>[success] # 栈
~~~
1.栈的应用场景一般是在编程语言的编译器和内存中保存变量、方法调用,或者是浏览器历史记录返回按钮
2.栈就像 一摞书,或者一摞盘子,在摆放这种一摞的物体的时候,我们一般都遵循,从下往上依次摆放,
从上往下依次拿出(这里排除你很厉害从中间抽取不倒)。这种存放得出一个结论'后进先出,先进后出',
这种结构就叫做'栈'
~~~
* 一摞书

>[info] ## 栈 和 数组区别
~~~
1.现在看来'栈'和'数组',感觉上栈看起来和数组很像,唯一不同的是数组没有栈那么强的约束性质(栈只能'先进后出'),
数组反而更加灵活,数组对外暴露更多的操作接口,在操作上更加灵活自由,但是在操作上自然也会容易出错。
~~~
>[danger] ##### 什么时候使用栈
~~~
1.当某个数据集合只涉及在一端插入和删除数据,并且满足后进先出、先进后出的特性,
我们就应该首选'栈'这种数据结构。
~~~
>[danger] ##### 如何实现栈
~~~
1.首先需,栈要满足'先进后出原则',因此肯定需要可以入栈 和 出栈两个操作,但是这两个操作需要作用于栈顶,
(一摞的东西我们都是从顶部操作因此在栈顶)在栈顶插入一个数据和从栈顶删除一个数据
2.这样的话如果我们把数组进行二次封装减少对外的暴露,让其只能进行栈顶的操作,这样通过数组实现的栈
叫'顺序栈',用链表实现的栈,我们叫作'链式栈'
~~~
>[info] ## 时间复杂度
~~~
1.栈因为只能对栈顶进行操作,因此它的时间复杂度O(1),但类似java这类语言一般数组大小都是固定好的,所以
当我们操作的栈大小已经超出我们要存储的内容的时候,数组需要扩容因此,时间复杂度在这个时候就会变成O(n)
,但是只有这个瞬间是O(n) 整体的平均复杂度依旧是O(1)
~~~
>[info] ## 浏览器后退栈的应用
~~~
1.当你依次访问完一串页面 a-b-c 之后,点击浏览器的后退按钮,就可以查看之前浏览过的页面 b 和 a。当你后退到页
面 a,点击前进按钮,就可以重新查看页面 b 和 c。但是,如果你后退到页面 b 后,点击了新的页面 d,那就无法再通
过前进、后退功能查看页面 c 了
~~~
>[danger] ##### 实现原理
[参考地址](https://time.geekbang.org/column/article/41222)
~~~
1.X 和 Y,我们把首次浏览的页面依次压入栈 X,当点击后退按钮时,再依次从栈 X 中出栈,
并将出栈的数据依次放入栈 Y
~~~
~~~
1.比如你顺序查看了 a,b,c 三个页面,我们就依次把 a,b,c 压入栈,这个时候,两个栈的数据就是这个样子
~~~
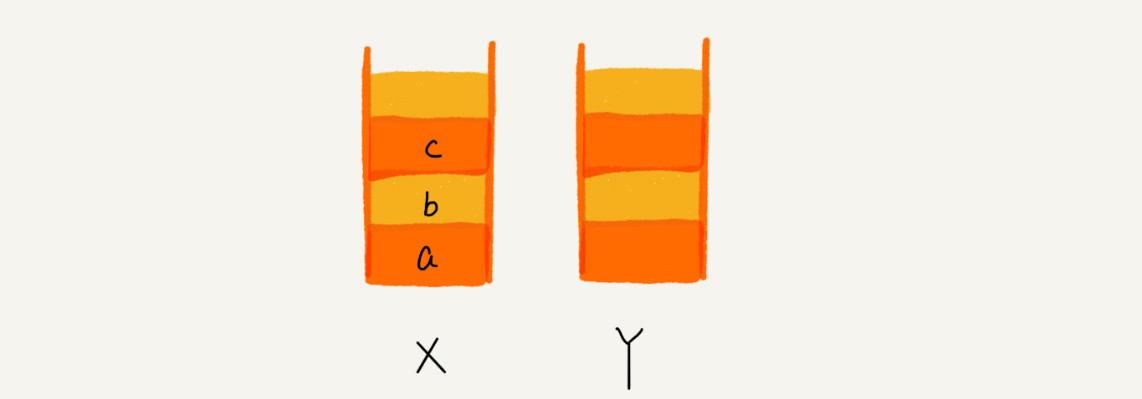
~~~
1.当你通过浏览器的后退按钮,从页面 c 后退到页面 a 之后,我们就依次把 c 和 b 从栈 X 中弹出,并且依次放入到栈
Y。这个时候,两个栈的数据就是这个样子:
~~~
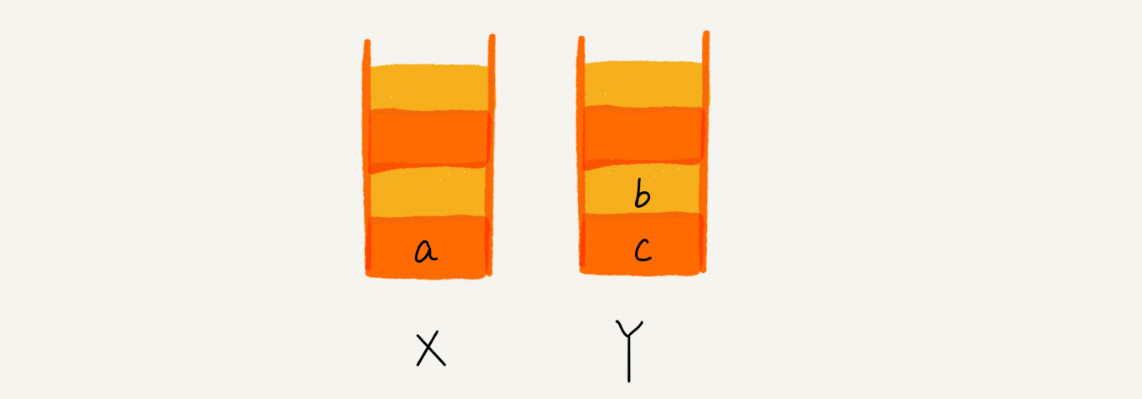
~~~
1.这个时候你又想看页面 b,于是你又点击前进按钮回到 b 页面,我们就把 b 再从栈 Y 中出栈,放入栈 X 中。此时两
个栈的数据是这个样子
~~~
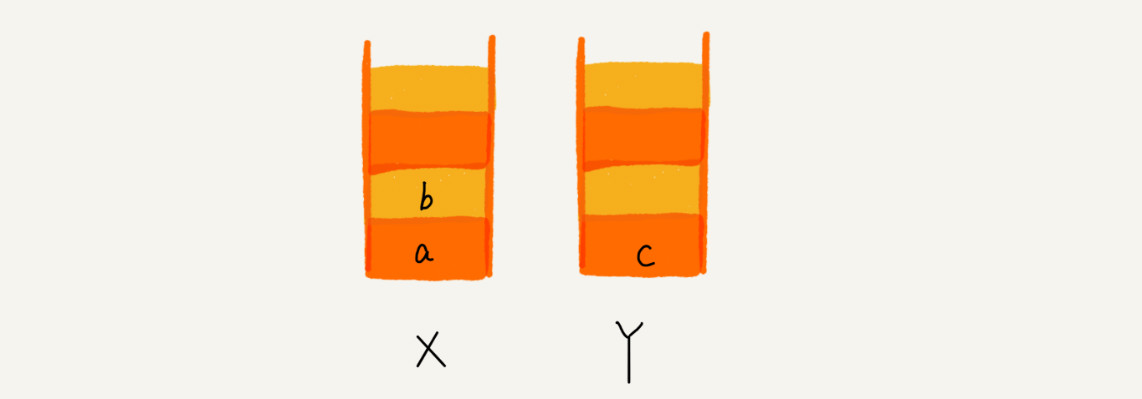
~~~
1.这个时候,你通过页面 b 又跳转到新的页面 d 了,页面 c 就无法再通过前进、后退按钮重复查看了,所以需要清空
栈 Y。此时两个栈的数据这个样子
~~~
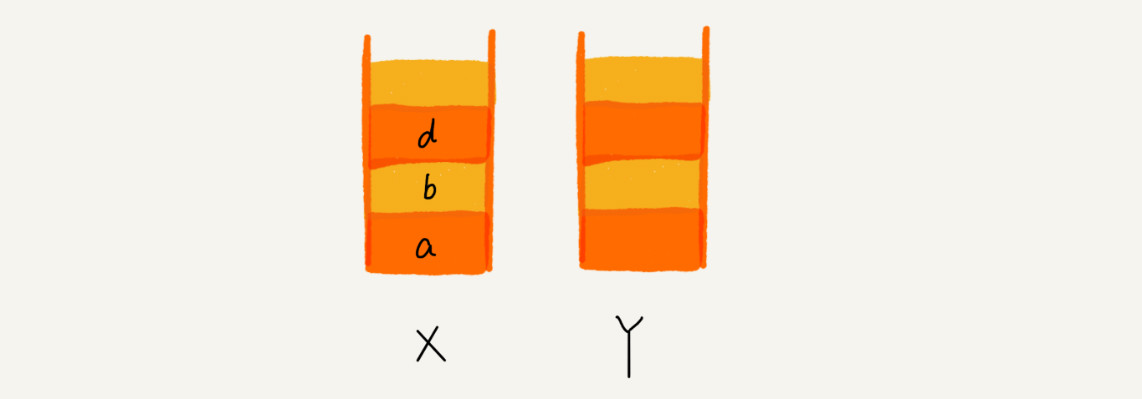
- 接触数据结构和算法
- 数据结构与算法 -- 大O复杂度表示法
- 数据结构与算法 -- 时间复杂度分析
- 最好、最坏、平均、均摊时间复杂度
- 基础数据结构和算法
- 线性表和非线性表
- 结构 -- 数组
- JS -- 数组
- 结构 -- 栈
- JS -- 栈
- JS -- 栈有效圆括号
- JS -- 汉诺塔
- 结构 -- 队列
- JS -- 队列
- JS -- 双端队列
- JS -- 循环队列
- 结构 -- 链表
- JS -- 链表
- JS -- 双向链表
- JS -- 循环链表
- JS -- 有序链表
- 结构 -- JS 字典
- 结构 -- 散列表
- 结构 -- js 散列表
- 结构 -- js分离链表
- 结构 -- js开放寻址法
- 结构 -- 递归
- 结构 -- js递归经典问题
- 结构 -- 树
- 结构 -- js 二搜索树
- 结构 -- 红黑树
- 结构 -- 堆
- 结构 -- js 堆
- 结构 -- js 堆排序
- 结构 -- 排序
- js -- 冒泡排序
- js -- 选择排序
- js -- 插入排序
- js -- 归并排序
- js -- 快速排序
- js -- 计数排序
- js -- 桶排序
- js -- 基数排序
- 结构 -- 算法
- 搜索算法
- 二分搜索
- 内插搜索
- 随机算法
- 简单
- 第一题 两数之和
- 第七题 反转整数
- 第九题 回文数
- 第十三题 罗马数字转整数
- 常见一些需求
- 把原始 list 转换成树形结构