
不知你是否还记得在第 9 讲中,我们讲了“为什么需要树”,是因为人们想要更好的检索信息。这时候你一定会有疑问:可是我们到现在都还没讲怎样用树查找信息啊?
要用树检索信息,就不得不掌握平衡树,平衡树的全称是平衡二叉查找树(Balanced Binary Search Tree,简称 Balanced Tree)。为什么可以把“二叉”这个特性省略呢?是因为没有二叉这个很强的约束条件,其实平衡的意义也不是很大,为什么呢?下面且听我细细道来。
#### 二叉查找树 (BST)
我们先来看二叉查找树(Binary Search Tree,简称 BST),二叉查找树顾名思义就是有查找功能的二叉树,还是先来看一个例子吧:
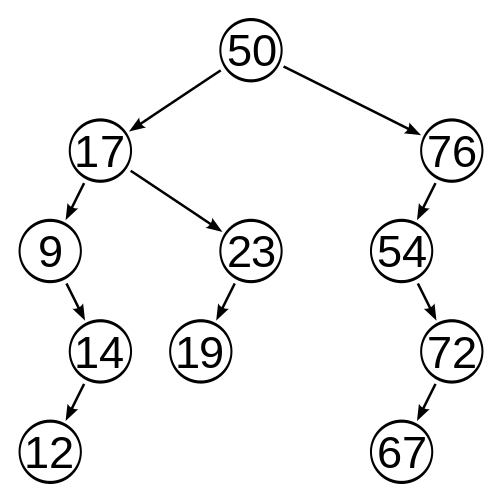
上图是一颗以 50 节点为根的二叉查找树,规范的来说:
* 二叉查找树是一棵二叉树,也就是说每一个节点至多有 2 个孩子,也就是 2 个子树。
* 二叉查找树的任意一个节点都比它的左子树所有节点大,同时比右子树所有节点小。
我们来验证一下上图这个例子是不是符合二叉查找树的定义。可以先看 50 这个根节点,它只有两个孩子,它的左子树的节点比如 17,50 是大于 17 的,又比如 19,50 也大于 19;右孩子呢,有 76,50 小于 76,还有比如 72,50 也小于 72。所以 50 这个节点符合了关于孩子个数,以及孩子与自己之间大小的定义了。
我们再看一个节点,比如 23 这个节点,它只有一个孩子,也可以说,它唯一的后代是 19,19 小于 23,完美。看来我们这棵树的的确确是一个二叉查找树。
#### 在二叉查找树中搜索节点
知道了二叉查找树的定义,我们一定要探寻它的究竟!为什么二叉查找树定义奇怪的特性,究竟有什么用?其实都是为了方便搜索节点!
你看,因为我们已经知道了所有左子树的节点都小于根节点,所有右子树的节点都大于根节点。当我们需要查找一个节点的时候,如果这个节点小于根,那我们肯定是去左子树中继续查找,因为它不可能出现在右子树中了,右子树的所有节点必须大于根。反过来说,如果想要查找的值大于根呢?我们就只需要去右子树中查找即可。
是不是搜索变得很简单了?也很容易用递归的方式实现:
```
TreeNode* Search(TreeNode* root, int key) {
if (root == nullptr || root->key == key) {
return root;
}
if (root->key < key) {
return Search(root->right, key);
}
return Search(root->left, key);
}
```
这是不是让你想起了经典的二分查找法?确实很类似。这样在二叉查找树中的搜索形象的说,就是顺着根节点往下撸。上面 Search() 方法的每一次调用都会在树中往下移动一层。所以我们可以想到这样的算法时间复杂度,就是树的高度 O(h)。
让我们想象一个最优情形,如果二叉查找树是完美对称平衡的,如图中所示:
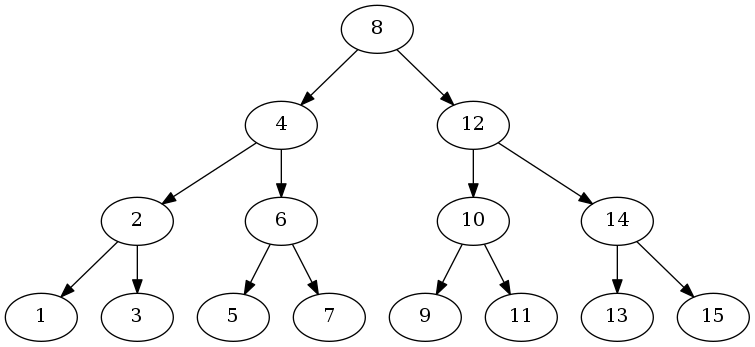
这棵树的高度是 O(log n),n 是这棵树的节点数量。无论搜索哪个节点,我们最多需要运行上面的 Search() 方法 O(log n),怎么样?是不是有种逃不出如来佛祖手掌心的感觉。
再让我们看一个最坏的情况,如果二叉查找树每一个节点都只有一个孩子呢?如图中所示:
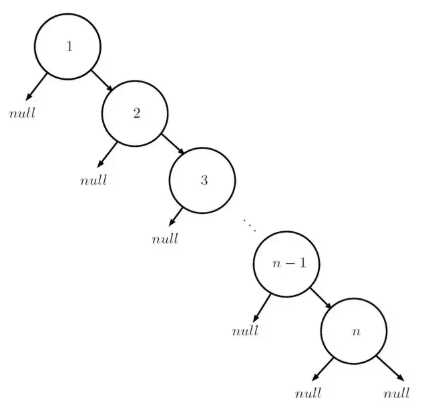
这样的二叉树退化成了一个一维链表,最坏情况是需要从第一个节点查找到第 n 个节点,时间复杂度就成了 O(n) 了。
到这里我们就明白了,二叉查找树的搜索特性听起来很美好,但实际上如果这棵树的形状长得不好,数据偏向一边而不平衡,也无从谈起高效的查询特性啊,那我们怎样维护好一个二叉查找树的高度和形状呢?这就是接下来要讲的包括红黑树和 AVL 树在内的平衡树。
#### 平衡树
平衡树,就是说一棵树的数据结构能够维护好自己的高度和形状,让形状保持平衡的同时,高度也会得到控制。平衡树的定义其实是比较粗糙的,属于一个愿景。具体实现平衡的方式就要深入具体平衡树的种类了。
红黑树被定义成:
* 一棵二叉树,每一个节点要么是红色,要么是黑色
* 根节点一定是黑色
* 红节点不能有红孩子
每条从根节点到底部的路径都经过同样数量的黑节点
看个例子,这棵红黑树的根节点值是 13,是一个黑色节点。比如红节点 8 的两个孩子是黑色节点 1 和 11,因为红节点不能有红孩子。可以看到,从根节点 13 通向 22 的路径,经过了 13 和 25 这两个黑节点;从根节点 13 通向 11 的路径,经过了 13 和 11 这两个黑节点。因为最后一个定义就是说:

满足这些定义的红黑树可以被数学证明树的高度为 O(log n)。要实现一棵红黑树是非常难的,其中有许多节点插入 / 删除需要用到旋转等操作细节,我们在这一讲中无法展开讲解,可自行查阅资料学习。
还有一种平衡树叫 B 树,B 树的每个节点可以存储多个数值,但是要求:
* 所有叶子节点的深度一样
* 非叶子节点只能存储 b - 1 到 2b - 1 个值
* 根节点最多存储 2b - 1 个值
红黑树可以被理解成 order 为 4 的一种特殊 B 树,称为 2-3-4 树,之所以称为 2-3-4 树,是因为每个有子树的节点都只可能有两个,或者 3 个,或者 4 个子节点。
类似想法的平衡树实现还有很多,比如 AVL 树,由它的发明者们的名字首字母命名,分别是 Adelson-Velsky-Landis,它的定义很简单,任意一个节点的左右子树高度最多相差 1。
由于篇幅有限,我们就不再一一展开各种平衡树的讲解了,可自行查阅资料学习。
#### Log-Structured 结构
在计算机存储数据结构的发展中,Log-Structured 结构的诞生为许多文件系统或者是数据库打下了坚实的基础。比如说,Google 的三驾马车之一,Bigtable 文件系统的底层存储数据结构采用的就是 Log-Structured 结构,还有大家所熟知的 MongoDB 和 HBase 这类的 NoSQL 数据库,它们的底层存储数据结构其实也是 Log-Structured 结构。
而 Log-Structured 结构其实和平衡树有着莫大的关系,因为在这些框架应用里面,通常都会使用平衡树来优化数据的查找速度。在这一讲中,我会先介绍什么是 Log-Structured 结构,而在下一讲中,再详细介绍平衡树数据结构是如何被应用在 Log-Structured 结构中的。
我们先来看看一个常见的问题应用。假设一个视频网站需要一个统计视频观看次数的功能,如果给你来设计的话,会采用哪种数据结构呢?你可能会觉得这并不难,我们可以运用哈希表这个数据结构,以视频的 URL 作为键、观看次数作为值,保存在哈希表里面。所有保存在哈希表里面的初始值都为 0,表示并无任何人观看,而每次有人观看了一个视频之后,就将这个视频所对应的值取出然后加 1。
刚开始的时候,这个设计思路可能运行得很好。可当用户量增大了之后,会发现在更新哈希表的时候必须要加锁,不然的话,大量的这种并行 +1 操作可能会覆盖掉各自的值。比方说,在同一时间,有两个用户都观看了一个视频,它们都根据视频的 URL 在哈希表中取出了观看次数的值 0,在更新操作 +1 了之后,都把 1 这个值保存在了哈希表中,而实际上,哈希表中的值应该是 2。
不难发现,这种操作的瓶颈其实是在更新操作,也就是写操作上。那有没有方法可以不用顾及写操作的高并发问题,同时也可以最终获得一个准确的结果呢?答案就是使用 Log-Structured 结构。
Log-Structured 结构,有时候也会被称作是 Append-only Sequence of Data,因为所有的写操作都会不停地添加进这个数据结构中,而不会更新原来已有的值,这也是 Log-Structured 结构的一大特性。
我们来看看在采用了 Log-Structured 结构之后,在上面的统计视频网站观看次数的应用中,底层的数据结构变成怎么样了。
假设现在网站总共有三个视频,URL 分别就是 A、B 和 C,那一个可能的数据结构图就如下图所示:

从上图中可以看到,这样的数据结构其实和数组非常像,数组里的值就保存着 URL 和 1,每次有新用户观看过视频之后,就会将 URL 和 1 加到数组的结尾。在上面的例子中,我们只需要遍历一遍这个数组,然后将不同的 URL 值加起来就可以得到观看的总数,例如 A 的观看总数为 8 次,B 为 3 次,C 为 5 次。
这其实就是 Log-Structured 结构的本质了,不过细心的你应该可以发现了,这样一个最基本的 Log-Structured 结构,其实在应用里会有很多的问题。比如说,一个数组不可能在内存中无限地增长下去,我们要如何处理呢?如果每次想要知道结果,就必须遍历一遍这样的数组,时间复杂度会非常高,那该怎么优化呢?平衡树是如何被应用在里面的呢?所有这些问题的答案我都会在下一讲中为你讲解。
- 前言
- 开篇
- 开篇词:从此不再“面试造火箭、工作拧螺丝”
- 模块一:数组与链表的应用
- 第 01 讲:数组内存模型
- 第 02 讲:位图数组在 Redis 中的应用
- 第 03 讲:链表基础原理
- 第 04 讲:链表在 Apache Kafka 中的应用
- 模块二:哈希表的应用
- 第 05 讲:哈希函数的本质及生成方式
- 第 06 讲:哈希函数在 GitHub 和比特币中的应用
- 第 07 讲:哈希碰撞的本质及解决方式
- 第 08 讲:哈希表在 Facebook 和 Pinterest 中的应用
- 模块三:树的应用
- 第 09 讲:树的基本原理
- 第 10 讲:树在 Amazon 中的应用
- 第 11 讲:平衡树的性能优化
- 第 12 讲:LSM 树在 Apache HBase 等存储系统中的应用
- 模块四:图的应用
- 第 13 讲:用图来表达更为复杂的数据关系
- 第 14 讲:有向无环图在 Spark 中的应用
- 第 15 讲:图的实现方式与核心算法
- 第 16 讲:图在 Uber 拼车业务中的应用
- 模块五:数据结构组合拳
- 第 17 讲:缓存数据结构在 Nginx 中的应用
- 第 18讲:高并发数据结构在 Instagram 与 Twitter 中的应用