
Spark 是当今最流行的分布式大规模数据处理引擎之一,被广泛应用在各类大数据处理的场景中,而大数据处理框架的核心就是用有向无环图(DAG)来优化数据处理任务的。我们来看一个例子吧。
假设你的大数据处理任务是根据活跃在街头的美团外卖电动车的数量来预测美团的股价,而你负责处理所有美团外卖电动车的图片。在真实的商用环境下,你可能至少需要 10 个子任务:
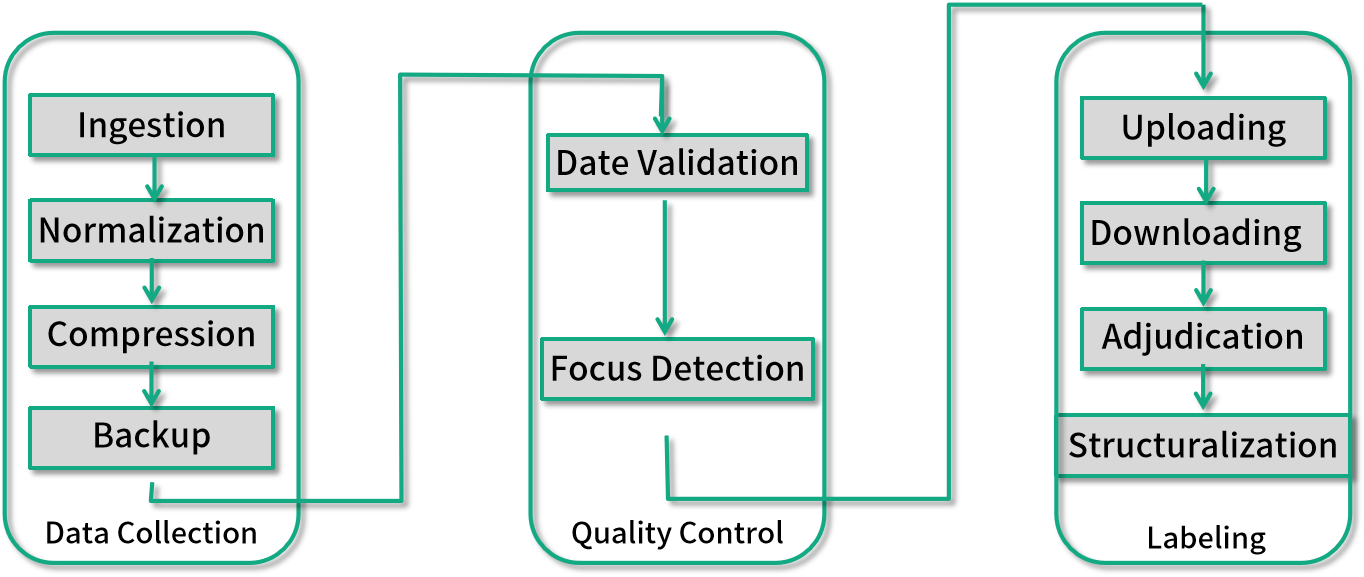
为什么需要这么多数据处理任务?且听我一一解释。
首先我们需要搜集每日的外卖电动车图片,往往数据搜集的工作不仅仅是公司本身完成的,部分也有外包或者众包,所以在数据搜集(Data Collection)部分,你至少需要以下 4 个数据来处理任务。
* (1)数据导入(Data Ingestion):用来把散落在比如众包公司上传到网盘的照片下载到你的存储系统中。
* (2)数据统一化(Data Normalization):用来把不同外包公司各式各样的格式统一。
* (3)数据压缩(Compression):你需要在质量可接受的范围内保持最小的存储资源消耗。
* (4)数据备份(Backup):大规模的数据处理系统我们都需要一定的数据冗余来降低风险。
仅仅是数据搜集离真正的业务应用还差得远,真实的世界是如此的不完美,我们需要一部分数据质量控制(Quality Control)流程,比如:
* (1)数据时间有效性验证(Date Validation),检测上传的图片是否是你想要的日期;
* (2)照片对焦检测(Focus Detection),你需要筛选掉那些对焦不上,完全无法使用的照片;
最后才到你的重头戏,即找到这些图片里的外卖电动车,而这一步因为人工的介入是最难控制时间。
此时,你需要:
* (1)数据标注问题上传(Question Uploading),上传到你的标注工具,让你的标注者开始工作;
* (2)标注结果下载 (Answer Downloading),抓取标注完的数据;
* (3)标注异议整合(Adjudication),标注异议经常发生,比如一个标注者认为是美团外卖电动车,另一个标注者认为是京东快递电动车;
* (4)标注结果结构化(Structuralization),要让标注结果可用,你需要把可能非结构化的标注结果转化成你的存储系统接受的结构。
这样,复杂的数据处理如果再去人工维护的话,则令人苦不堪言,因为你需要知道先执行哪个任务再执行哪个任务。
#### 有向无环图
为了解决这个问题,在 Spark 等大数据处理框架中可用有向无环图(DAG)来抽象表达。因为有向图能为多个步骤的数据处理依赖关系,建立很好的模型。我们来复习一下上一讲中有向无环图的概念。
比如下图是一个有向图:
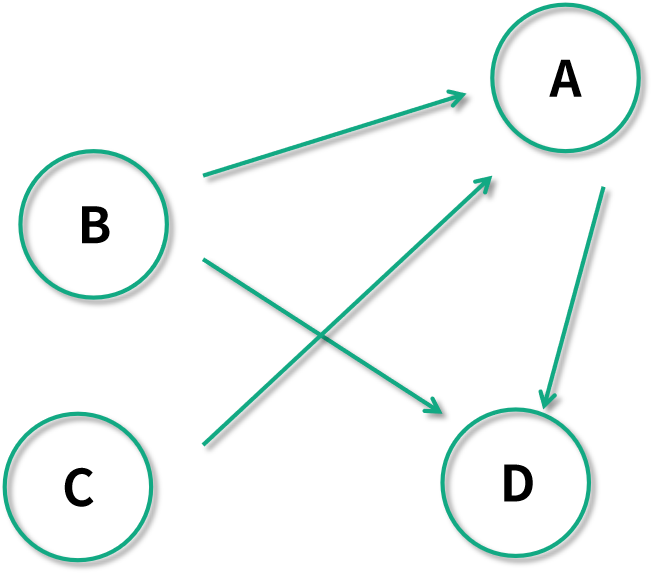
有向图可以表达任务之间的依赖关系,比如 B 指向 A,我们可以表达要执行任务 A ,则需要先完成任务 B 才可以。
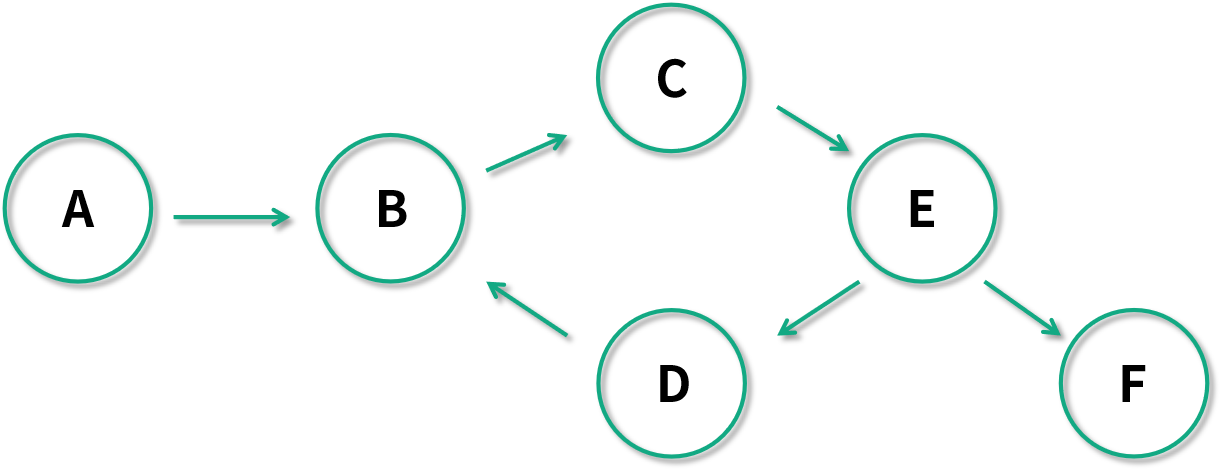
比如下图是一个有环图。下图中 B 任务依赖于 D,C 任务依赖于 B,E 任务依赖于 C,D 任务又依赖于 B。有环图在表达任务关系的时候是一个灾难,因为你没法找到是从哪个任务开始处理的。
* [ ] 如何用有向无环图抽象表达数据处理的任务
回顾了有向和无环图的特性,我们来看如何用有向无环图(DAG)来抽象表达数据处理任务。下面列举一个生活中的任务处理案例。
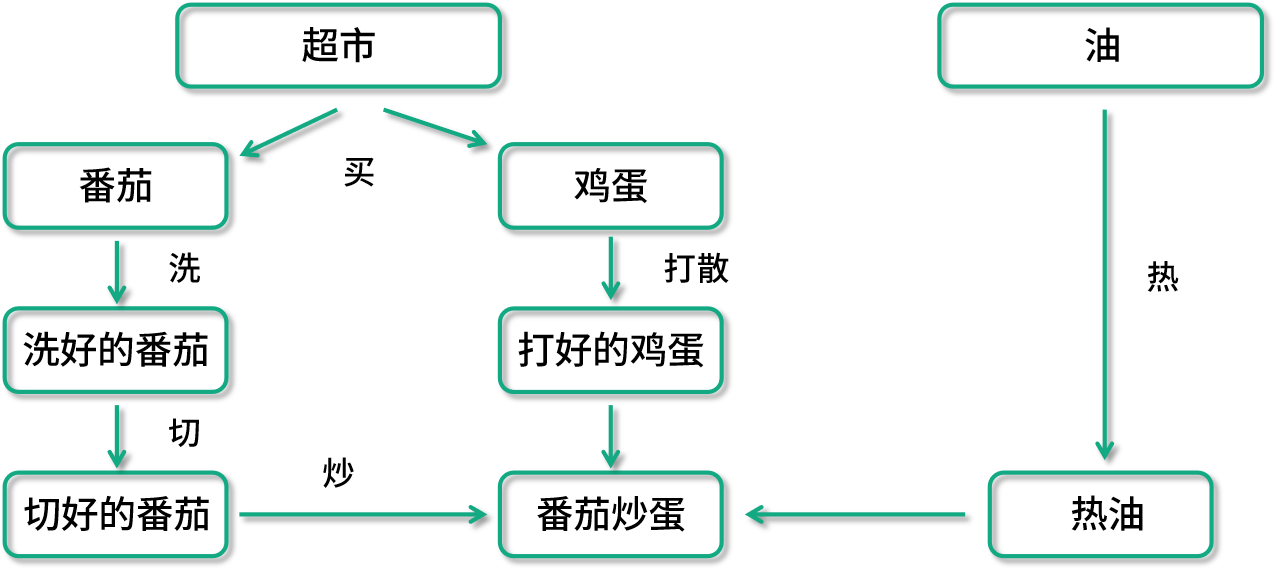
西红柿炒鸡蛋这样一个菜,就是一个有向无环图概念的典型案例。比如看这里面番茄的处理,最后一步炒的步骤依赖于切好的番茄、打好的蛋、热好的油,切好的番茄又依赖于洗好的番茄等操作。如果用 Spark 来实现的话,在这个图里面,每一个箭头都会是一个独立的数据转换操作(Transformation)。
Spark 利用有向无环图表达数据处理后可以对数据处理流程做自动优化。回到刚才的番茄炒鸡蛋的例子,哪些情况我们需要自动的优化呢?
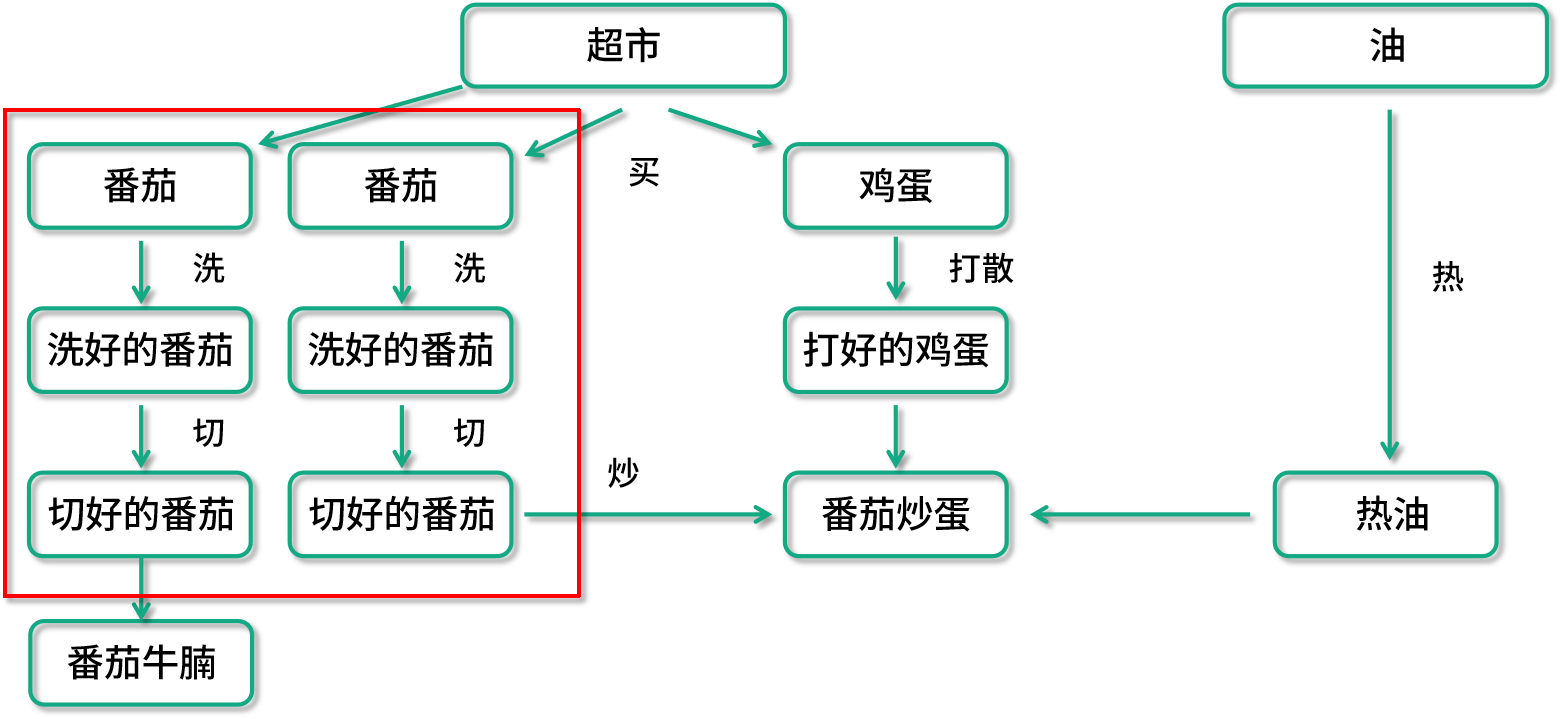
设想一下我们的数据在处理食谱上又增加了番茄牛腩的需求,用户的数据处理有向图就变成了这个样子了。在理想的情况下,我们的计算引擎要能够自动发现红框中的两条数据处理流程是重复的,它要能把两条数据处理过程进行合并。这样的话,番茄就不会被重复准备了;同样的,如果需求突然不再需要番茄炒蛋了,只需要番茄牛腩,在数据流水线的预处理部分也应该把一些无关的数据操作优化掉,比如整个鸡蛋的处理过程就不应该在运行时出现。
另一种自动的优化是计算资源的自动弹性分配。比如还是在番茄炒蛋这样一个数据处理流水线中,如果你的规模上来了,今天需要生产 1 吨的番茄炒蛋,明天需要生产 10 吨的番茄炒蛋。此时你会发现,有时候是处理 1000 个番茄,有时候又是 10000 个番茄。如果手动去做资源配置的话,那再也配置不过来了。我们的优化系统也要有这种弹性的劳动力分配机制,它要能自动分配比如 100 台机器处理 1000 个番茄,如果是 10000 个番茄那就分配 1000 台机器,但是只给热油 1 台机器可能就够了。
有向无环图便是 Spark 框架能够自动优化执行计划的核心,再看一个例子:
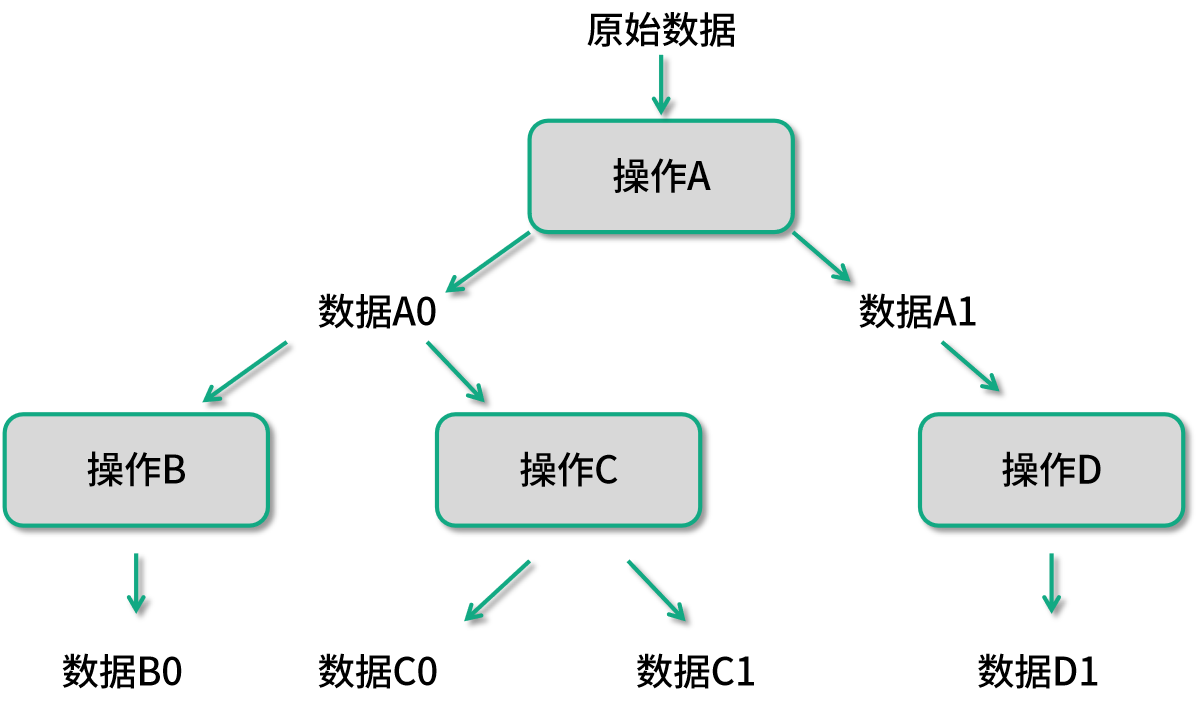
类似图中这样的数据处理流程,在 Spark 获知了整个数据处理流程就会被优化成如下图所示的样子:
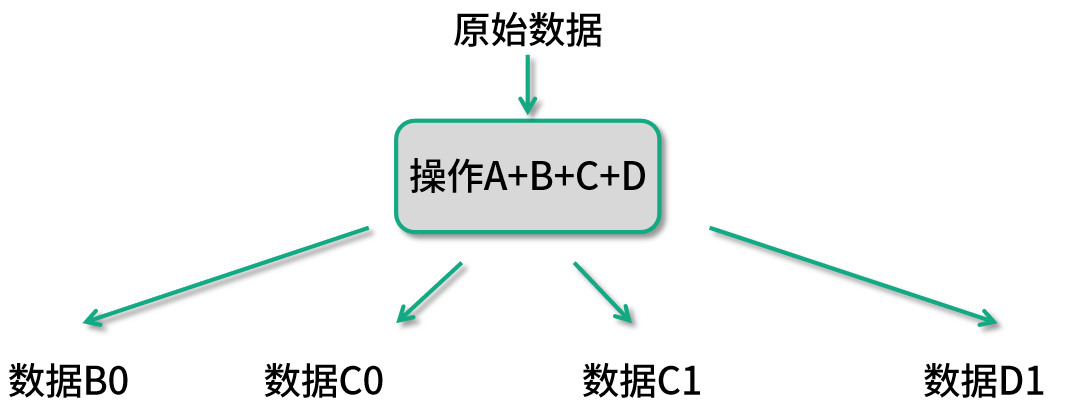
这样的优化在 Spark 中被称为兄弟融合优化(Sibling Fusion)。
#### 总结
这一讲我们回顾了图的有向和无环的概念,利用有向图建模生活中的数据处理问题,并分析了 Spark 怎样利用有向无环图优化数据处理。
- 前言
- 开篇
- 开篇词:从此不再“面试造火箭、工作拧螺丝”
- 模块一:数组与链表的应用
- 第 01 讲:数组内存模型
- 第 02 讲:位图数组在 Redis 中的应用
- 第 03 讲:链表基础原理
- 第 04 讲:链表在 Apache Kafka 中的应用
- 模块二:哈希表的应用
- 第 05 讲:哈希函数的本质及生成方式
- 第 06 讲:哈希函数在 GitHub 和比特币中的应用
- 第 07 讲:哈希碰撞的本质及解决方式
- 第 08 讲:哈希表在 Facebook 和 Pinterest 中的应用
- 模块三:树的应用
- 第 09 讲:树的基本原理
- 第 10 讲:树在 Amazon 中的应用
- 第 11 讲:平衡树的性能优化
- 第 12 讲:LSM 树在 Apache HBase 等存储系统中的应用
- 模块四:图的应用
- 第 13 讲:用图来表达更为复杂的数据关系
- 第 14 讲:有向无环图在 Spark 中的应用
- 第 15 讲:图的实现方式与核心算法
- 第 16 讲:图在 Uber 拼车业务中的应用
- 模块五:数据结构组合拳
- 第 17 讲:缓存数据结构在 Nginx 中的应用
- 第 18讲:高并发数据结构在 Instagram 与 Twitter 中的应用