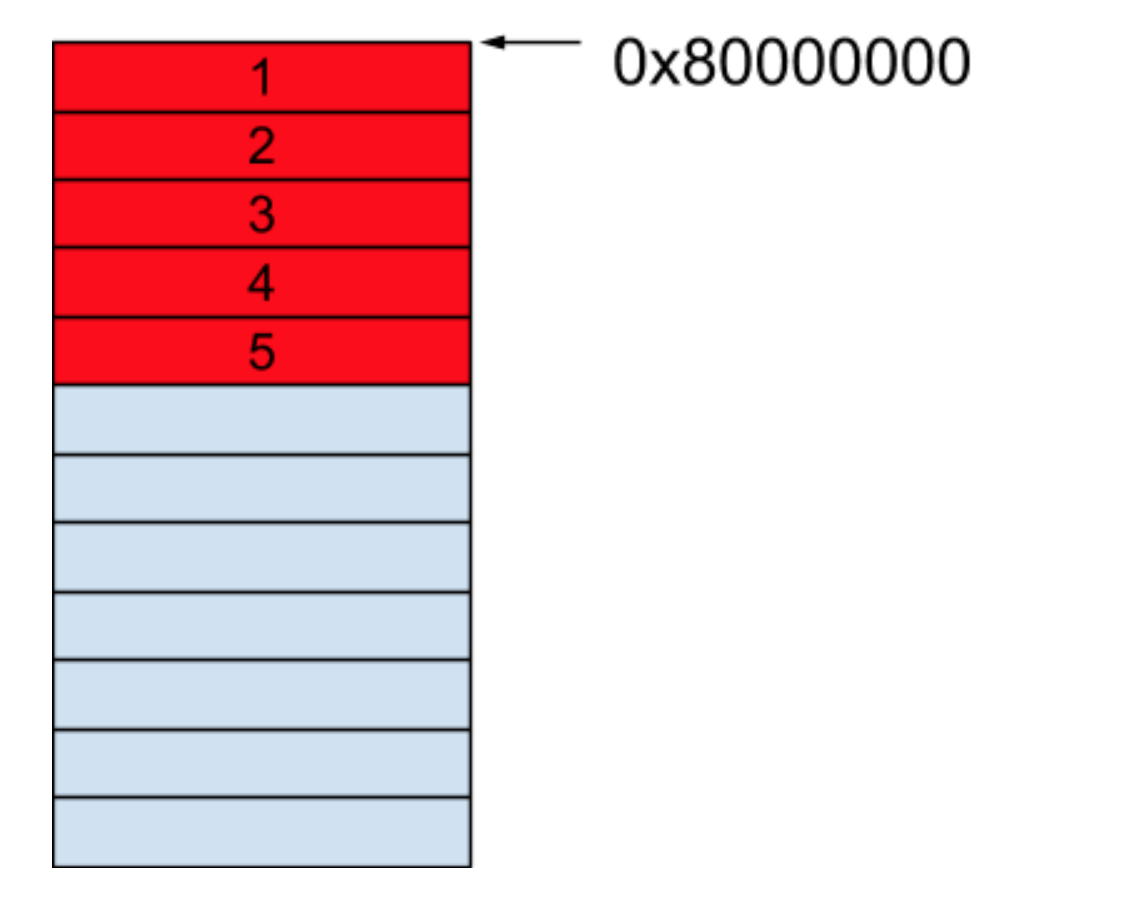
而因为数组的大小在一开始是已经确定好的,所以当我们想要增加一个元素的时候,内存管理器无法满足这个需求,只能重新创建一个新的大小为 6 的数组。然后将原来大小为 5 的数组里的值一一复制到新的数组中去,再对新的元素进行赋值。我们假设内存管理器将新的数组的起始地址设在了 0x80000018 这里,那这个时候的内存如下图所示。
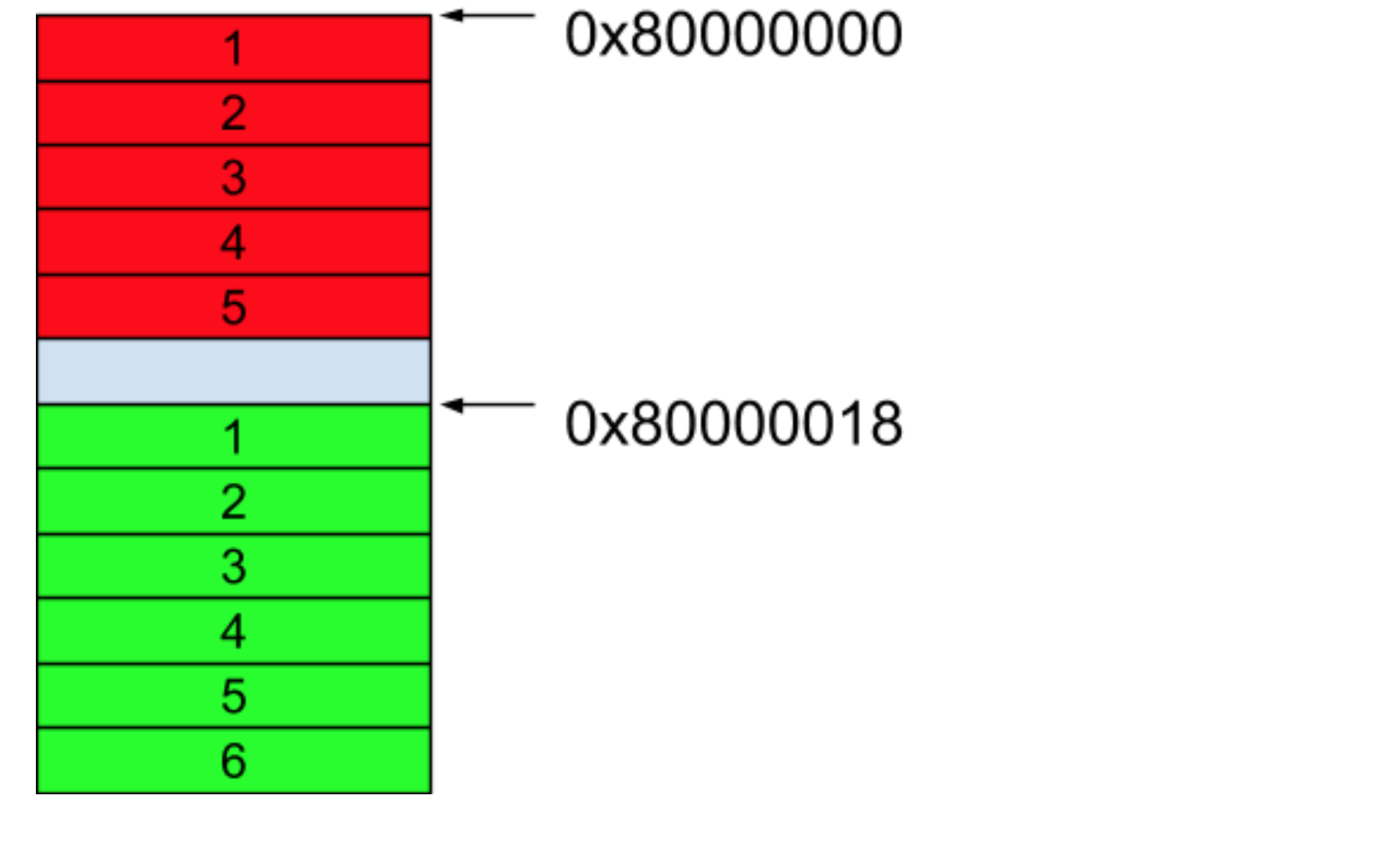
所以我们看到,当每次要增加一个元素的时候,底层的内存管理器必须为我们重新分配一次内存,我们自己还必须将原来数组上的元素重新复制一遍到新的数组上。那有没有办法当每次增加元素的时候能减少这种内存上的消耗呢?其实可以想到的是,当每次新增加一个元素的时候让内存管理器不要分配一段连续的内存空间就可以了。
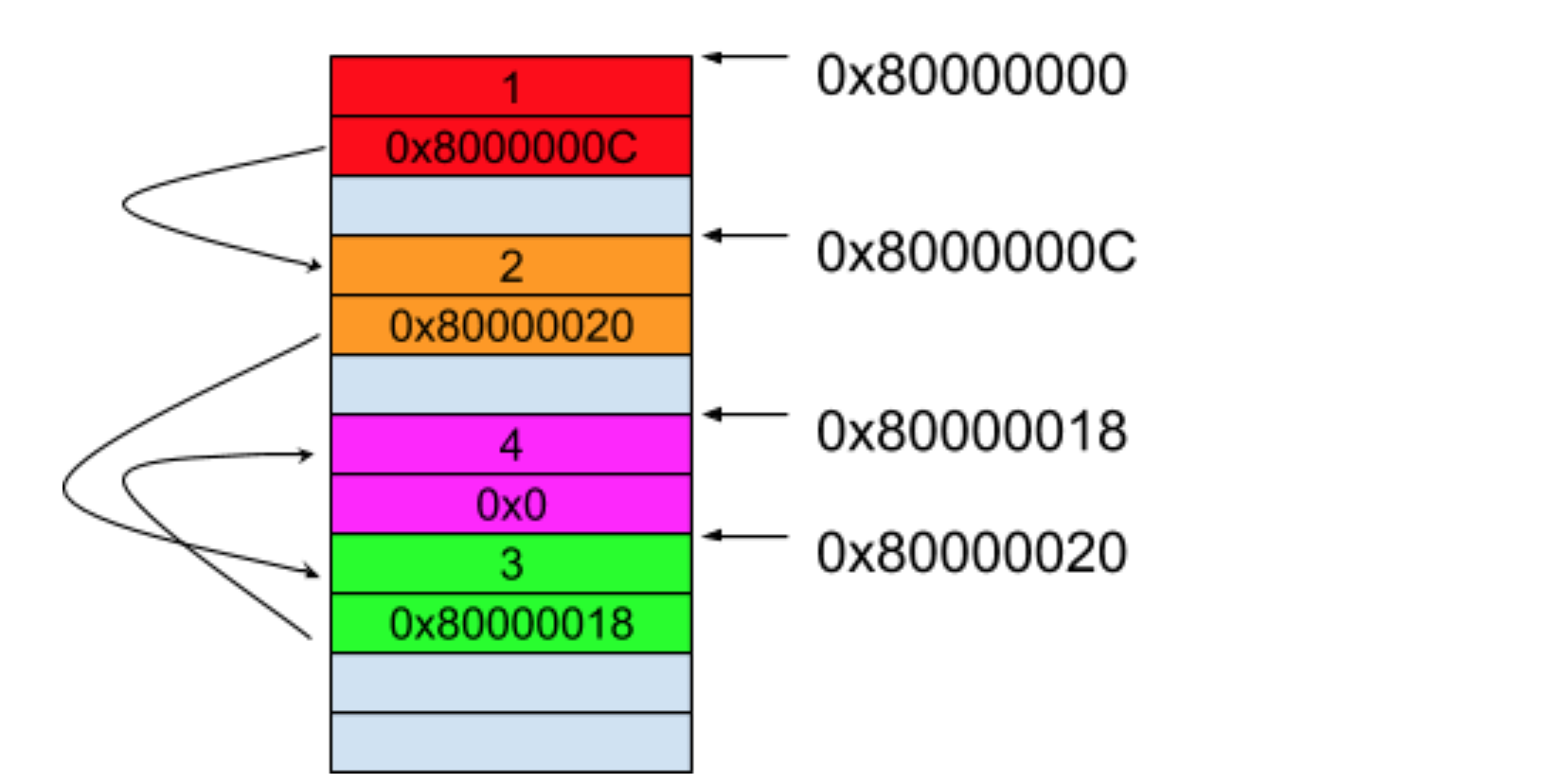
假设这时候我们想要保存 3 个元素,但是我们想告诉系统的内存管理器不需要一次性分配 3 个连续的字节内存空间出来了,而是当我们声明它们的时候才分配一个相应的内存空间出来。假设内存管理器所分配出来的内存空间如下图所示:
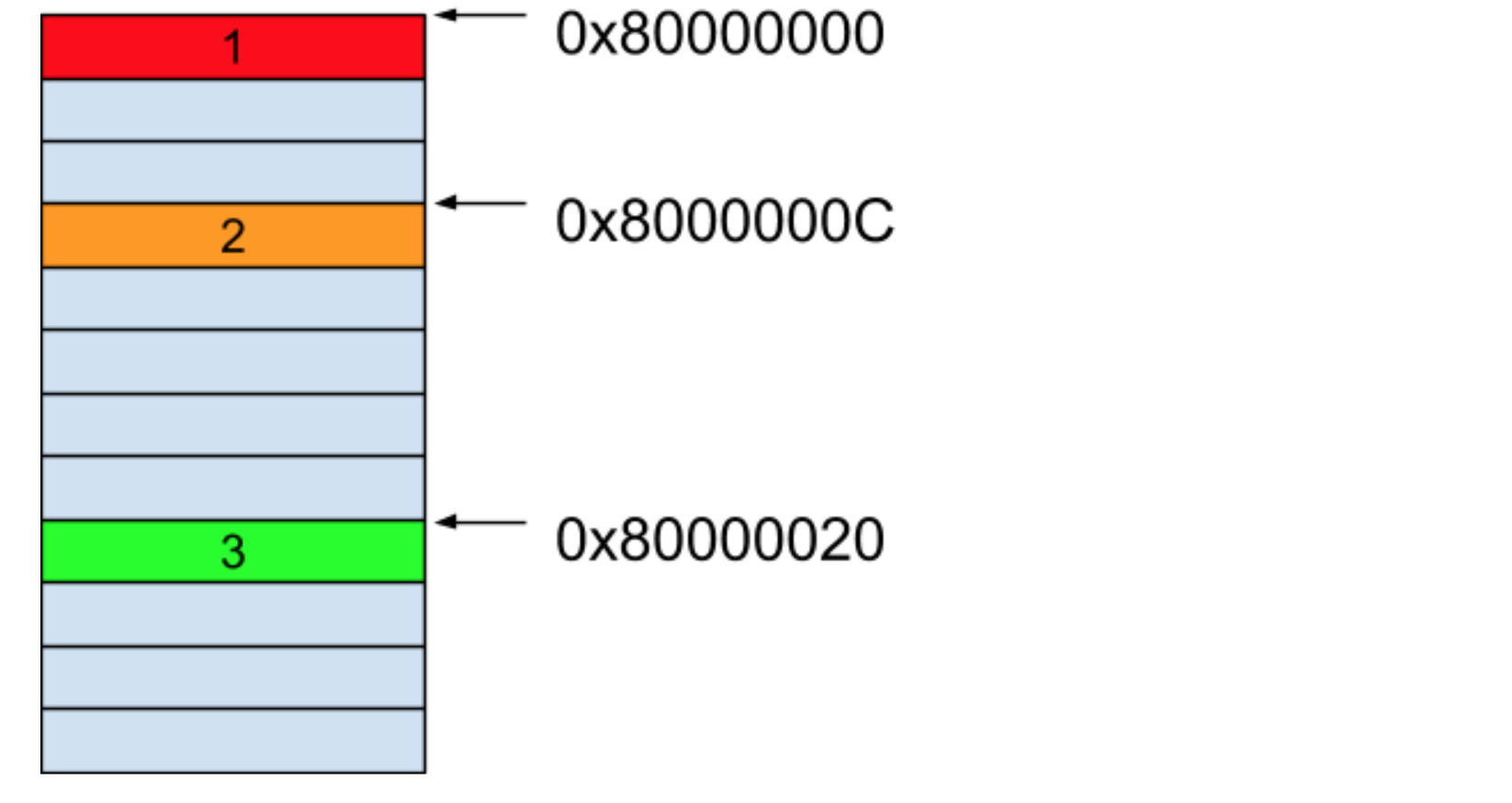
这三个元素被分配在了非相邻的内存空间里。但从上图中我们可以知道这三个元素各自的地址,所以想要遍历它们的话,我们需要保存一些额外的信息,比如,下一个能遍历到的元素地址。这样的话,每一个元素就保存了两部分的内容,一部分是元素本身的值,另一部分是下一个元素的地址,而最后一个元素的下一个地址我们可以保存一个 0x0 的值来表示这个元素是最后一个了。这时候这些数据的内存就如下图所示:
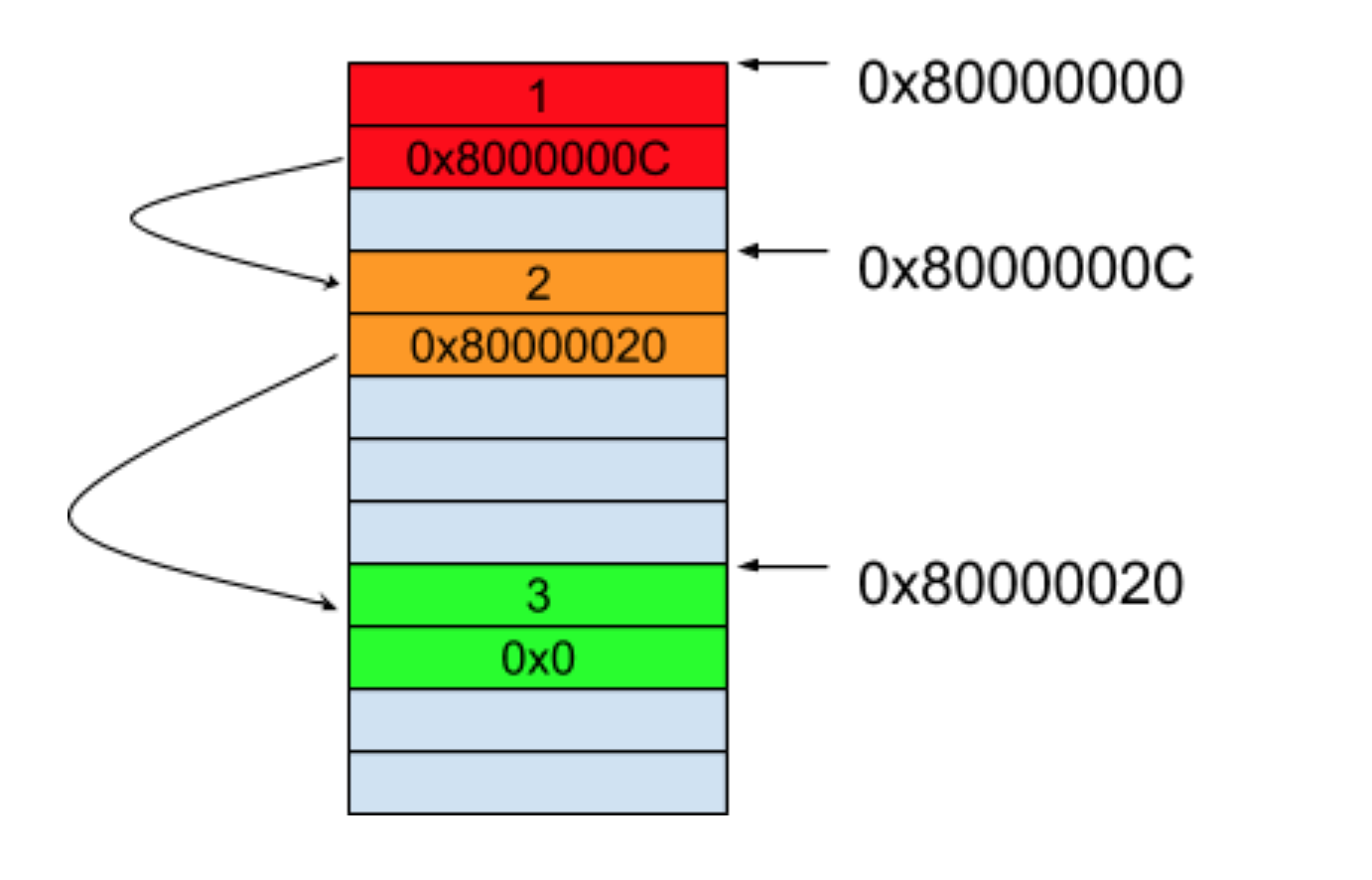
从上图可以看到,尽管这些元素不是分配在连续的空间里,但是通过保存额外的信息让一个元素可以链接到下一个元素上,只要知道了这些数据中的第一个元素,便可以将全部元素都遍历一遍。在计算机里,这种不保存在连续存储空间中,而每一个元素里都保存了到下一个元素的地址的数据结构,我们称之为链表(Linked List)。链表上的每一个元素又可以称它为节点(Node),而链表中第一个元素,称它为头节点(Head Node),最后一个元素称它为尾节点(Tail Node)。
#### 顺序访问
与数组不同的是,我们无法使用一个固定的公式来直接算出某一个特定元素的地址,从而得到那个元素的值。要找到链表中的第 N 个元素的值,我们必须要从第一个元素开始,一个一个地遍历 N 次才能找到第 N 个元素,这种访问方式,我们就称之为顺序访问(Sequential Access)。
当我们需要在链表的结尾增加一个元素的时候应该怎么办呢?很简单,只需要新创建一个链表的节点,然后将尾节点中保存地址的值更新成新的节点地址便可。
假设我们原有的链表内存图如下所示:

当我们要插入的一个值为 4 的新节点进这个链表的时候,系统的内存管理器会分配一个新的内存空间给我们,然后我们再将值为 3 这个尾节点的地址更新为它的地址,如下图所示:
#### 数组与链表的性能差异
* [ ] 空间利用率
首先我们来一起看看在空间利用率上的对比。因为数组在创建之后大小是无法改变的,想要增加元素的话就必须重新创建一个新的数组。所以有的时候,为了能够动态地增加元素,我们会在一开始创建数组的时候声明一个比我们本来需要的大小还多的空间出来,以便后面添加新的元素。这个时候就会造成空间上的浪费,所以,数组的空间利用率相当于本来需要的大小除以创建出来数组的大小。
而因为链表中的元素只有当需要的时候才会被创建出来,所以不存在需要多预留空间的情况。对于我们工程师来说,只有节点里的值是可以利用上的,而保存节点地址的内存其实对于我们来说是无法应用的。所以链表的空间利用率上相当于值的大小除以值的大小和节点地址大小的和。
在我们上面所举的例子中,因为链表中保存的值只是一个 int 的值,和节点地址大小一样,所以在空间利用率上只有 50%。但是在现实应用中,链表中保存的值远远不是一个基本类型就这么简单,当我们所保存的值的大小越大的时候,空间利用率也会越高。
* [ ] 时间复杂度
在第 01 讲的内容中,我们知道了访问数组元素的时间复杂度是 O(1)。而因为链表顺序访问的这个特性,访问链表中第 N 个元素需要从第一个元素一直遍历到第 N 个元素,所以平均下来的时间复杂度是 O(N)。
对于数组来说,插入操作无论是发生在数组结尾还是发生在数组的中间,因为都需要重新创建一个新的数组出来,并复制一遍之前的元素到新的数组中,所以平均的时间复杂度都是 O(N)。而对于链表来说,要是我们一直都能维护一个尾节点的地址的话,那么插入一个新的元素只需要 O(1) 的时间复杂度。而当插入一个元素到链表中间的时候,因为链表顺序访问的这个特性,我们需要先遍历一遍链表,从第一个节点开始直到第 N 个位置,然后再进行插入,所以平均下来的时间复杂度是 O(N)。
#### 链表的各种形式
* [ ] 单向链表
在上面所举的例子当中,你可能已经发现了,所有的链表节点中都只保存了指向下一个节点地址的信息。这种在一个节点中既保存了我们需要的数据,也保存了指向下一个节点地址信息的链表,称之为单向链表(Singly Linked List)。抽象的数据图就如下图所示:

* [ ] 双向链表
单向链表有着只能朝着一个方向遍历的局限性,既然我们可以保存指向下一个节点地址的信息,也可以保存指向上一个节点地址的信息。这种在一个节点中保存了我们需要的数据也保存了连向下一个和上一个节点地址信息的链表,称之为双向链表(Doubly Linked List)。和链表中尾节点的下一个节点只保存空地址一样,链表中头节点的上一个节点地址也保存着空地址,抽象的数据图就如下图所示:

* [ ] 循环链表
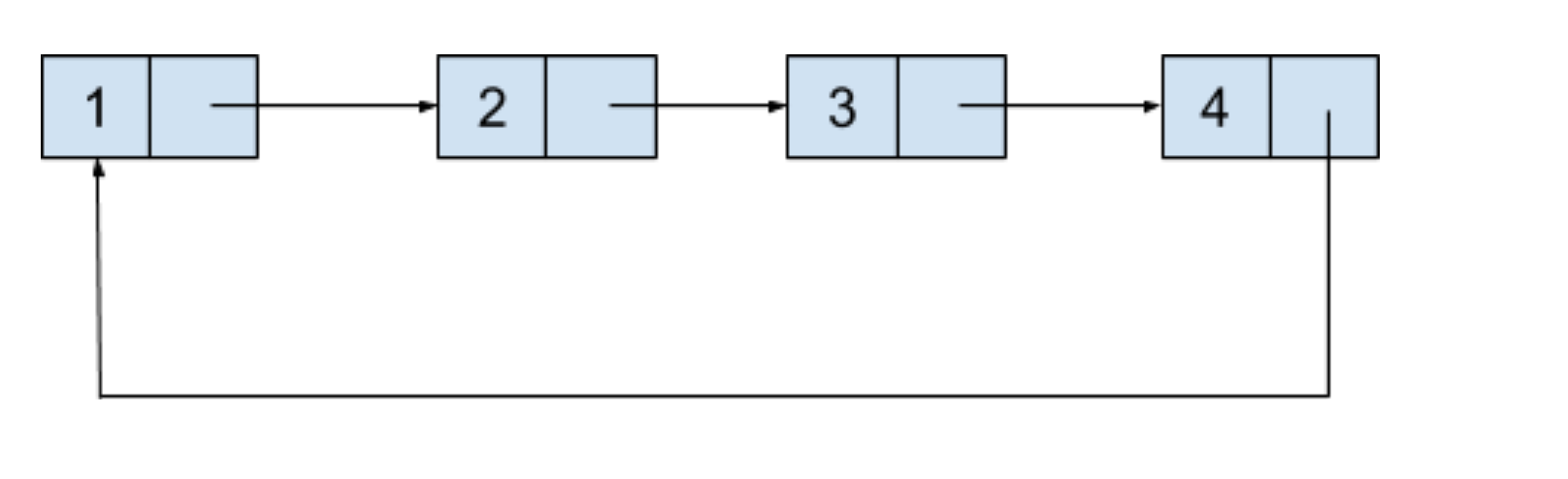
无论是单向链表或者是双向链表,当我们遍历至尾节点之后就无法再遍历下去了,如果将尾节点指向下一个节点地址的信息更新成指向头节点的话,这样整个链表就形成了一个环,这种链表称之为循环链表(Circular Linked List)。抽象的数据图就如下图所示:
今天我们一起学习了链表这个基本概念以及了解了链表的内存结构,同时我们也对比了数组与链表中空间利用率以及基本操作的时间复杂度,在最后也学习了链表的不同表达形式。在下一讲中,我将会和你一起看看环形链表这种数据结构是如何被大量应用在操作系统定时器和 Apache Kafka 中的。
OK,这节课就讲到这里啦,下一课时我将分享“链表在 Apache Kafka 中的应用”,记得按时来听课哈。
- 前言
- 开篇
- 开篇词:从此不再“面试造火箭、工作拧螺丝”
- 模块一:数组与链表的应用
- 第 01 讲:数组内存模型
- 第 02 讲:位图数组在 Redis 中的应用
- 第 03 讲:链表基础原理
- 第 04 讲:链表在 Apache Kafka 中的应用
- 模块二:哈希表的应用
- 第 05 讲:哈希函数的本质及生成方式
- 第 06 讲:哈希函数在 GitHub 和比特币中的应用
- 第 07 讲:哈希碰撞的本质及解决方式
- 第 08 讲:哈希表在 Facebook 和 Pinterest 中的应用
- 模块三:树的应用
- 第 09 讲:树的基本原理
- 第 10 讲:树在 Amazon 中的应用
- 第 11 讲:平衡树的性能优化
- 第 12 讲:LSM 树在 Apache HBase 等存储系统中的应用
- 模块四:图的应用
- 第 13 讲:用图来表达更为复杂的数据关系
- 第 14 讲:有向无环图在 Spark 中的应用
- 第 15 讲:图的实现方式与核心算法
- 第 16 讲:图在 Uber 拼车业务中的应用
- 模块五:数据结构组合拳
- 第 17 讲:缓存数据结构在 Nginx 中的应用
- 第 18讲:高并发数据结构在 Instagram 与 Twitter 中的应用